







本文重点
本节课程我们将学习如何使用机器学习的方法来构建一个垃圾邮件分类器,邮件分为垃圾邮件和非垃圾邮件,那么这是一个二分类的问题,我们可以使用监督学习的方式,收集一些邮件,其中垃圾邮件标记y=1,非垃圾邮件标记y=0。
邮件的特征如何确定?
我们可以遍历整个数据集,然后将数据集中的所有词组合成一个字典,每个词在字典中都有唯一的索引标号,构建好字典之后,我们就可以表示邮件的特征了。
{"apple":0,"red":1,"eat":2,......}
现在有一个邮件,我们可以根据邮件中是否出现这些词进行标号,如下所示是一封邮件的特征向量,其第一个数为0,表示邮件中没有apple,第二个数为1,表示邮件中有red,第三个数为2,表示邮件中有eat等等,需要注意的是邮件的特征向量的长度一定等于字典的长度。
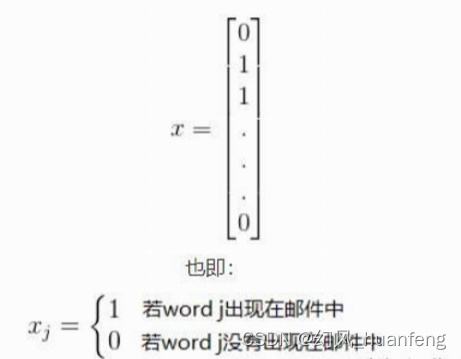
现在垃圾邮件的样本的特征已经有了,样本的标签也已经有了,那么我们就可以使用监督学习的方式训练我们的垃圾邮件的分类器了。为了让邮件分类器效果更好,我们可以使用更多的事情。
1. 我们可以尝试收集更多的邮件信息
2. 我们可以使用一些复杂的特征,比如邮件发送方的地址
4. 有些邮件为了躲避检查,可能会故意拼写错误,把手机拼写为手*机等,这样人可以读懂,但是如何让机器读懂才是关键
















 623
623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











