







本文重点
K-均值是聚类算法之一,该算法接受一个没有标签的数据集,然后将数据聚类成不同的簇。
k-均值运行原理
K-均值是一个迭代算法,假设我们想要将数据聚类成k个组,其方法为:
1.首先选择 k 个随机的点(样本点),称为聚类中心。
2.遍历数据集中的每一个数据,计算距离 K 个中心点的距离,将其与距离最近的中心点关联起来,与同一个中心点关联的所有点聚成一类。
3.计算每一个组的平均值,将该组所关联的中心点移动到平均值的位置。
重复执行2-3步,直至中心点不再变化。
下面是一个二聚类示例:
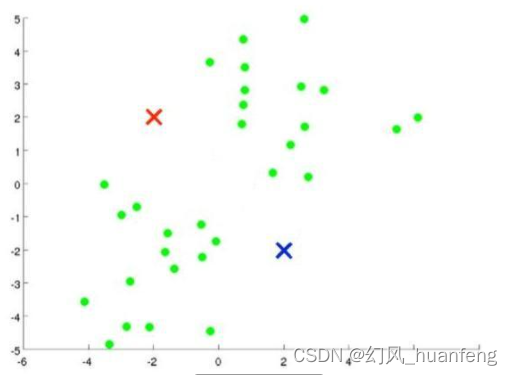
随机初始样本点
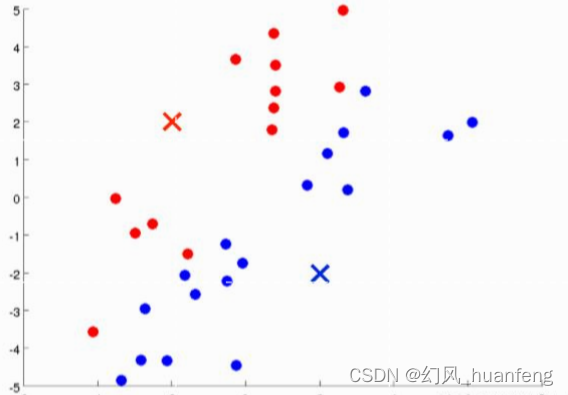
所有样本找距离最近的聚类中心
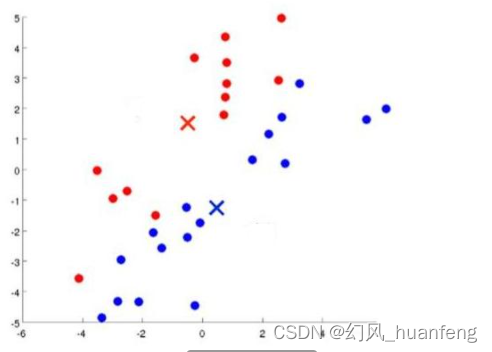
找到之后就分成了两种颜色,一种红,一种蓝,然后重新计算新的红色的聚类中心,和新的蓝色的聚类中心,继续这个过程

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











