







作者·黄崇远
『数据虫巢』
全文19476字
题图ssyer.com

“ 广告推荐的召回,没有什么是一个双塔解决不了的,如果有,那就多来几个。当然,这是戏说,但对于召回技术来说,确实是崛起于双塔,或者说双塔技术为推荐广告的召回提供了更广阔的想象空间,但实际上召回发展的路上,却不止于双塔。”
如题引,我们今天的主题包含了两层,业务视角是召回,技术视角是双塔技术的演化,而逻辑的推进是两者的有机结合,最终我们会沿着召回发展的足迹,深入去剖析基于双塔向量召回的演化,我们最终再跳出双塔召回的束缚,看召回的本质。
PS:万字长文,慎入坑。


01
召回今生前世
世界上本没有召回,然而当需要待推荐的资源多了,也就有了。
实时确实如此,召回的概念来源于推荐(包含了广告的推荐)的推送资源的筛选分层,然而分层的前提是候选资源太多,一个排序筛选的模型(通常是point-wise)实际上在用户等待的耐心范围内(耗时),不允许模型对太多资源进行转化概率的计算(或者广告中eCPM的计算)。
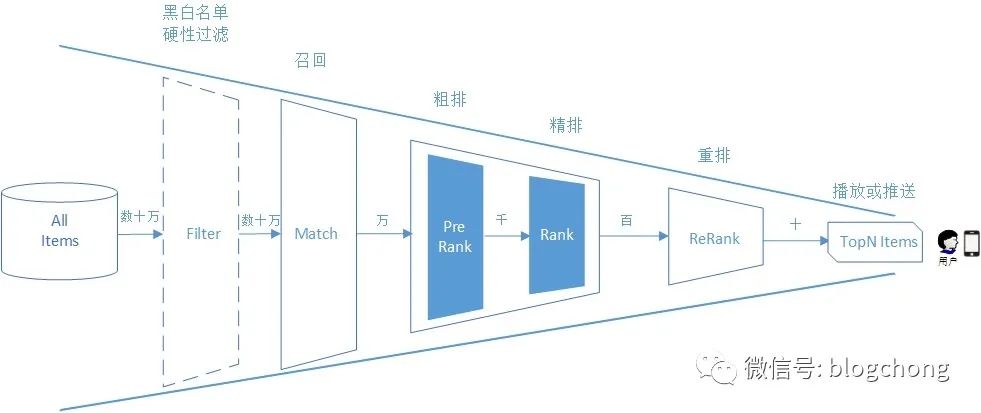
于是,就有了上图类似的层级划分,江湖人称“推荐三段式”--召回,粗排,精排。
当然,在“远古”时代,推荐系统远没有这么复杂,候选资源少意味着不需要太多的筛选,用户心思单纯,太容易转化了(相对于人肉编辑资源展示的逻辑来说),所以没有人去干这种吃力不讨好的事。
一切的一切发生在互联网信息爆炸时代,这个爆炸来自于一方面是数据的爆炸,这意味着候选资源指数级的上涨(得益于互联网/移动互联网的普及,以及分布式技术的发展),那么必然需要一种新的信息筛选模式去支持这种数量级的扩张;其次是用户体验的爆炸,或者说被轰炸,导致了用户皮糙肉厚,即内容的高度同质化,导致了用户麻木了,所以在最终推荐的候选上,或者严格说效果上,需要做的更加的深入。
所以,过去那种简单粗暴直接一个模型推荐的思路玩不转了,比如推荐领域的经典协同推荐思路,必然面临着如何高效筛选信息的演进。
于是,资源的筛选的逻辑分层是一个必然的趋势。只是说不是一下子进化成当前流行的三段式。饭是一口一口吃的。
直接的模型推荐演变成了先进行粗筛,然后再进行模型精准的预估,这就意味着粗筛层是足够高效的(整体时间有限,需要留时间给更重要的精准筛选层),且大体上是能体现效果的--不一定完全精准,但要做到大差不差。于是,天马行空的思路就出来了,比如基于历史表现来筛选,比如基于把一些新进来的作为粗筛候选,又比如给资源和人打标,通过标签来做粗筛选。其中,具有时代代表意义的就是协同模型(又见协同),不那么靠谱但又足够高效可离线化协同模型退化成了召回支持模型(协同老矣,尚能饭)。
五花八门,召回成了一个大杂烩,成了探索什么推荐新颖、候选多样的阵地,也成了产品经理显神通的法宝(各种花式召回策略嘛)。
这是一个群星闪耀的时代,也是一个群魔乱舞的时代,各种标签匹配召回、热度召回、随机召回、新候选召回、协同召回、不知名的规则召回等等--多路召回的闪耀时代。
所谓英雄起于乱世,而终结乱世,请站好,我们的主角要登场了,更准确的说是要清场了--双塔,严格来说是双塔技术支撑的向量召回的模式,终结了多路召回的混乱时代。


02
双塔,出道即巅峰
聊双塔,聊向量召回之前,我们回忆下三段式的职责,特别是召回的--需要足够的高效,且效果上要大差不差,最起码不能给人家粗筛出明显是badcase的东西出来。
带着这两个问题,我们来看什么是双塔。
关于起源论文,这里就不贴了,最早由微软提出,后续到国内大厂中又陆续衍生出很多变种变种模型,这里贴一个之前贴过的结构图,简单阐述下,为什么双塔可以解决,或者说很好的解决召回的问题。
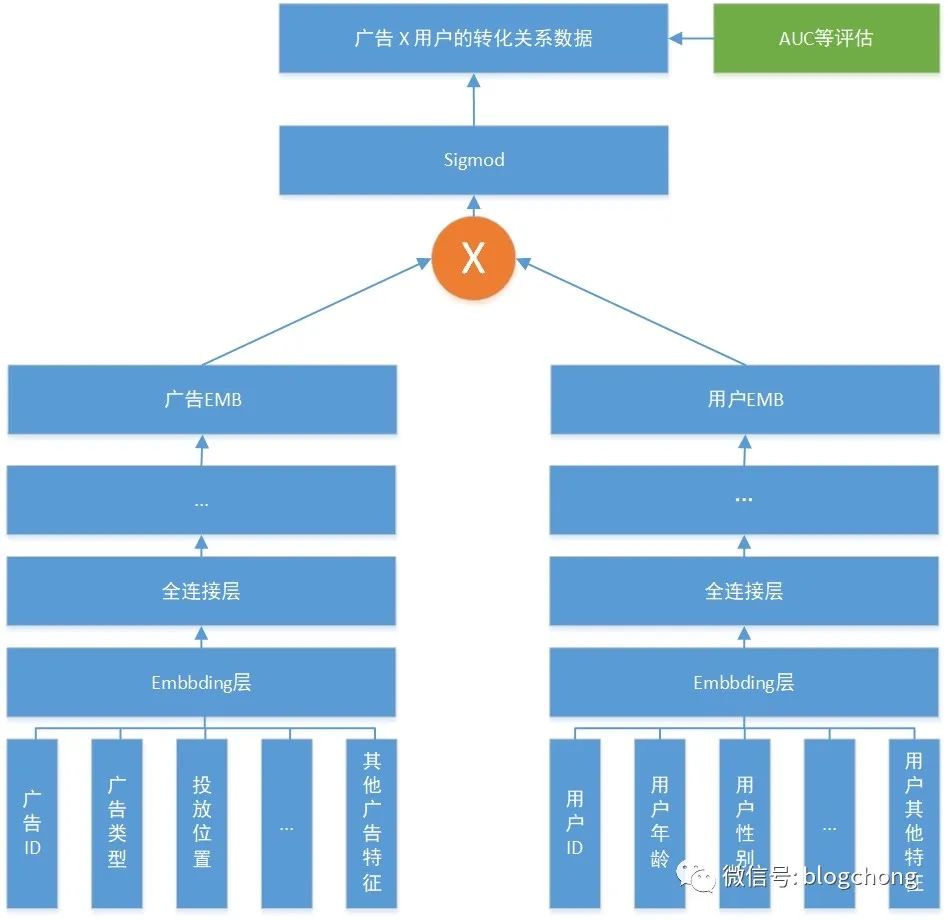
这是一个挂了广告与用户召回场景的简易结构图,一端是User,一端是Item,在这里就是广告Ad,User与Item有各自独立的网络结构,当然,这里只是贴了最简单的逻辑,特征embedding化,然后过全连接层,就直接到了各自网络的顶部,顶部各自表征的embedding进行叉乘,然后过sigmod转化为01区间。如果按梯度求解的思路观测就反过来,通过顶部的正负样本,不断地反向传播,进行梯度求解,最终拟合网络参数。
看结构就是标准的两个塔形结构,所以俗称双塔模型。这里需要注意,我们需要的东西其实并不是一个模型,而是模型稳定之后输出的两塔塔尖的表征,即最后一层全链接层分别对于User与Item的表征。
这就是涉及到了召回阶段的第一要素--高效。由于双塔的结构特点,导致了双塔各自的塔尖实际上是分别对于User与Item的表征,所以,当模型稳定之后,实际上对于单个用户的广告播放请求来说(通常,一个用户需要给他呈现广告时,我们称之为为用户播放一个广告),User是固定的,Item是一个集合,那么理论上是不是可以提前让所有的User和所有的Item的embedding都提前计算好,这样,召回的时候,实际上一个在线查表的过程,查询到对应User的embedding和Item的embedding,然后叉乘计算得分排序,然后召回TopK的资源,这样整个过程可以控制在10ms级,完全满足粗筛的性能要求。
所以,模型结构决定了双塔模型可以让推理发生在离线端,不用像预估模型那样,有多少个候选资源,就需要做多少次user*item的得分推导,导致了其可以理论计算的范围大很多。
当然,在实际操作中,并不是完全的做离线查找,因为User端显然只需要推导一次,这就意味着User端实际上可以是放到线上去的,且可以带来不少的好处。比如,新用户同样可以获得embedding的表征,以及模型可以及时的更新,这里所说的更新,比如小时级,甚至是10分钟级,让模型增量update一次,保持模型对最新数据的感知,从而不断地调优embedding。
而这种频次的更新,对于item侧来说,只需要批量更新item的离线embedding即可,大部分互联网的场景中,虽然item也可能几十万,上百万,但是对于动辄上亿、六七亿的User量级来说,这个更新成本是完全可接受的。
哪怕对于部分电商场景来说,Item资源池巨大,比如需要从几百万的Item资源库中快速检索与当前User相关的资源,目前也有不少解决方案,比如一些开源的向量检索引擎Faciss等,都能解决在线检索问题的性能,只要把在线推导问题转换为在线检索问题,效率是可以得到保证的。
至此,双塔完美地解决了召回所需要的性能问题。
回到双塔对于塔尖User和Item的表征问题,这种表征由于是通过User与Item的交互样本反向梯度求解出来的,所以表征中自然夹带了User与Item的关系。即,当User-embedding与Item-embedding叉乘的时候,自然而然的与样本的分布所趋近了,这就是所谓的对CTR有一定的拟合作用(假设正样本是点击样本的话)。
PS:关于双塔embedding表征的问题,可以看下之前的《数据与广告系列二十五:Embedding的起源与演化,以及序列构建与目标拟合派的流派之争》。
看着还是很粗糙,User与Item直到最后才发生交集,虽然用的是CTR的样本,但是这种程度的学习,能让模型很好的识别这种点击预估关系吗?理论上是不能的,特别是跟直接做点击与否预估的深度模型比,但是如果跟过去的召回逻辑相比呢?
比如标签匹配的召回。标签匹配,标准的做法是User测打标,Item测打标,然后通过标签匹配命中来进行召回。就算画像标签做的再准,还是有几个致命的问题,比如标签是对于群体的描述,颗粒度是一类,而双塔向量的召回颗粒度是User*item级别。其次是标签更新的问题,通常是比较滞后的。所以,整体而言,这是一种粗颗粒度的,且对于个性化不敏感的召回逻辑。
不过,标签召回在常规召回中无法做到的更多,但在某些特殊的场景中,比如即时兴趣召回上,结合实时的数据回流,近乎实时的给用户打标,然后在下个Action中通过标签匹配的方式,召回即时兴趣的候选,是一种较为常用的手法。这就是我们所谓,刚看到刚点击完某个东西,结果推荐系统就给你推荐XX的大体逻辑,通过即时兴趣打标的方式,然后结合实时工作流进行召回。
但这种剑走偏锋的方式毕竟无法替代核心主路逻辑,只是在某些特殊的场景中,或者作为一种补充召回方案使用,毕竟对于近实时的行为捕捉与描述不一定能够准确的描述用户的偏好,以及由于时效性的原因,这种预测方式必然无法做的更加的精细,这也就是为何大多偏向于即时打标的方式来做,而不是用复杂的深度模型。
再例如,双塔向量与协同推荐的召回相比,协同的大体逻辑见图(截自亚马逊的论文
论文《Item-Based Collaborative Filtering Recommendation Algorithms》)。
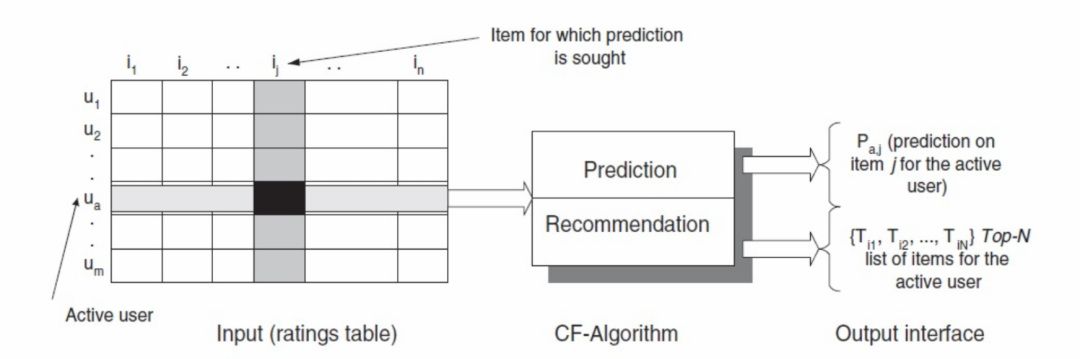
如图所示,协同模型输入是User与Item的行为数据,依赖行为构建User*Item的关系矩阵,通过矩阵的方式计算User与User的关系,或者计算Item与Item的关系,如果需要计算User与Item的关系,则依赖于当前User找到近邻的User,然后通过近邻的User的Item偏好指向,最终来给当前User推荐近邻整体偏好的Item。
说白了,这是一种相似关系计算,而相似计算的输入是User*Item的行为,并没有额外的信息输入了。哪怕是协同中相对复杂点的分解逻辑,也不过是把显式的行为矩阵计算转换为了一种中间态的数学计算,比如矩阵分解的方式中,把中间关联关系通过隐式矩阵的方式进行关系表征了,与常规User2CF,Item2CF并没有质的不同。
所以,协同的最大限制在于输入的固定,只依赖交互行为的计算存在太多的问题,比如行为关系的多寡会影响User与User,Item与Item的计算,然后行为的频繁程度会影响关系计算的是否置信,无法引入User与Item本身的特征会导致很多预测是失真的,以及无法解决新用户新Item的问题,每次引入新的批次需要整体重新计算等等。
总之,协同的模型,从推荐的远古时代一直服务到现在,从推荐模型退化到一路召回逻辑,发光发热已经尽责了,我们不能要求的更多,放过他吧。
如上来看,基于双塔模型结构的召回,完美的解决了召回阶段所要求的高性能,哪怕是从几十万上百万的候选中快速进行召回;也解决的了效果问题,先不说效果到底有多好,但与我们传统的标签匹配,协同,以及基于逻辑规则的一些召回相比,向量召回的建模逻辑决定了他的起点远高于过去的那些召回方式,意味着哪怕是按着流程简单建模,其效果也会得到明显的提升。
双塔模型的准入门槛也低,两个基本的深度网络结构,过几道全链接层,搁一个刚毕业的计算机学生都会。所以,其准入门槛是非常低的,当然不是说个大厂实际用的就是这么简单,而是说这事的基本门槛不高,在低投入下能带来高回报,ROI比较高。
因此,基于双塔的向量召回从此一统江湖,成为召回领域的绝对扛把子--不是说其他召回自此消失不见了,而是说作为召回的主要逻辑,或者说主路召回方式,基于双塔的向量召回成为了一个必选项。
但是随着向量召回的一统江湖,其迭代增长的曲线是平缓的,远不如精排预估的模型演化来的轰轰烈烈,整体而言不温不火。
给人一种出道即巅峰的感觉。
基于双塔的向量召回,之所以能成为当前潮流的主路召回,核心在于其双塔的网络结构,使得其可以进行User在线部署与Item端离线部署,从而获得在万军之中取上将首级的能力(海量候选中召回候选资源)。
但因为要保证User与Item各自表征的纯粹性,导致了双塔必然无法进行交叉,从而让两端只能输入各自的行为与特征,这对于预估的精准来说是致命的。
你不能绕开双塔的塔形结构,一旦绕开了就不是双塔了,最核心的是无法做高效推理了;如果不绕开,那么就很难解决进一步的效果问题。
这似乎是一个死结,我们来看前行者们如何解决这些问题。


03
不止于双塔
基于双塔模型结构的向量召回,得益于其双塔分离的顶部e
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









