







kaggle手写数字识别
数据下载
数据的量很多,我们对于数据的处理可以使用主成分分析法(PCA)对数据进行降维。
import pandas as pd
from random import shuffle
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
datafile ='train.csv'
data = pd.read_csv(datafile)
data = data.as_matrix()
shuffle(data)
labels=data[:,40]
data=data[:,:40]
pca=PCA(n_components=20)
data=pca.fit_transform(data)
x_train,x_test,y_train,y_test=train_test_split(x,y,train_size=0.75,random_state=1)
data_test=pd.read_csv("test.csv")
data_test= data_test.as_matrix()
pca=PCA(n_components=20)
data_test=pca.fit_transform(data)
一、支持向量机(SVM)
SVM的核心将数据的特征投射到高维,然后找到超平面,分割不同类别的数据点,而且要使分离的程度越大越好,至于为什么叫支持向量机,是因为每个类别都会有一些数据点作为支撑向量,这些支撑向量决定了最后分割的超平面。
liner 线性核函数:u’v (默认)
poly 多项式核函数:(gamma*u’*v + coef0)^degree
rbf 高斯核函数:exp(-gamma|u-v|^2)
#-*-coding: utf- -*-
from sklearn import svm #导入SVC模型
from sklearn.metrics import accuracy_score
model = svm.SVC(kernel='rbf',probability=True)
model=model.fit(x_train,y_train)
predict=model.predict(x_test)
print(accuracy_score(y_test,predict))
print(predict)
result=model.predict(data_test)
pd.DataFrame(result).to_csv("result.csv")
使用SVM的运行的效率很高且二元分类表现最好,但是对于多分类,SVM的效率普遍偏低,在这样的预测精确度只有0.4362
二、随机森林
sklearn随机森林是基于多棵决策树进行投票结果来进行分类判断
from sklearn.ensemble import RandomForestClassifier as RFC
model=RFC(n_estimators=85,criterion='entropy', max_depth=15)
model.fit(x_train,y_train)
predict=model.predict(x_test)
print(accuracy_score(y_test,predict))
print(predict)
result=model.predict(data_test)
pd.DataFrame(result).to_csv("result.csv")
在基于随机森林进行检验时,发现随机森林受数据的变动影响比较大,无法稳定,再有随机森林容易出现过拟合的现象,在手写数据识别中预测的精确度只有0.5246
三、BP神经网络
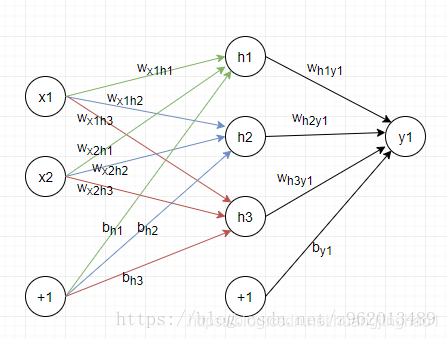
from keras.models import Sequential
from keras.layers.core import Dense,Activation
from keras.utils import to_categorical
y_train=to_categorical(y_train)#对标签进行向量化
y_test=to_categorical(y_test)#对标签进行向量化
netfile ='net.model'
net = Sequential()
net.add(Dense(input_dim =40,units =60))
net.add(Activation('relu'))
net.add(Dense(input_dim =60,units=5))
net.add(Activation('softmax'))
#二分类有sigmoid
net.compile(loss='binary_crossentropy',optimizer='adam')
net.fit(x_train,y_train,epochs=1000,batch_size=1,verbose=0)
net.save_weights(netfile)
print(net.evaluate(x_test,y_test,verbose=0))
#predict_result = net.predict_classes(x_train[:50,:])
result=model.predict(data_test)
pd.DataFrame(result).to_csv("result.csv")
使用神经网络相比较于其他的方法的优势在于,神经网络可以自主提取数据的特征学习,相比较于传统的机器学习算法,神经网络更适合于数据量大的处理,但是其“黑箱”性质让人很难知道其里面的实现过程,通过神经网络的1000次迭代学习,我们可以获得分类精确度为0.8563,但是所需要的时间很长。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









