







charcnn 顾名思义,对于一段文本来说,我们以字符作为最小单位,而不是词语了。对于中文来说,我的名字叫做推推,那么到字符级别的话,该句子的构成为[我,的,名,字,叫,做,推,推] ,而不是 [我的,名字,叫做,推推]
1.字符的量化
- 对于英文来说,常见的包括26个英文字母,10个阿拉伯数字,还有33个标点符号,不在这69个字符的统一用1个表示
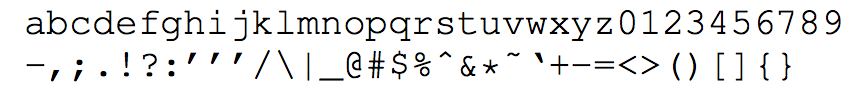
- 对于每个字符来说,可以用one-hot表示,长度为m,一段文本,由h个字符构成,那么就形成了 h*m 的矩阵
- 接下去就丢给CNN来操作了

- paper中提到一段文本提取1014个字符,就可以捕获大部分文本的含义了
2.模型结构
卷积层

- 池化层N/A表示缺省
- 初始化权重是从gaussian 分布中抽取,均值为0,在第一个Large model中采用0.02的标准差,第二个Small model中采用0.05的标准差
全连接层

- 第9层 根据自己的分类任务自行设定
- 在7,8两个全连接层,用了dropout,p=0.5
3.用同义词词典做数据增强
- 数据增强一般用于控制泛化误差,在图像或者语音识别领域,一般是用循转来做,但在文本领域是不行的,因为文本是有序的,所以考虑同义词
- 提到两个概率,一个词被替换的概率 和 一个词有多个同义词,选择哪个同义词的概率。
4.一些讨论:
- 最后一点印象最深刻,叫做天下没有免费的午餐,没有一个单独的机器学习模型对任何数据集是有效的!
- CharCNN,不需要words,适用于不同语言
- 传统的模型,像n-grams TFIDF 在 成百上千数据集中效果比价好,当数据集达到数百万级别,CharCNN会开始表现更好
- 对于用户产生的数据,例如评论,charcnn 比 以word为基础的深度神经网络 表现的更好
- 在百万级别的数据集中,不区分大小写表现的更好,一个猜测是有正则化的效果,但没有被验证过
- 在情感分析人物中,各种模型区别不大
-
Bag-of-means , 效果不理想,word2vec的表示可能对分类没有带来更好的好处
refer:https://arxiv.org/pdf/1509.01626.pdf
https://github.com/srviest/char-cnn-text-classification-pytorch















 2635
2635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









