






 3. 从New Project 中选择Maven project,下一步
3. 从New Project 中选择Maven project,下一步

4. 在 New Maven Project视图中,点击下一步

5. 选择t “maven-archtype-quicktype” 作为 project archtype 点击下一步

6.输入合适的 Group Id, Artifact Id, Version 和Package name 点击Finish

7. 以上将创建一个Maven 工程,其工程结构视图如下,并包含自动生成的以下文件 App.java 以及相对应的AppTest.java 文件 AppTest.java 包含了 junit 测试代码. 同时产生一个 pom.xml. 文件。

8. 双击 pom.xml 文件,打开编辑器 POM editor.


10. 加入 cloudera repository信息到pom.xml. 我们需要一些重要的依赖 (比如 pig, pigunit 和hadoop). 这些依赖都存在于 maven artifacts 的 cloudera’s maven 库中.
 by
by

11. 添加依赖,比如pig, pigunit, hadoop 和一些其他的比如 antlr, jackson等。我们将在eclipse中调试pig。 因而我们需要pig 和 pigunit. 由于pig 需要hadoop-core 才能运行, 我们因而又需要添加hadoop-core的依赖
(注意:这些依赖的版本,需要按照自己的版本来配置。如果使用CDH对应的pig,hadoop。可以参考)

12. 由于调试的时候需要 源代码 和 javadoc 。为了下载这些源代码和javadoc文件需要设置 Window > Preferences > Maven.

13. 勾选 Download Artifact Sources 和Download Artifact JavaDoc.点击 Apply 和 OK.

14. 右键main 文件夹(注意图中哪个main) 然后在该目录下创建一个新目录

15. 新目录命名为 resources.

16. 在 resources 文件夹中手动创建两个文件,分别为wordcount.pig 和sample.data. 在wordcount.pig 文件中我们会写入pig代码,该代码会统计文件sample.data中的词频.

17. 将以下数据加入到sample.data。

18. 将以下代码加入wordcount.pig。

19. 现在加入 pig unit 测试用例来测试和调试 twordcount.pig.
20. 编辑 AppTest.java 文件

21. 打开AppTest.java 文件,移除所有方法代码 ,然后添加A testWordCountScript方法,如下

22. 设置 大一点的内存,以便运行pig脚本测试
23. 选择 AppTest.java 文件,然后 菜单中 Run > Run Configurations …
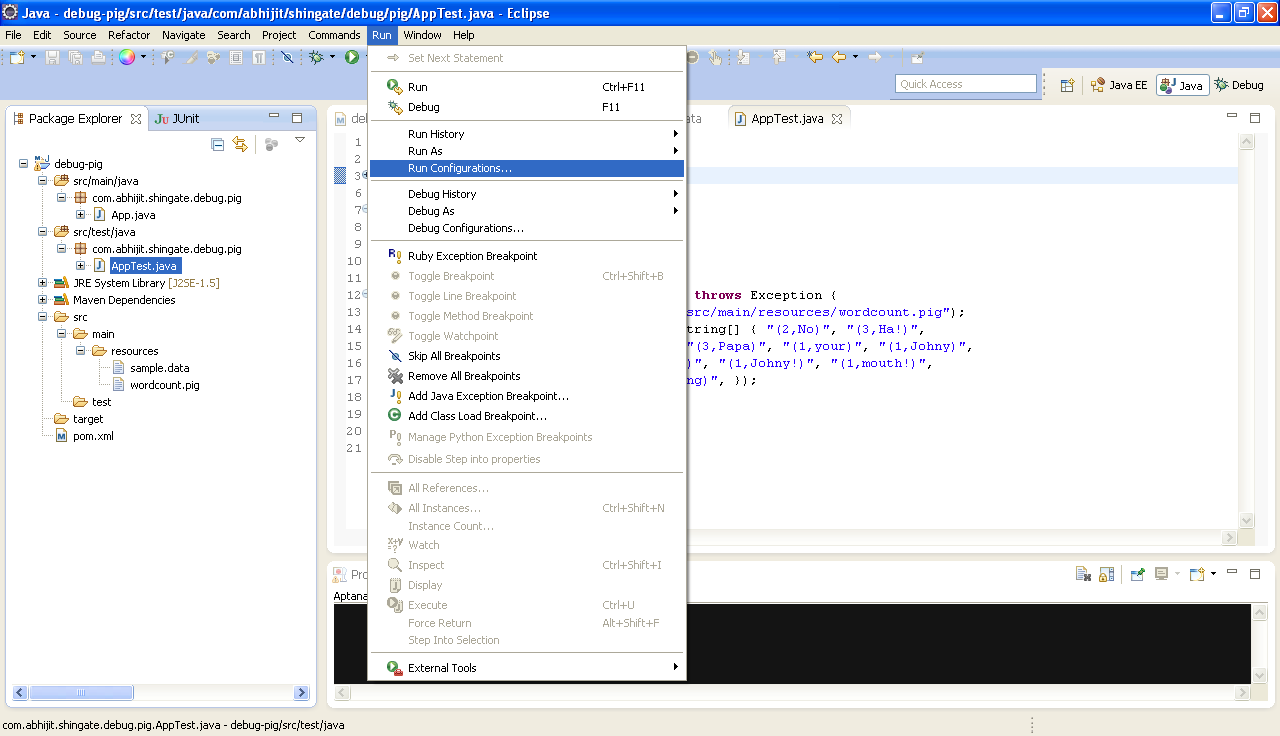
24. 在 Run Configurations 视图中双击 JUnit 来给AppTest创建一个 Run Configuration

25. 调整VM 参数 添加 “-Xmx1024m” 设置 JVM 到 1Gb.

26. 在此选择 AppTest.java文件. Run > Debug Configurations …

27. 选择AppTest并点击Debug

28. 测试用例应当执行成功,然后会看到绿色的进度条(下图在左上角,我的在eclipse 底部)

29. 假若你想调试 pig 内置的 COUNT UDF ,使用快捷键Ctrl+Shift+T 来打开一个类,在打开的 Open Type 视图框中输入COUNT 将会显示所有package org.apache.pig.builtin包下与COUNT相关的类. 选择下图中的 COUNT类。

30. 由于我们让项目添加了 jar的源代码,因而 COUNT UDF的源代码就出现了

31. 由于COUNT 是一个聚合类的UDF, 它包含了初始化、中间态、和最终状态的实现。我们只需要将调试断点 添加到包含了这三个状态的执行函数。

32. 再次选择AppTest.java,菜单 Run > Debug Configurations …
33. 选择 AppTest 并点击 Debug
34. 将会出现对话框 “Confirm Perspective Switch” .点击Yes

35. 然后你就可以看到这些在编辑器中激活的断点了。现在使用 eclipse的debug,你就可以调试完整的COUNT UDF代码了。

--------------------------------------------------------------分割线-(下文是我自己的测试结果)------------------------------------------------------
三 我的安装测试
1 以下是其中的 pom.xml文件。读者可以按照自己的版本对应填写
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>pig.xiatao</groupId>
<artifactId>pig_envirnoment</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>pig_envirnoment</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>2.5.0-mr1-cdh5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.pig</groupId>
<artifactId>pigunit</artifactId>
<version>0.12.0-cdh5.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.pig</groupId>
<artifactId>pig</artifactId>
<version>0.12.0-cdh5.2.0</version>
</dependency>
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr</artifactId>
<version>3.5</version>
</dependency>
<dependency>
<groupId>org.codehaus.jackson</groupId>
<artifactId>jackson-mapper-asl</artifactId>
<version>1.9.13</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.7</version>
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency>
</dependencies>
<repositories>
<repository>
<id>cloudera-releases</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
</project>


2 运行结果界面如下
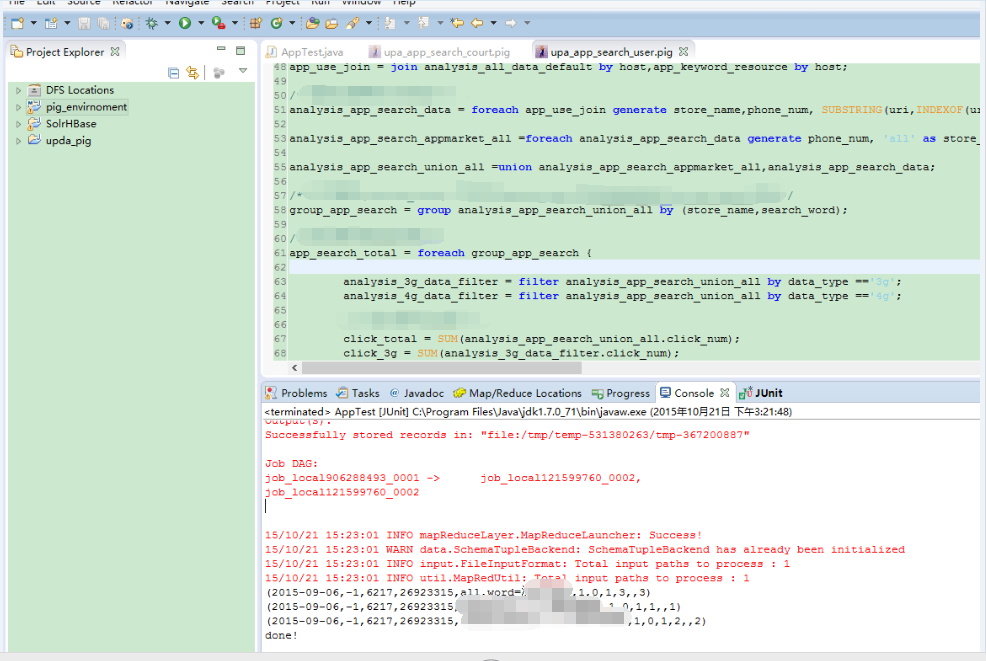
上图给看到的是 upa_app_search_use.pig这个脚本的运行结果。其实际是在 AppTest.java这个类中执行的

其中的PigTest 这个类需要 import倒入。
注意:pig脚本中的参数最好直接写在 脚本里,通过后面传入参数好像不行。















 3508
3508












 到【灌水乐园】发言
到【灌水乐园】发言








