







目录
1.Failed to load the model Exit code: 18446744072635812000
三,LM Studio运行Deepseek模型
3.1 加载模型
在models下创建Publisher\Repository目录,并将下载的模型放到该目录下。(注意!一定要在选定的目录下创建Publisher\Repository,否则本地模型不会被加载。)如下:





3.2 使用模型
如上节所示,我们加载完模型,就可以在本地使用模型,而无需联网了,如下:
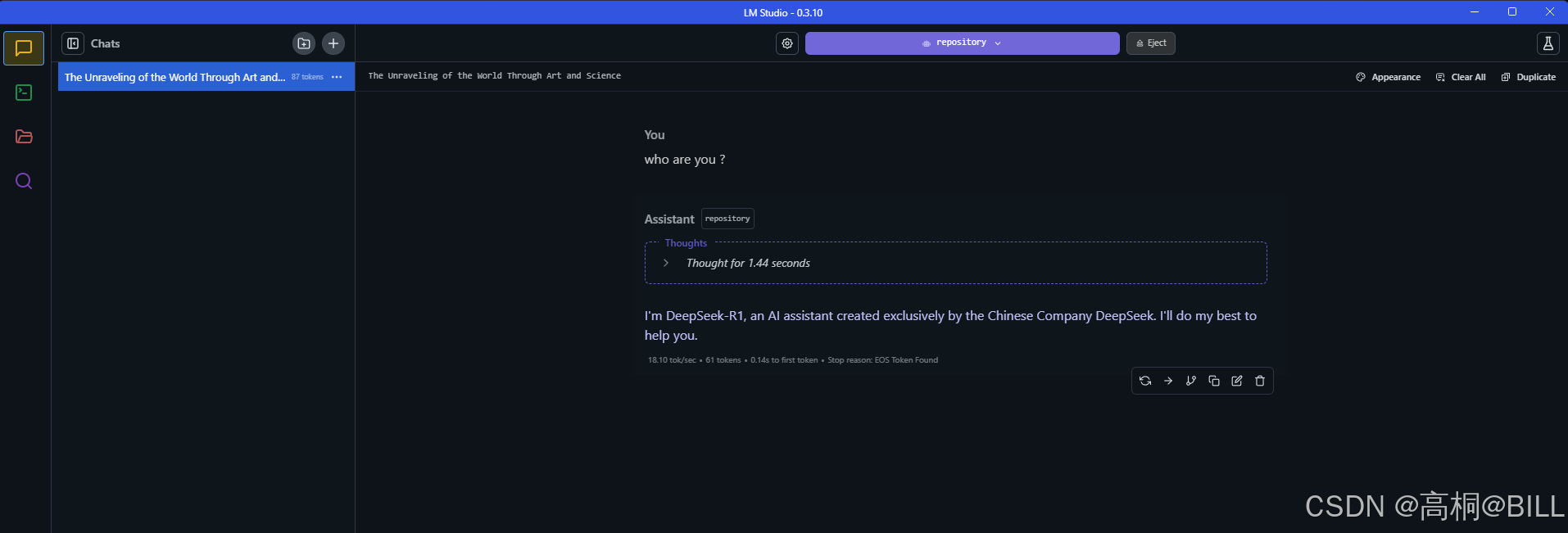
FAQ
1.Failed to load the model Exit code: 18446744072635812000
问题描述:

```
🥲 Failed to load the model
Error loading model.
(Exit code: 18446744072635812000). Unknown error. Try a different model and/or config.
解决方案:
选择不同的runtime,如下我通过选择了CPU llama.cpp (Windows)解决该问题,可以根据自己的硬件配置来选择不同的runtime。




















 1040
1040

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











