







 本文深入探讨MXNet深度学习框架,解析其系统架构和执行引擎的核心组件。MXNet定位为高效灵活的深度学习工具,支持设备安置、多GPU训练和自动优化。系统模块包括存储分配、运行时依赖引擎和资源管理,用户模块涉及KVStore、数据加载、NDArray、符号执行和构造。执行引擎通过运行时依赖调度加速计算,解决跨设备并行计算的同步问题,提供异步Push API和变量依赖管理,优化内存调用和对象创建成本。
本文深入探讨MXNet深度学习框架,解析其系统架构和执行引擎的核心组件。MXNet定位为高效灵活的深度学习工具,支持设备安置、多GPU训练和自动优化。系统模块包括存储分配、运行时依赖引擎和资源管理,用户模块涉及KVStore、数据加载、NDArray、符号执行和构造。执行引擎通过运行时依赖调度加速计算,解决跨设备并行计算的同步问题,提供异步Push API和变量依赖管理,优化内存调用和对象创建成本。
目的:把握深度学习的前沿趋势和核心技术壁垒,思考最合适的业务方向,探索商业模式。
步骤:了解核心技术,从可商业化平台入手探索。
起始:MXNet,Tensorflow,Caffe入手,从已有的商业化平台倒拖;比如AWS,Aliyun等对比.
一、MXNet 系统架构
定位:高效和灵活的深度学习框架 http://mxnet.io/index.html
能力:设备安置、多GPU训练、自动演进、最优化预定义层
特性:1.利用NDArray的命令式编程 2.支持符号编程
核心架构:http://mxnet.io/architecture/index.html
架构设计核心:抽象、最优化、在灵活性和效率之间的平衡
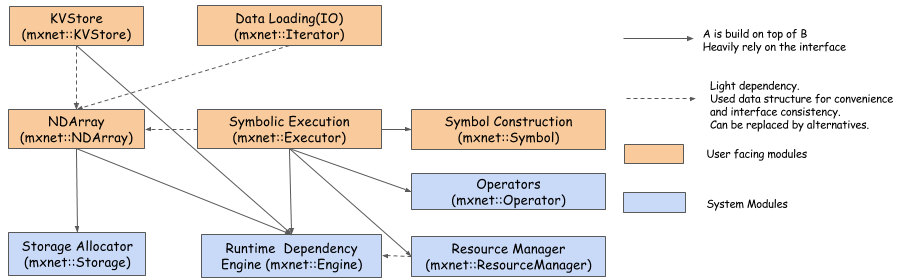
从架构上分为两层:系统模块、用户模块
系统模块:存储分配(CPU/GPU)、运行时依赖引擎(调度并执行符号)、资源管理(管理全局资源,随机数生成器、)、操作符(定义静态的前向梯度计算BP)
用户模块:KVStore(支持有效的参数同步)、数据加载(有效的分布式数据加载和扩散)、NDArray(动态、异步N维数组,支持命令式编程)、符号执行(静态符号图执行器)、符号构造(构造一个计算图)
二、MXNet系统组件之执行引擎
问题:深度学习库,需要针对大数据集更快更加扩展的运行,除了通过更加的硬件来解决该问题,并依赖更多的GPU同时执行。
设计:如何跨越设备并行计算,当引入了多线程后如何同步计算;运行时依赖引擎【解决方案】
核心:通过运行时依赖调度来加速深度学习。
接口(Interface)
执行引擎的核心接口
函数(Function)
执行引擎的函数类型
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1795
1795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









