






华子目录
引入
我们先来看一道题:
如果 a+b+c=1000,且 a^2+b^2=c^2(a,b,c 为自然数),如何求出所有a、b、c可能的组合?
第一次尝试
- 使用
三重循环
import time
start_time = time.time() #记录开始的时间戳(单位:秒)
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a + b + c == 1000 and a * a + b * b == c * c:
print(f"组合:{a} {b} {c}")
end_time = time.time() #记录结束的时间戳(单位:秒)
print(f"运行总时间:{end_time-start_time}")
- 运行结果

第二次尝试
- 使用
二重循环
import time
start_time = time.time()
for a in range(0,1001):
for b in range(0,1001):
c = 1000-a-b
if a*a + b*b==c*c:
print(f"组合:{a} {b} {c}")
end_time = time.time()
print(f"运行时间:{end_time-start_time}")
- 运行结果
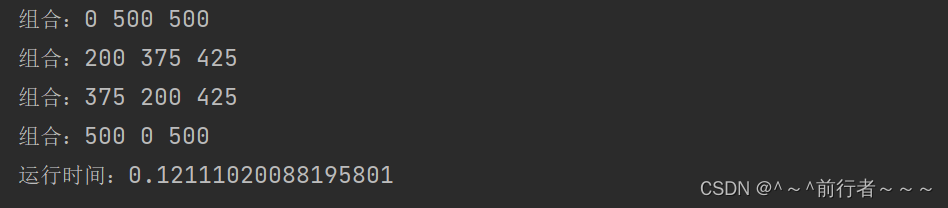
- 我们可以很清楚的看到:第二次的执行效率更好
算法的概念
算法是计算机处理信息的本质,因为计算机程序本质上是一个算法来告诉计算机确切的步骤来执行一个指定的任务。一般地,当算法在处理信息时,会从输入设备或数据的存储地址读取数据,把结果写入输出设备或某个存储地址供以后再调用。- 对于算法而言,
实现的语言并不重要,重要的是思想。
算法的五大特性
输入:算法具有0个或多个输入输出: 算法至少有1个或多个输出有穷性: 算法在有限的步骤之后会自动结束而不会无限循环,并且每一个步骤可以在可接受的时间内完成确定性:算法中的每一步都有确定的含义,不会出现二义性可行性:算法的每一步都是可行的,也就是说每一步都能够执行有限的次数完成
算法效率衡量
执行时间
- 对于
同一问题,我们给出了两种解决算法,在两种算法的实现中,我们对程序执行的时间进行了测算,发现两段程序执行的时间相差悬殊(52秒相比于0.12秒),由此我们可以得出结论:实现算法程序的执行时间可以反应出算法的效率,即算法的优劣。
单靠时间值绝对可信吗?
- 假设我们将
第二次尝试的算法程序运行在一台配置古老性能低下的计算机中,情况会如何?很可能运行的时间并不会比在我们的电脑中运行算法一的52秒快多少。 - 单纯依靠
运行的时间来比较算法的优劣并不一定是客观准确的! 程序的运行离不开计算机环境(包括硬件和操作系统),这些客观原因会影响程序运行的速度并反应在程序的执行时间上。那么如何才能客观的评判一个算法的优劣呢?
时间复杂度与 “大O记法”
- 对于算法的
时间效率,我们可以用“大O记法”来表示。 “大O记法”:对于单调的整数函数f,如果存在一个整数函数g和实常数c>0,使得对于充分大的n总有f(n)<=c*g(n),就说函数g是f的一个渐近函数(忽略常数),记为f(n)=O(g(n))。也就是说,在趋向无穷的极限意义下,函数f的增长速度受到函数g的约束,亦即函数f与函数g的特征相似。时间复杂度:假设存在函数g,使得算法A处理规模为n的问题示例所用时间为T(n)=O(g(n)),则称O(g(n))为算法A的渐近时间复杂度,简称时间复杂度,记为T(n)
如何理解 “大O记法”
- 对于
算法进行特别具体的细致分析虽然很好,但在实践中的实际价值有限。对于算法的时间性质和空间性质,最重要的是其数量级和趋势,这些是分析算法效率的主要部分。而计量算法基本操作数量的规模函数中那些常量因子可以忽略不计。例如,可以认为3n2 和 100n2 属于同一个量级,如果两个算法处理同样规模实例的代价分别为这两个函数,就认为它们的效率“差不多”,都为 n2 级。
最坏时间复杂度
- 分析算法时,存在几种可能的考虑:
- 算法完成工作
最少需要多少基本操作,即最优时间复杂度 - 算法完成工作
最多需要多少基本操作,即最坏时间复杂度 - 算法完成工作
平均需要多少基本操作,即平均时间复杂度
- 算法完成工作
- 对于
最坏时间复杂度,提供了一种保证,表明算法在此种程度的基本操作中一定能完成工作。 - 我们主要关注算法的
最坏情况,亦即最坏时间复杂度。
时间复杂度的几条基本计算规则
基本操作,即只有常数项,认为其时间复杂度为O(1)顺序结构,时间复杂度按加法进行计算循环结构,时间复杂度按乘法进行计算分支结构,时间复杂度取最大值- 判断一个
算法的效率时,往往只需要关注操作数量的最高次项,其它次要项和常数项可以忽略 - 在
没有特殊说明时,我们所分析的算法的时间复杂度都是指最坏时间复杂度
算法分析
- 第一次尝试的算法核心部分
for a in range(0, 1001):
for b in range(0, 1001):
for c in range(0, 1001):
if a + b + c == 1000 and a * a + b * b == c * c:
print(f"组合:{a} {b} {c}")
-
时间复杂度:T(n) = O(n*n*n) = O(n3) -
第二次尝试的算法核心部分
for a in range(0,1001):
for b in range(0,1001):
c = 1000-a-b
if a*a + b*b==c*c:
print(f"组合:{a} {b} {c}")
时间复杂度:T(n) = O(n*n*(1+1)) = O(n*n) = O(n2)- 由此可见,我们尝试的
第二种算法要比第一种算法的时间复杂度好多的。
常见的时间复杂度
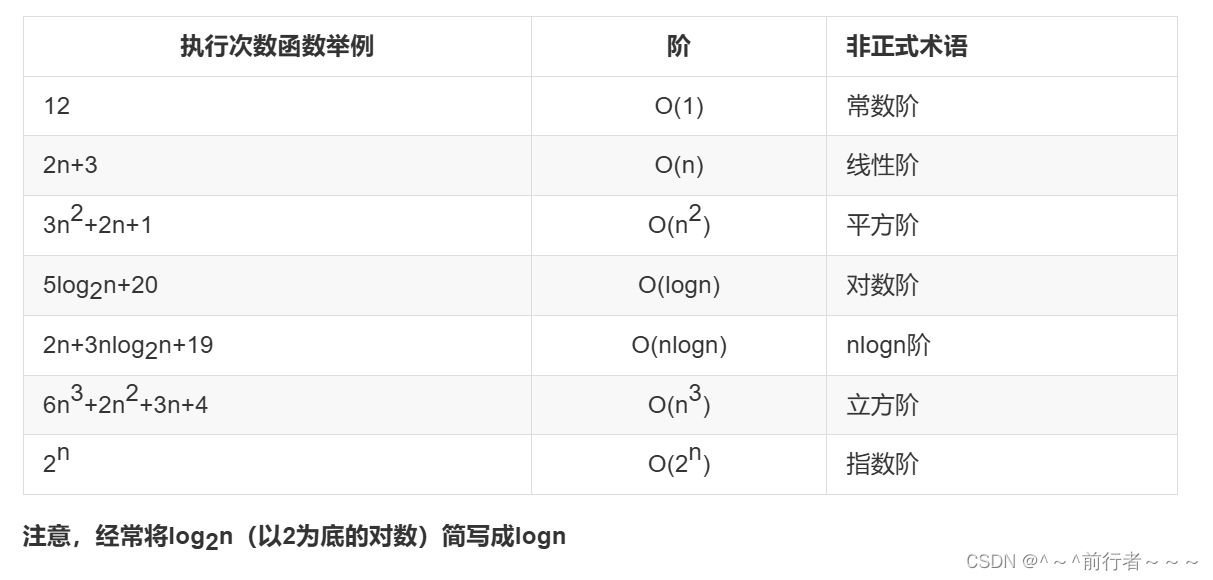
常见时间复杂度之间的关系
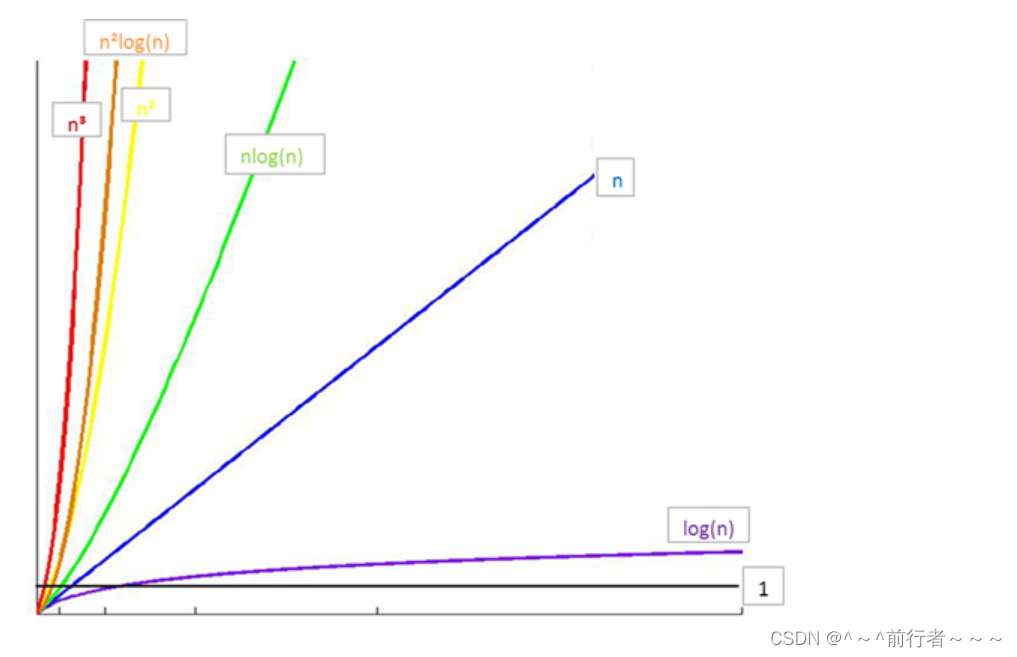
- 所消耗时间
从小到大

数据结构与算法的关系
程序 = 数据结构 + 算法总结:算法是为了解决实际问题而设计的,数据结构是算法需要处理的问题载体
常见的数据运算
- 插入
- 删除
- 修改
- 查找
- 排序
leetcode简单题-两数之和

class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
hashmap={} #使用字典记录已经遍历过的值(值为键,下标为字典的值)
for i,v1 in enumerate(nums): #enumerate会返回下标和值
v2 = target-v1
if v2 in hashmap: #如果目标值减去当前元素的差值在字典中存在
return [hashmap[v2],i]
hashmap[v1] = i #将当前元素存入字典中,key为元素值,value为索引
return []
leetcode简单题-回文数

class Solution:
def isPalindrome(self, x: int) -> bool:
return str(x) == str(x)[::-1]
leetcode简单题-最长公共前缀

法一:纵向法
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if not strs:
return ""
length,count = len(strs[0]),len(strs)
for i in range(length):
c=strs[0][i] #记录第一个字符串的第i个字符
for j in range(1,count): #比较第二个(包括第二个)字符串之后的字符串
if i==len(strs[j]) or strs[j][i]!=c: #i=len(strs[j])是为了防止内存溢出
return strs[0][:i]
return strs[0]
法二:横向法
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if not strs:
return ""
prefix, count = strs[0], len(strs)
for i in range(1,count):
prefix = self.lcp(prefix, strs[i])
if not prefix:
break
return prefix #返回公共前缀
def lcp(self, str1,str2): #返回每次比较的公共前缀
length,index = min(len(str1),len(str2)),0
while index < length and str1[index] == str2[index]:
index +=1
return str1[:index]
















 3597
3597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











