






 提出一种基于课程元学习的城市间迁移下一个兴趣点(POI)推荐方法CHAML,旨在解决数据稀疏和冷启动城市的问题。该方法通过硬意识元学习和城市级课程学习增强模型迁移能力。
提出一种基于课程元学习的城市间迁移下一个兴趣点(POI)推荐方法CHAML,旨在解决数据稀疏和冷启动城市的问题。该方法通过硬意识元学习和城市级课程学习增强模型迁移能力。
论文背景
Curriculum Meta-Learning for Next POI Recommendation
基于课程元学习的下一个兴趣点推荐
KDD 21
PDF
现有问题
在下一个兴趣点推荐的研究中,在有限的用户-兴趣点交互数据下,在冷启动城市中提供满意的推荐是重要问题,这需要许多其它城市丰富数据下隐含的知识进行迁移。现有文献没有考虑到城市转移的问题或者不能同时处理数据稀疏和用户在多个城市的模式多样性的问题。
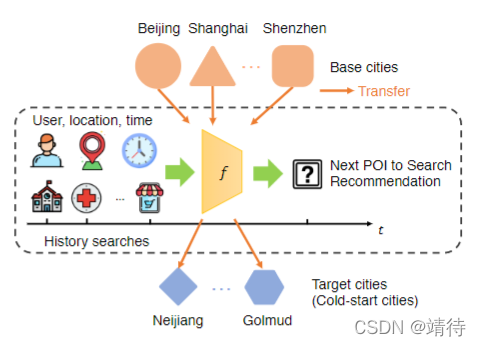
问题描述如图所示。
该问题关键是提出一个合适的迁移算法,但难点有二:
1. 不同城市的数据太少
2. 用户在不同城市下有不同的多样性表达
现有算法不能同时解决这两个问题。传统的预训练和微调技术不能解决问题2,跨域推荐不能解决问题1。
架构
提出 Curriculum Hardness Aware Meta-Learning (CHAML) 框架。
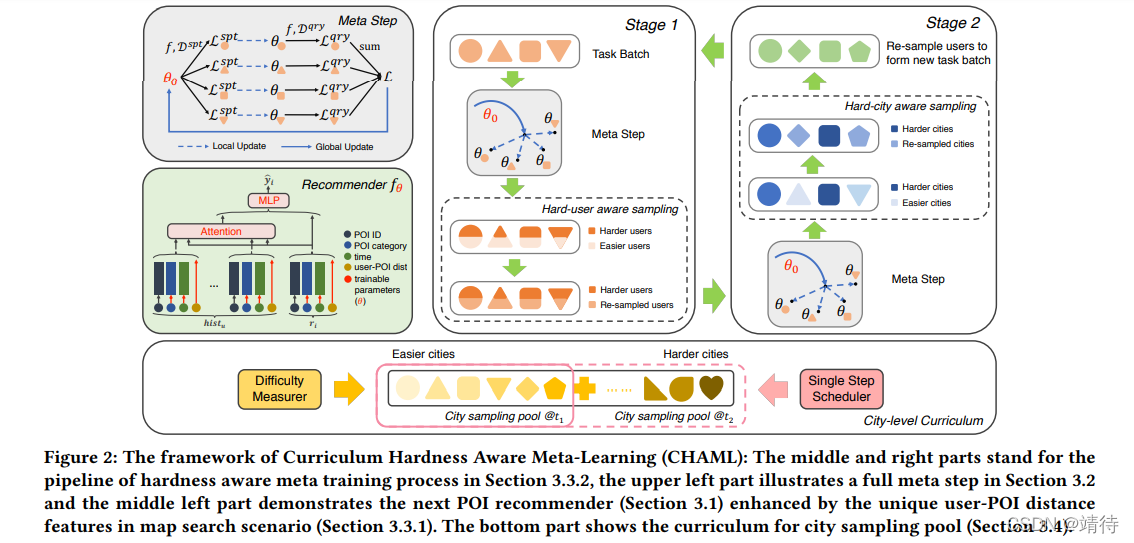
架构分为两部分,一部分是基础推荐器,另一部分是MAML扩展。后者用于将元学习引入到POI推荐中。
两种采用策略组件,一种是硬意识元学习(hardness aware meta-learning),另一种是城市级别采样课程(city-level sampling curriculum)。这用于细致思考采样多样性问题。
一些概念:
Curriculum Learning,主张让模型先从容易的样本开始学习,并逐渐进阶到复杂的样本和知识。
meta-learning,又叫learning to learn,即学习如何学习,元学习围绕任务(task)展开。元学习是要去学习任务中的特征表示,从而在新的任务上泛化。
基础推荐器
使用DIN作为基础推荐器,由三部分组成,嵌入模块(Embedding module)、注意力模块(Attention module)和输出模块(Output module)。
元学习
使用MAML策略。
MAML论文:Model-agnostic meta-learning for fast adaptation of deep networks
每轮MAML包括两步骤:局部更新和全局更新。见图中左上部分。
每一次元学习任务都有支持训练集
D
s
p
t
D^{spt}
Dspt用于训练,query训练集
D
q
r
y
D^{qry}
Dqry用于测试。
元学习目标就是学习一个选学习器F,F可以预测推荐器f中的参数
θ
\theta
θ,使损失函数最小化。
硬意识元学习 Hardness Aware Meta-Learning
这里的"hardness"是模型在query样本上的现有性能自判的。
分为两个阶段,hard_city阶段和hard_user阶段。两个任务交替循环。对应图右上。
城市级别采样课程 City-level Sampling Curriculum
见图下方。
分为两阶段,一是困难度测量,使用诸如AUC指标来衡量。二是调度器用于城市pool,定义了一个函数g。课程学习使模型有更大的概率在优化过程中选择容易的梯度步骤。
实验
数据集:百度地图MapSmall、MapLarge(未开源)
输入:POI ID, POI category, time, user-POI dist
输出:POI预测分数
y
i
h
a
t
y^{hat}_i
yihat
基线
针对POI推荐:
- NeuMF
- HGN
- ATST-LSTM
- PLSPL
- iMTL
- DIN
针对迁移策略:
- No transfer
- Pretrain and Fine-Tune(FT)
- MAML
- s 2 s^2 s2Meta
- HAML
贡献点
- 第一个探索城市迁移的下一个兴趣点推荐,并将元学习用于该问题。
- 提出CHAML框架,通过使用用户和城市级别的硬采样挖掘以及城市级别的课程学习(curriculum learning)增强元学习器,达到同时解决数据稀疏和冷启动城市的样本多样性的问题。
- 在两个真实世界地图查找数据集中性能超越SOTA方法。
该框架已在百度地图上进行过A/B测试。
代码
https://github.com/PaddlePaddle/Research/tree/master/ST_DM/KDD2021-CHAML
https://github.com/victorsoda/chaml

















 2428
2428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









