







Decentralized Collaborative Learning Framework for Next POI Recommendation
1. What does literature study?
- 为了促进协作学习,提出将来自地理上或语义上相似的用户的知识整合到每一个本地模型中,以进行聚合和互信息最大化。
2. What’s the innovation?
1. Past shortcomings
- 资源的高消耗:对服务器来说会消耗过多的存储空间和计算资源。
- 隐私问题:POI推荐中历史登记数据会直接显示用户的物理轨迹。
- weak 弹性:集中式POI推荐高度依赖服务器的和互联网连接的稳定性。一旦服务器受损或者过度拥挤,或网络质量无法保证,推荐服务无法确保及时性,甚至可能脱机。
- POI推荐的联邦框架仍然是存储和计算资源密集的,其忽略了用户空间活动和兴趣的动态性、多样性。
2. innovation:
- 提出针对POI推荐的分布式协同学习框架DCLR,用户数据存储本地,最小化依赖云服务器。
- 设计了两个自监督学习任务充分利用POI的地理相关性和分类标签的侧面信息,以减轻数据稀疏性。
- 基于分类相似和地理距离提出两个指标来识别邻居。除此,还提出了邻居通信策略来学习邻居的知识,以进行聚合和互信息最大化。
3. What was the methodology?
协作学习过程利用设备之间的通信,同时仅需要中央服务器的少许参与就可以识别用户组,并且与常见的隐私保护机制(差分隐私)相兼容。
中央服务器仅负责提供预先训练的参数(POI embeddings),以安全的方式对相似用户分组(找邻居)。
服务器端:
设计了两个自监督的预训练任务:将分类和地理信息注入POI表示,第一个任务是:通过MIM(互信息最大化)来创建POI和其相关分类标签之间的相关性;第二个任务是:通过学习和预测POI之间的距离来增强POI表示。与训练POI embeddings作为模型参数的一部分,将随着用户设备上交互数据逐渐更新。
邻居识别策略:此外,我们提出了两个衡量标准来识别相似用户进行协作学习,首先:由类别分布相似性决定语义邻居,就是说,两个用户之间的类别分布相似度越高,他们越有可能是邻居。此外:地理上的邻居由物理距离决定,其中两个用户之间的距离是两组质心之间的最小距离,通过对所有访问过的POI及其经度和维度进行聚类,获得一个用户的多个质心。为了计算类别分布相似度和物理距离,服务器必须从设备中收集类别分布和质心。

采用Spatio-Temporal Attention Network (STAN) 时空注意网络。
1. 基于地理位置引导的自监督学习:
通过注入地理信息来增强POI表示,每个POI
p
p
p与一个地理坐标
(
l
o
n
p
,
l
a
t
p
)
(lon_p,lat_p)
(lonp,latp)相关联,一对POI之间真实距离可以通过Haversine函数计算:
d
i
s
(
p
i
,
p
j
)
=
H
a
v
e
r
s
i
n
e
(
(
l
o
n
p
i
,
l
a
t
p
i
)
,
(
l
o
n
p
j
,
l
a
t
p
j
)
)
dis(p_i,p_j)=Haversine((lon_{p_i},lat_{p_i}),(lon_{p_j},lat_{p_j}))
dis(pi,pj)=Haversine((lonpi,latpi),(lonpj,latpj)),不同的距离有不同的标签,
≤
5
\leq 5
≤5为small,
(
5
,
10
]
(5,10]
(5,10]为中间,
>
10
>10
>10为lage,距离预测为:
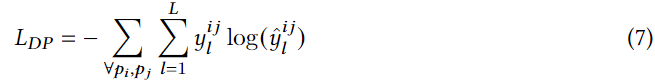
L表示三个距离标签,
y
l
i
j
y_l^{ij}
ylij是标签
l
l
l的one-hot indicator,
y
^
l
i
j
\hat{y}_l^{ij}
y^lij是标签
l
l
l的预测概率,L维概率分布
y
^
i
j
\hat{y}_{ij}
y^ij:
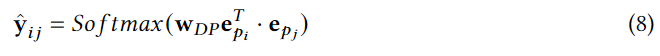
其中 e p i e_{p_i} epi和 e p j e_{p_j} epj是POI p i p_i pi和 p j p_j pj的嵌入, w D P ∈ R 3 × 1 w_{DP}\in \reals^{3×1} wDP∈R3×1是可学习参数,由于设备资源有效,对所有POI对进行距离预测没有意义,因此,每个POI,训练样本包括随机选择的短距离、中距离、长距离POI。
2. 类别感知自监督学习:
通过利用互信息最大化来利用类别信息来丰富POI嵌入,互信息是指两个变量之间的依赖。
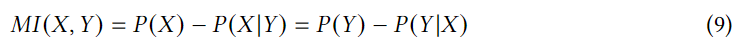
互信息MI用户学习特征表示,我们将一个POI
p
p
p和其相关的类别
c
c
c作为POI的两个视图,设计一个类别预测(CP)损失,以最大化这两个视图之间的互信息:
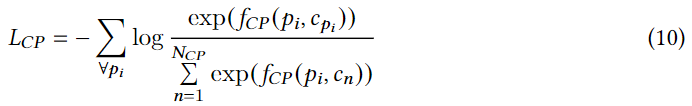
c
p
i
c_{p_i}
cpi是一个POI相关的类别,
N
C
P
N_{CP}
NCP负样本对
(
p
i
,
c
n
)
(p_i,c_n)
(pi,cn)是从类别集合
C
\
c
p
i
C\text{\textbackslash}c_{p_i}
C\cpi采样的,
f
C
P
(
)
f_{CP}()
fCP()是POI 与类别之间的成对相似性函数,在DCLR中它是由一个具有标量输出的双线性网络实现。

两个嵌入维POI和类别, W C P W_{CP} WCP是一个可学习参数矩阵,通过优化损失函数,我们可以最大化正样本对之间的互信息,同时最小化负样本对之间的互信息。
3. 隐私感知邻居识别
让用户设备与其邻居进行通信,这些邻居与当前用户相似。服务器为每个用户执行邻居识别,利用隐式用户偏好来进行邻居识别
1. 地理邻居:
在POI推荐的情况下,两个用户经常访问同一地区的场所,他们具有很高的地理相似性。我们通过测量两个用户访问POIs的质心(平均坐标)之间的距离来识别相似用户,距离越小共享的亲和力越高。在所有他访问过的POIs的坐标上通过k-means聚类为每个用户生成多个质心,质心的数量是为每个用户自适应确定的,使得没有访问过的POI与它们最近的质心距离超出我们预定义的阈值。每个用户
u
n
u_n
un的质心集合:
O
(
u
n
)
=
{
o
1
,
o
2
,
.
.
.
,
o
v
}
O(u_n)=\{ o^1,o^2,...,o^v \}
O(un)={o1,o2,...,ov},每个用户的质心数量
v
v
v是不同的,因为不同用户访问的地方在数量和地理位置上都会有所不同。两个用户地理距离:
d
g
e
o
(
u
n
,
u
m
)
=
m
i
n
(
H
a
v
e
r
s
i
n
e
(
o
n
,
o
m
)
)
d_{geo}(u_n,u_m)=min(Haversine(o_n,o_m))
dgeo(un,um)=min(Haversine(on,om))。质心距离。
2. 语义邻居:
访问过类似的地方表明用户具有相同的兴趣,这些用户被认为是类似的,这样的邻居被称为语义邻居。虽然类别偏好和POI级偏好都能反应用户之间的这种亲和力,但是我们利用类别偏好作为语义相似度的度量标准:拥有相同兴趣爱好的人可能相距甚远,因此不太有可能有类似的POI级偏好;与用户在特定POIs上的check-in相比,在类别层次上的交互相对密集,使得类别偏好成为更准确的语义相似度指标;网络中暴露用户POI级偏好更容易导致隐私泄露。
C
P
(
u
n
)
=
{
c
p
1
n
,
c
p
2
n
,
.
.
.
c
p
∣
C
∣
n
}
CP(u_n)=\{ cp_1^n, cp_2^n,...cp_{|C|}^n\}
CP(un)={cp1n,cp2n,...cp∣C∣n}为用户在C个POI 类别上的分布,可以直接从用户的训练数据中所有访问过的POIs中获得。例如:一个数据集有三个类别,包括Bar,Music,Steakhouse用户访问过Bar2次,Music3次,Steakhouse5次,则用户类别分布为
C
P
(
u
n
)
=
{
0.2
,
0.3
,
0.5
}
CP(u_n)=\{ 0.2, 0.3,0.5\}
CP(un)={0.2,0.3,0.5},采用KL散度来量化两个用户分类偏好之间的距离:
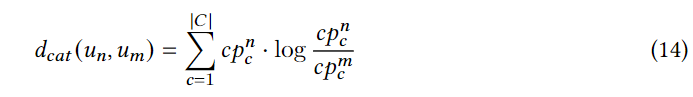
服务器能够计算任何一对用户之间的地理和分类距离, D g e o , D c a t ∈ R ≥ 0 U × U D_{geo},D_{cat} \in \reals_{\ge0}^{U×U} Dgeo,Dcat∈R≥0U×U表示生成的地理和类别距离矩阵,两个矩阵的第 i i i行表示第 n n n个用户和所有其他用户之间的地理距离和分类距离,另外可以通过排序第 n n n行(不包括第 n n n个用户)和选择距离最小的 q q q个用户来确定第 n n n个用户的 q q q个最近邻居。之后对于用户 u n u_n un我们利用 N g e o ( u n ) = { ( u m , d g e o ( u n , u m ) ) } m = 1 q N_{geo}(u_n)=\{ (u_m,d_{geo}(u_n,u_m)) \}_{m=1}^q Ngeo(un)={(um,dgeo(un,um))}m=1q和 N c a t ( u n ) = { ( u m ′ , d c a t ( u n , u m ′ ) ) } m ′ = 1 q N_{cat}(u_n)=\{ (u_{m^{\rq}},d_{cat}(u_n,u_{m^{\rq}})) \}_{m^{\rq}=1}^q Ncat(un)={(um′,dcat(un,um′))}m′=1q来表示识别的地理和分类邻居IDs以及他们与 u n u_n un的距离。这两个集合是服务器将在邻居标识之后向所有用户切换以进行后续计算的信息。
4. 合并差分隐私:
服务器收集所有用户的质心集合
O
(
u
n
)
O(u_n)
O(un)和类别偏好
C
P
(
u
n
)
CP(u_n)
CP(un),通过计算地理距离矩阵和类别距离矩阵,服务器可以通知所有用户其邻居IDs,由拉普拉斯分布得到的噪声注入质心
O
(
u
n
)
O(u_n)
O(un)和类别分布
C
P
(
u
n
)
CP(u_n)
CP(un)来实现
ϵ
\epsilon
ϵ差分隐私。

D
D
D是由用户提交的数据,
f
(
)
f()
f()表示一个任意的随机函数,
ϵ
\epsilon
ϵ为隐私预算(隐私保护程度),
Δ
f
\Delta f
Δf是函数
f
(
)
f()
f()的敏感度:
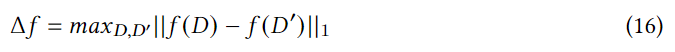
D D D和 D ′ D' D′是两个相邻的数据集,只有一条记录不同,对于质心 O ( u n ) O(u_n) O(un),灵敏度可以很容易地通过两个最远的质心之间的经纬度之和来获得,对于 C P ( u n ) CP(u_n) CP(un),类别分布来自用户所有POI类别的用户访问计数,计数查询的灵敏度为1,在将他们转换为类别分布之前,为所有类别访问次数添加噪声,通过调整 ϵ \epsilon ϵ控制用户隐私。
5. 给定地理邻居
N
g
e
o
(
u
n
)
N_{geo}(u_n)
Ngeo(un)和语义邻居
N
c
a
t
(
u
n
)
N_{cat}(u_n)
Ncat(un),两种类型邻居有不同的知识,简单聚合所有邻居会导致性能下降:首先,通过地理邻居和语义邻居分别进行知识交换,生成两个增强模型;然后进一步结合这两个增强模型与每个用户完全个性化的本地推荐结合。这样的通信过程在本地实现,邻居的模型权重从
N
g
e
o
(
u
n
)
N_{geo}(u_n)
Ngeo(un)和
N
c
a
t
(
u
n
)
N_{cat}(u_n)
Ncat(un)转移到
u
n
u_n
un。该框架中,地理邻居和语义邻居具有不同的权重,因为他们对当前用户有不同的距离。因此,提出了一种基于亲和力的模型聚合策略学习邻居的知识。为了学习带有地理邻居的增强模型,首先根据邻居和当前用户之间的距离计算它们之间的相似度:
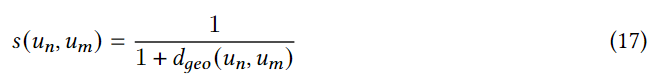
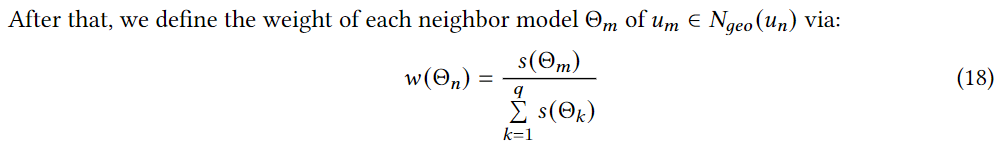
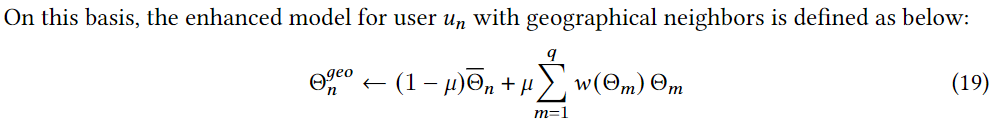
Θ
ˉ
\bar{\Theta}
Θˉ是当前用户的初始模型,
μ
\mu
μ是超参数控制当前模型和基于邻居的聚合模型的比例,
Θ
n
c
a
t
\Theta_n^{cat}
Θncat计算类似,如何无损失地结合两个模型来获得每个用户的最终模型:这两个增强模型可以看作是当前模型的不同视图,可以使用互信息最大化来彼此获得知识。对于两个模型中的同一个POI嵌入结合起来构建正向的训练样本,对于每个正对,从相应的模型中随机抽取一个不同的POI嵌入交换一个POI嵌入,从而生成负样本。
两个模型的组合损失:
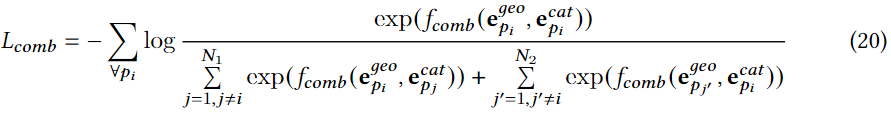
e
p
i
g
e
o
e_{p_i}^{geo}
epigeo和
e
p
i
c
a
t
e_{p_i}^{cat}
epicat是两个模型相同POI的嵌入,
e
p
j
c
a
t
e_{p_j}^{cat}
epjcat和
e
p
j
′
g
e
o
e_{p_{j'}}^{geo}
epj′geo分别是
Θ
n
c
a
t
\Theta_n^{cat}
Θncat和
Θ
n
g
e
o
\Theta_n^{geo}
Θngeo的负嵌入,是每个模型的负样本数,
N
1
=
N
2
N_1 = N_2
N1=N2是来自模型的负样本数,
f
c
o
m
b
(
,
)
f_{comb}(,)
fcomb(,)是相对相似性以实现双线性网络,
w
c
o
m
b
w_{comb}
wcomb是可学习参数矩阵,一旦通过最小化
L
c
o
m
b
L_{comb}
Lcomb完成两个增强模型的细化,我们进一步平均两个细化模型得到最终的个性化模型。
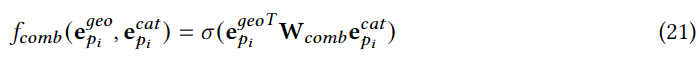

实现上述过程,用户必须收集其邻居的模型权重,这可能会导致隐私泄露,类似共享质心和类别分布时的策略,在将他们传递给邻居用户设备之前,我们将噪声注入模型权重中。
6. 服务器端开始
line1-5用两个自监督学习信号初始化推荐和预训练POI表示。通过从所有用户设备接收扰动的质心和类别偏好line6,服务器通过计算地理距离矩阵和类别距离矩阵line7-8,然后将邻居信息发送给所有用户line9,服务器的参与结束;回到用户端,在获得预训练的POI嵌入后line10-12,我们在每个训练epoch记录更新的用户模型参数为
Θ
ˉ
n
\bar{\Theta}_n
Θˉnline14-16;之后
Θ
ˉ
n
\bar{\Theta}_n
Θˉn通过地理上和语义上相似的用户进行增强,这将经历一个互信息最大化步骤,然后合并;在设备上进行协同学习指导局部模型收敛。

4. What are the conclusions?
- 提出的DCLR分布式范式,本地训练个性化推荐。为了解决数据稀疏的问题,首先设计了两个自监督信号,用坐标和分类标签来增强POI表示;然后对于分布式协作学习,我们定义了两个指标:来识别地理距离和分类偏好相似性的邻居;最后利用了注意力和互信息最大化技术,共同学习和组合两类邻居的知识。在两个实际数据集上的实验结果证明了我们的模型在下一个 POI 推荐中的优越性,因为它可以提供准确的个性化 POI 推荐和强大的隐私保护。
5. others
- POI推荐已成为基于位置的社交网络(LBSN)中不可或缺的功能。

- check-in 活动: x = ( u , p , t ) x = (u, p, t) x=(u,p,t),用户u,兴趣点p,时间点t。
- check-in 序列:包含用户u的M个连续check-in活动,表示为 X ( u i ) = { x 1 , x 2 , . . . , x M } X(u_i) = \{ x_1, x_2,...,x_M \} X(ui)={x1,x2,...,xM}。从服务器接收到匿名另据IDs,每个移动设备将从其邻居那里获取并聚合知识,以更新本地模型。给定 X ( u i ) X(u_i) X(ui)和邻居IDs,本地模型被训练为根据每个用户最近的兴趣作为推荐提供一个POIs的排序列表。
- 每个check-in活动的输出x是
e
x
=
e
p
+
e
t
∈
R
d
e_x = e_p + e_t \in \reals^d
ex=ep+et∈Rd,每个用户序列的输入为
X
u
=
[
e
x
1
,
e
x
2
,
.
.
.
,
e
x
M
]
∈
R
M
×
d
X_u = [ e_{x_1}, e_{x_2},...,e_{x_M} ] \in \reals^{M×d}
Xu=[ex1,ex2,...,exM]∈RM×d,STAN网络进一步编码两次check-in之间的时间间隔:
e
a
b
Δ
∈
R
d
,
e
a
b
Δ
=
Δ
a
b
s
×
e
Δ
s
+
Δ
a
b
t
×
e
Δ
t
e_{ab}^\Delta \in \reals^d,e_{ab}^\Delta=\Delta_{ab}^s×e_{\Delta_s}+\Delta_{ab}^t×e_{\Delta_t}
eabΔ∈Rd,eabΔ=Δabs×eΔs+Δabt×eΔt,其中
e
Δ
s
e_{\Delta_s}
eΔs和
e
Δ
t
e_{\Delta_t}
eΔt为单位嵌入表示特定数量的空间(一公里)或时间(一小时)差异。
Δ
a
b
s
\Delta_{ab}^s
Δabs和
Δ
a
b
t
\Delta_{ab}^t
Δabt是
x
a
x_a
xa和
x
b
x_b
xb两个check-in之间真正的时空差异(例如:10公里和5小时)。轨迹时空-时间嵌入关系矩阵是
Δ
∈
R
M
×
M
\Delta \in \reals^{M×M}
Δ∈RM×M:
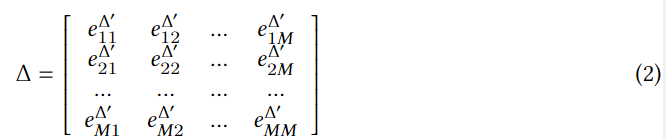
e
a
b
Δ
′
e_{ab}^{\Delta^{\rq}}
eabΔ′是
e
a
b
Δ
e_{ab}^\Delta
eabΔ元素和,之后采用自注意机制进一步结合嵌入序列和时空差异,最终的嵌入序列为:
E
u
∈
R
M
×
d
E_u\in \reals^{M×d}
Eu∈RM×d
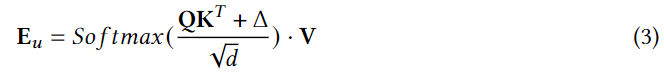
用户访问候选POI的可能性计算为:
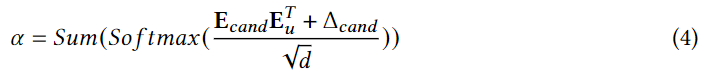
之后对于每个用户设备模型,采用交叉熵来定义用户优化的POI预测损失:
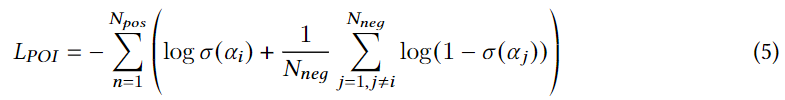
其中
N
p
o
s
N_{pos}
Npos是用户的正样本数量,
N
n
e
g
N_{neg}
Nneg是从用户未访问的POIs中随机抽取的正样本
p
i
p_i
pi的负样本数。(每个正样本
p
i
p_i
pi的负样本数),
α
i
\alpha_i
αi和
α
j
\alpha_j
αj分别为正样本和负样本的分数。
6. POI推荐已成为基于位置的社交网络(LBSN)中不可或缺的功能。
自监督任务用于预训练服务器上的POI嵌入,然后在设备上利用用户自己的交互进一步优化。与不断与用户设备通信并参与本地模型优化的联邦模型相比,DCLR中的参数训练是一个一次性过程,仅涉及不敏感的公共数据训练的公共POI嵌入。
地理信息在下一个POI推荐中是必不可少的,因为用户对下一个POI偏好高度依赖用户当前POI的距离,然而,当前的POI推荐系统仅仅捕获了在轨迹上观测到的POI之间的地理相关性。因此,我们进一步使用POIs之间的成对距离来编码地理属性。
用户对特定POIs的check-in稀疏,但是再类别级别的互动相对(餐馆,娱乐)密集。类别方面的预测能够在POI级对用户的兴趣提供有力的预测信号,例如,用户对娱乐场所的强烈偏好表明,他可能会访问这类公共娱乐场所,比如电影院和酒吧。















 1427
1427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









