









1.背景
meta-learning区别于pretraining,它主要通过多个task来学习不同任务之间的内在联系,通俗点说,也即是通过多个任务来学习共同的参数。
举个例子,人类在进行分类的时候,由于见过太多东西了,且已经学过太多东西的分类了。那么我们可能只需每个物体一张照片,就可以对物体做到很多的区分了,那么人是怎么根据少量的图片就能学习到如此好的成果呢?
显然 ,我们已经掌握了各种用于图片分类的较巧了,比如根据物体的轮廓、纹理等信息进行分类,那么根据轮廓、根据纹理等区分物体的方法,就是我们在meta learning中需要教机器进行学习的学习技巧。
2.Meta-learning理解
meta-learning主要有以下几个概念,理解了概念我们就更容易理解这个算法到底在干什么。
2.1 Meta-learning到底做什么
meta-learning主要分为两个阶段:
- meta-train:用来训练模型参数,使得模型能够学到不同任务中的共同参数
- meta-test:类似于fine-tuneing阶段,用来微调下游任务。
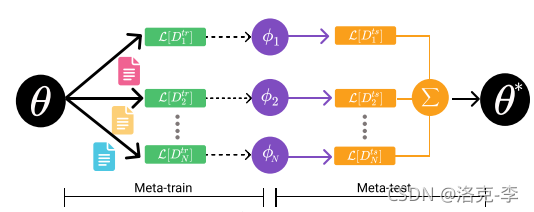
首先假设我们首先有数据集 D D D,这个数据集有10个类别,每个类别有100个样本,共1000个样本数聚集。
我们把数据集进行分割,把100个样本分成3份,比例是1:4:5。这三份的样本数量为10,40,50。
- N-way K-shot:在meta-train阶段,假设实验中设置5-way 10-shot,也就是在每个任务task中抽样5个类别,每个类别10份数据,构成一个support set,用在meta-train阶段。这5个类别中,另外的40份数据为query set,可以用在meta-test阶段;而还剩10个类别的50份数据,用来进行微调任务。
2.2 MAML算法
MAML是用来实现meta-learning的一种算法。下面用例子来说明MAML的算法实现过程。
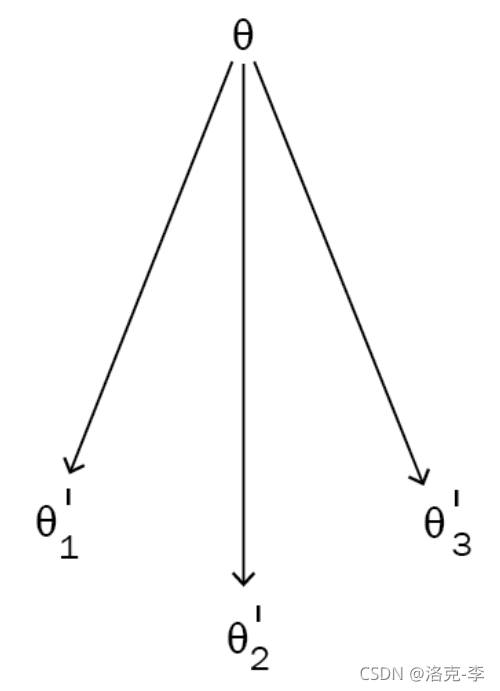
假设我们目前有3个tasks,分别为 T 1 , T 2 , T 3 T_1,T_2,T_3 T1,T2,T3。按照以前模型的训练方式,首先,我们随机初始化模型参数 θ \theta θ。然后开始训练任务 T 1 T_1 T1,接着最小化损失函数 L L L来更新网络的参数,这样我们就会得到新的参数 θ 1 ′ \theta'_1 θ1′。同理,我们可以接着更新其他两个任务。
但以前模型的训练方式,是每个任务都是随机初始化 θ \theta θ开始,每个任务都是独立的。如果我们把三个任务初始化的 θ \theta θ到公用的位置,则不需要更多的梯度更新步骤。MAML就是做这件事的。
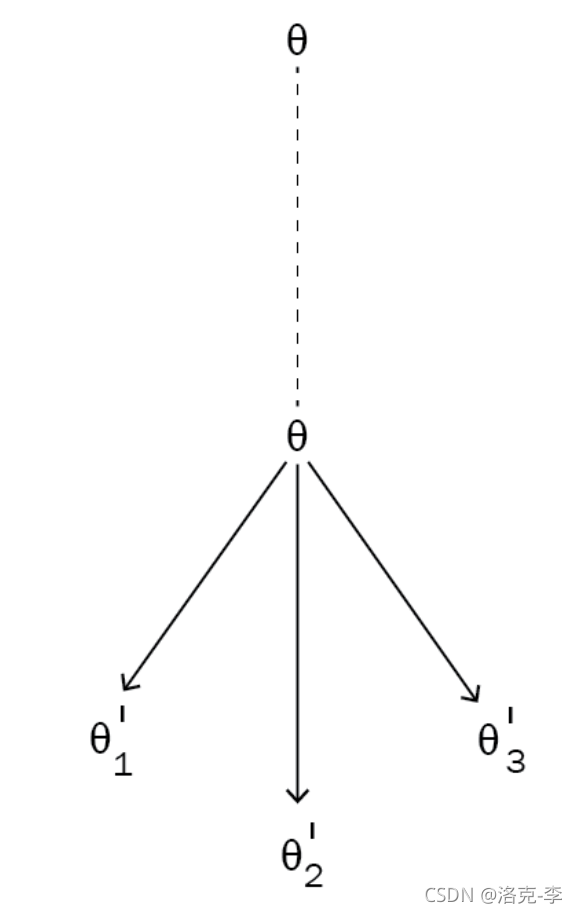
MAML 试图找到许多相关任务共有的最佳参数 θ \theta θ,因此我们可以用很少的数据相对快速地训练新任务,而无需通过采取许多梯度步骤来确定最佳状态初始化 θ \theta θ 。
如下图所示, θ \theta θ重新固定到一个新的位置来训练。对于一个新的任务task T 4 T_4 T4,就不需要重新随机初始化参数来训练了。
2.3 MAML算法步骤
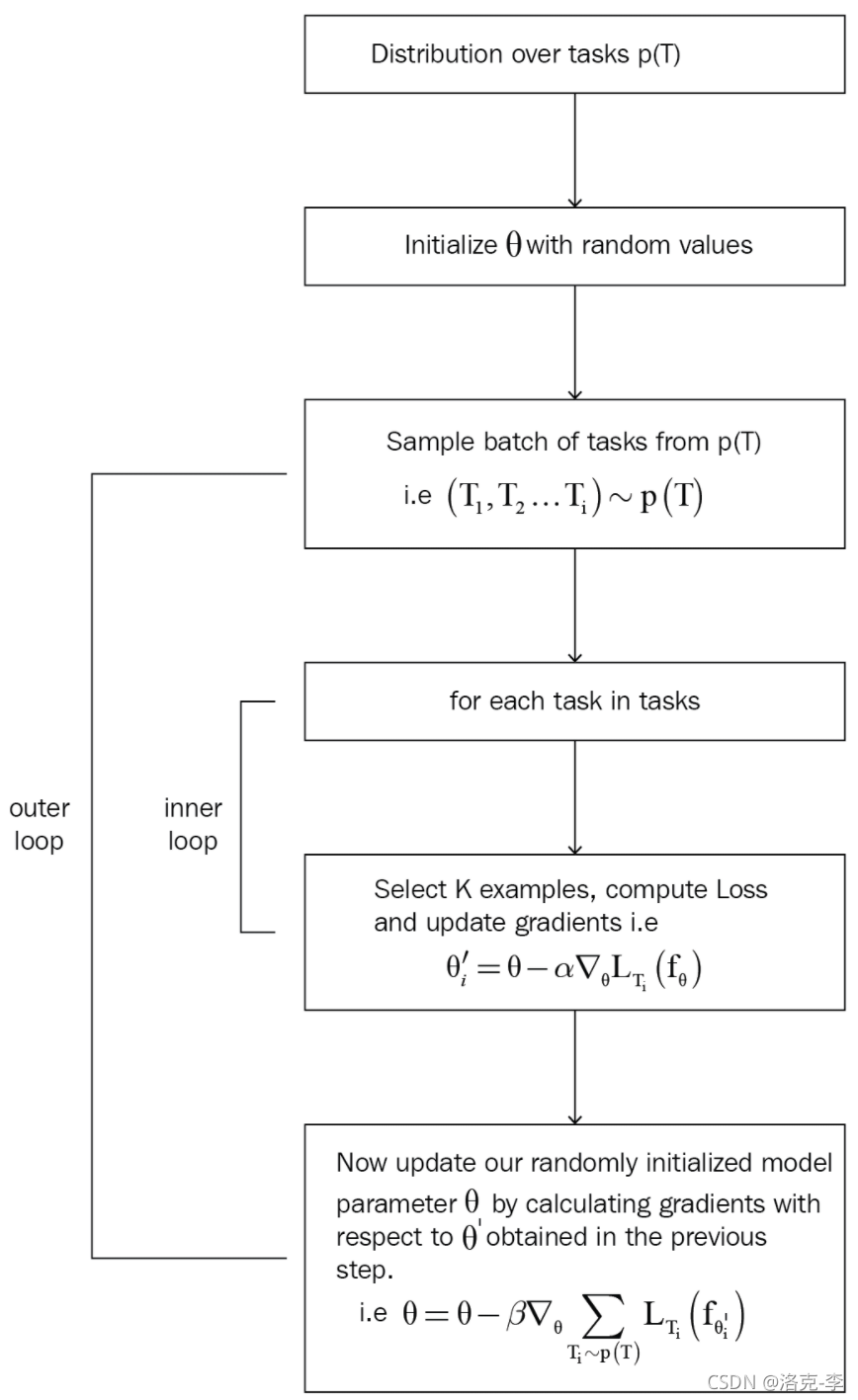
具体的MAML算法如图所示:
我们有模型
f
θ
(
)
f_\theta()
fθ(),其参数为
θ
\theta
θ。同时又一系列任务
p
(
T
)
p(T)
p(T)。
- 首先,随机初始化Meta模型参数 θ \theta θ。
- 对于第 i i i任务 T i T_i Ti,抽样batch个 T i T_i Ti,这样就会构成一个batch,其中 T i ∼ p ( T ) T_i \sim p(T) Ti∼p(T)。
下面是内循环的操作:
-
如果我们有5个任务,则 T = { T 1 , T 2 , T 3 , T 4 , T 5 } T=\{T_1,T_2,T_3,T_4,T_5\} T={T1,T2,T3,T4,T5}。从每个 T i T_i Ti中,抽样 K K K个数据。对于每个任务,都需要更新一次参数:
θ i ′ = θ − α ∇ θ L T i ( f θ ) \theta'_i = \theta - \alpha \nabla_{\theta} L_{T_i}(f_{\theta}) θi′=θ−α∇θLTi(fθ)
其中 θ i ′ \theta'_i θi′是任务 T i T_i Ti的最佳参数; α \alpha α是学习率; ∇ θ L T i ( f θ ) \nabla_{\theta} L_{T_i}(f_{\theta}) ∇θLTi(fθ)是梯度。 -
对每个任务进行更新,这样会得到5个最佳参数, θ ′ = { θ 1 ′ , θ 2 ′ , θ 3 ′ , θ 4 ′ , θ 5 ′ } \theta' =\{ {\theta'_1, \theta'_2, \theta'_3, \theta'_4, \theta'_5}\} θ′={θ1′,θ2′,θ3′,θ4′,θ5′}
下面是外循环的操作:
- 在外循环中,我们需要更新原始的meta模型参数
θ
\theta
θ。利用任务
T
i
T_i
Ti,来生成每个任务的loss值,然后梯度更新参数
θ
\theta
θ。
θ = θ − β ∇ θ ∑ T i ∼ p ( T ) L T i ( f θ i ) \theta = \theta - \beta \nabla_{\theta} \sum_{T_i \sim p(T)} L_{T_i}(f_{\theta_i}) θ=θ−β∇θTi∼p(T)∑LTi(fθi)
其中, θ \theta θ是我们原始meta模型的参数值; β \beta β是超参数; ∑ T i ∼ p ( T ) L T i ( f θ i ) \sum_{T_i \sim p(T)} L_{T_i}(f_{\theta_i}) ∑Ti∼p(T)LTi(fθi)是每个任务 T i T_i Ti的梯度。
PS:
- 内循环中:只需要利用support set一步更新就可以
- 外循环中:需要利用query set进行多次迭代更新。
2.4 MAML代码分析和实现
自定义样本抽取代码, x x x的维度为 ( k , 50 ) (k, 50) (k,50):
def sample_points(k):
x = np.random.rand(k,50)
y = np.random.choice([0, 1], size=k, p=[.5, .5]).reshape([-1,1])
return x,y
x, y = sample_points(10)
print x[0]
print y[0]
输出结果:

利用简单的前馈神经网络作例子:
a = np.matmul(X, theta)
YHat = sigmoid(a)
MAML实现代码:
class MAML(object):
def __init__(self):
"""
定义参数,实验中用到10-way,10-shot
"""
# 共有10个任务
self.num_tasks = 10
# 每个任务的数据量:10-shot
self.num_samples = 10
# 训练的迭代次数
self.epochs = 10000
# 内循环中,学习率,用来更新\theta'
self.alpha = 0.0001
# 外循环的学习率,用来更新meta模型的\theta
self.beta = 0.0001
# meta模型初始化的参数
self.theta = np.random.normal(size=50).reshape(50, 1)
# sigmoid函数
def sigmoid(self,a):
return 1.0 / (1 + np.exp(-a))
#now let us get to the interesting part i.e training :P
def train(self):
# 循环epoch次数
for e in range(self.epochs):
self.theta_ = []
# 利用support set
for i in range(self.num_tasks):
# 抽样k个样本出来,k-shot
XTrain, YTrain = sample_points(self.num_samples)
# 前馈神经网络
a = np.matmul(XTrain, self.theta)
YHat = self.sigmoid(a)
# 计算交叉熵loss
loss = ((np.matmul(-YTrain.T, np.log(YHat)) - np.matmul((1 -YTrain.T), np.log(1 - YHat)))/self.num_samples)[0][0]
# 梯度计算,更新每个任务的theta_,不需要更新meta模型的参数theta
gradient = np.matmul(XTrain.T, (YHat - YTrain)) / self.num_samples
self.theta_.append(self.theta - self.alpha*gradient)
# 初始化meta模型的梯度
meta_gradient = np.zeros(self.theta.shape)
# 利用query set
for i in range(self.num_tasks):
# 在meta-test阶段,每个任务抽取10个样本出来进行
XTest, YTest = sample_points(10)
# 前馈神经网络
a = np.matmul(XTest, self.theta_[i])
YPred = self.sigmoid(a)
# 这里需要叠加每个任务的loss
meta_gradient += np.matmul(XTest.T, (YPred - YTest)) / self.num_samples
# 更新meat模型的参数theta
self.theta = self.theta-self.beta*meta_gradient/self.num_tasks
if e%1000==0:
print "Epoch {}: Loss {}\n".format(e,loss)
print 'Updated Model Parameter Theta\n'
print 'Sampling Next Batch of Tasks \n'
print '---------------------------------\n'
最后输出结果:
model = MAML()
model.train()

3.参考文章
1.[meta-learning] 对MAML的深度解析
2.https://github.com/sudharsan13296/Hands-On-Meta-Learning-With-Python















 2654
2654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











