







大模型高效参数微调(PEFT,Parameter-Efficient Fine-Tuning)
PEFT旨在通过最小化微调参数数量和计算复杂度,实现高效的迁移学习。它仅更新模型中的部分参数,
显著降低训练时间和成本,适用于计算资源有限的情况。
背景
-
预训练成本高,比如LLaMA -65B需要780GB显存
-
提示工程有天花板,具体表现在token上限和推理成本
-
基础模型缺少特定领域数据
-
数据安全和隐私
-
个性化服务需要私有化的微调大模型
PEFT微调优缺点对比

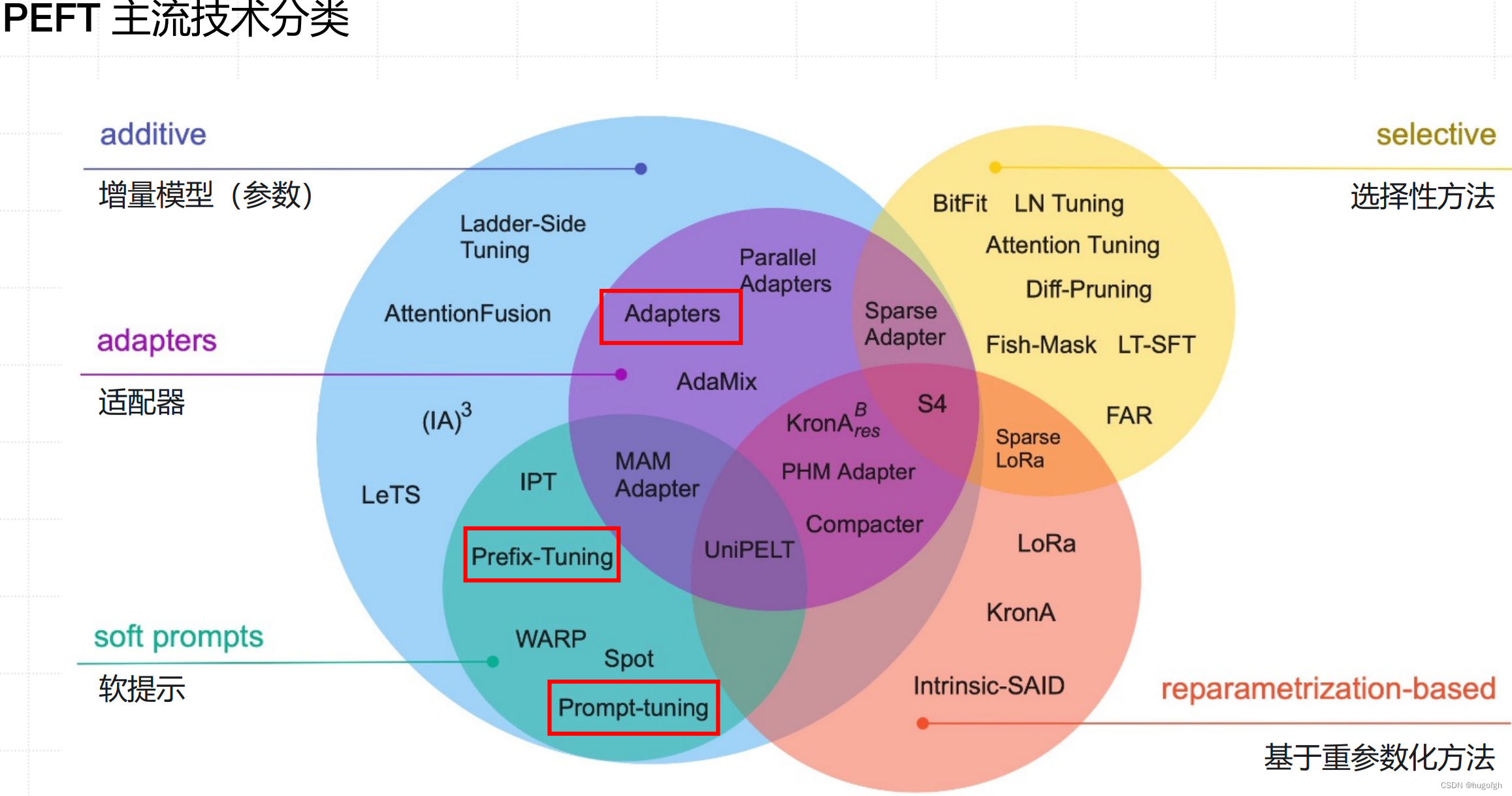
PEFT主流技术方案
——围绕提示词Token做文章,预训练
语言模型(PLM)不变
-
Prompt Tuning
-
Prefix Tuning
-
P-Tuning
—— 特定场景任务:训练“本质”的低维模型,重参数化
-
LORA
-
QLORA
-
AdaLORA
——新思路:少量数据、统一框架
-
IA3
-
UniPELT
1、Prefix Tuning
-
-
方法:在预训练Transformer 前增加可学习的virtual tokens作为Prefix 模块。
-
特点:仅更新Prefix参数,Transformer其他部分固定。
-
优点:减少需要更新的参数数量,提高训练效率。
-
2、Prompt Tuning
-
-
方法:在输入层加入prompt tokens。
-
特点:简化版的Prefix Tuning,无需MLP调整。
-
优点:随着模型规模增大,效果接近full fine-tuning。
-
3、P-Tuning
-
-
方法:将Prompt转换为可学习的Embedding层,并用MLP+LSTM处理。
-
特点:解决Prompt构造对下游任务效果的影响。
-
优点:提供更大的灵活性和更强的表示能力。
-
4、P-Tuning v2
-
-
方法:在多层加入Prompt tokens。
-
特点:增加可学习参数数量,对模型预测产生更直接影响。
-
优点:在不同任务和模型规模上实现更好的性能。
-
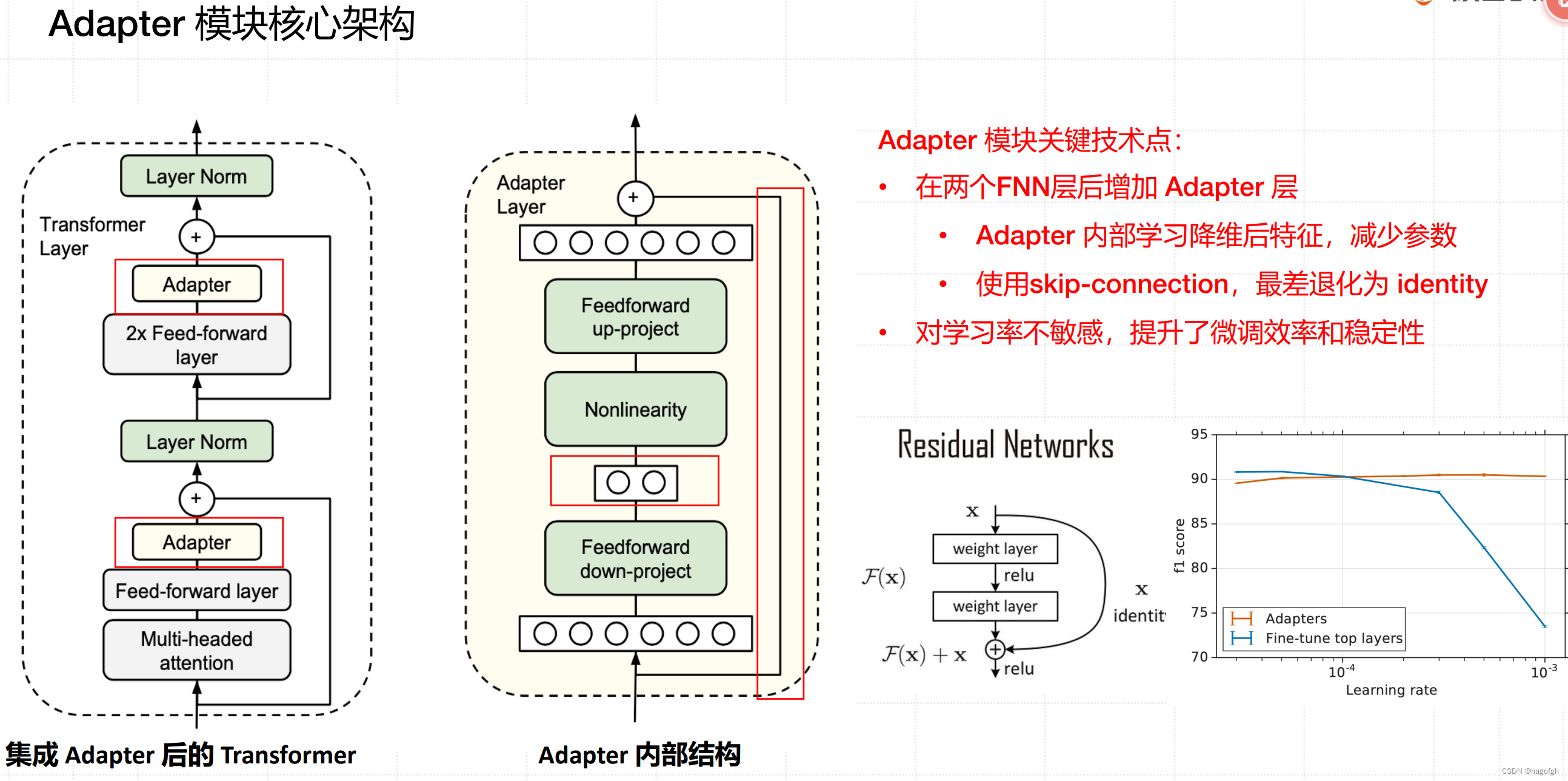
5、Adapter Tuning
-
-
方法:设计Adapter结构并嵌入Transformer中。
-
特点:仅对新增的Adapter结构进行微调,原模型参数固定。
-
优点:保持高效性的同时引入少量额外参数。
-
Adapter模块关键技术点:
-
在两个FNN层后增加Adapter层
-
Adapter内部学习降维后特征,减少参数
-
使用skip-connection,最差退化为identity
-
对学习率不敏感,提升了微调效率和稳定性
-
-
6、LoRA(Low-Rank Adaptation)
-
-
方法:在矩阵相乘模块中引入低秩矩阵来模拟full fine-tuning。
-
特点:更新语言模型中的关键低秩维度。
-
优点:实现高效的参数调整,降低计算复杂度。
-
大模型低秩适配(LoRA)技术
现有PEFT方法的局限与挑战
-
Adapter方法,通过增加模型深度而额外增加了模型推理延时。
-
Prompt Tuning、Prefix Tuning、P-Tuning等方法中的提示较难训练,同时缩短了模型可用的序列长度。
-
往往难以同时实现高效率和高质量,效果通常不及完全微调(full-finetuning)。
-
简而言之,尽管大模型参数规模巨大,但关键作用通常是由其中的低秩本质维度(low intrinsic dimension)发挥的。
-
受此启发,微软提出了低秩适配(LoRA)方法,设计了特定结构,在涉及矩阵乘法的模块中引入两个低秩矩阵A和B,以模拟完全微调过程。这相当于只对语言模型中起关键作用的低秩本质维度进行更新。
为了使微调更加高效,LoRA的方法是通过低秩分解将权重更新表示为两个较小的矩阵(称为更新矩阵)。这些新矩阵可以在适应新数据的同时保持整体变化数量较少进行训练。原始权重矩阵保持冻结状态,并且不再接受任何进一步的调整。最终结果是通过将原始权重和适应后的权重进行组合(相加)得到。
LoRA核心技术揭秘
-
LoRA的核心思想
假设LLM在下游任务上微调得到的增量参数矩阵△W是低秩的,即使存在冗余参数的高维矩阵,但实际有效矩阵是更低纬度的。
-
LoRA的基本原理
冻结预训练好的模型权重参数,在冻结原模型参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。

LoRA相比Adapter方法的优势
1、推理性能高效:
-
与Adapter方法相比,LoRA在推理阶段直接利用训练好的A、B低秩矩阵替换原预训练模型的对应参数。这种替换避免了增加网络深度所带来的额外计算量和推理延时。
-
LoRA方法使得推理过程与全参数微调(Full-finetuning)相似,但并不增加额外的计算负担。保持了高效的推理性能,同时实现了对模型的有效调整。
2、模拟全参数微调的效果:
-
LoRA通过对模型关键部分的低秩调整,实际上模拟了全参数微调的过程。
-
这种方法几乎不会导致训练效果的损失,后续实验结果也证明了这一点。
综上所述,LoRA提供了一种在保持推理效率的同时,有效微调大型预训练模型的方法,特别适用于对推理速度和模型性能都有高要求的应用场景。
LoRA相比Soft Prompts方法的优势
1、更深层次的模型修改:
-
LoRA通过修改模型的权重矩阵,直接影响模型的内部表示和处理机制,而不仅仅是输入层级。
-
这意味着LoRA能够在模型的更深层次上产生影响,可能导致更有效的学习和适应性。
2、无需牺牲输入空间:
-
Soft prompts通常需要占用模型的输入空间,这在有限的序列长度下可能限制了其他实际输入内容的长度。
-
LoRA不依赖于Prompt调整方法,避免了相关的限制,因此不会影响模型能处理的输入长度。
3、直接作用于模型结构:
-
LoRA通过在模型的特定层(如Transformer层)内引入低秩矩阵来调整模型的行为,这种修改是直接作用于模型结构的。
-
相比之下,soft prompts更多是通过操纵输入数据来影响模型的输出。
4、更高的灵活性和适应性:
-
LoRA提供了更大的灵活性,在不同的层和模型部件中引入低秩矩阵,可以根据具体任务进行调整。
-
这种灵活性使得LoRA可以更精细地调整模型以适应特定的任务。
5、模拟全参数微调的效果:
-
LoRA的设计思路是模拟全参数微调的过程,这种方法通常能够带来更接近全面微调的效果,尤其是在复杂任务中。
总的来说,LoRA的优势在于其能够更深入地、不占用额外输入空间地修改模型,从而提供更高的灵活性和适应性,尤其适合于需要深层次模型调整的场景。
AdaLoRA: 自适应权重矩阵的高效微调
LoRA 核心思想:
对下游任务增量训练小模型,针对性地对下游任务增量训练小模型(W=W0+△W)。实质上,就是寻找小矩阵B、A等,使得整体的训练效果最好。

LoRA 问题:
-
预先指定超参数增量矩阵的本征秩 r,无法自适应调整。
-
低估了权重矩阵的种类和不同层对的微调效果影响。
-
只微调了Attention,忽略了FFN模块。
AdaLoRA 解决思路:
-
使用 SVD 提升矩阵低秩分解性能,AdaLoRA使用SVD的三元组替代了LoRA的二元组。
-
模型剪枝:对模块参数(特征)的重要性建模。
-
根据重要性评分,动态调整不同权重矩阵的本征秩r。
AdaLoRA的核心结构:
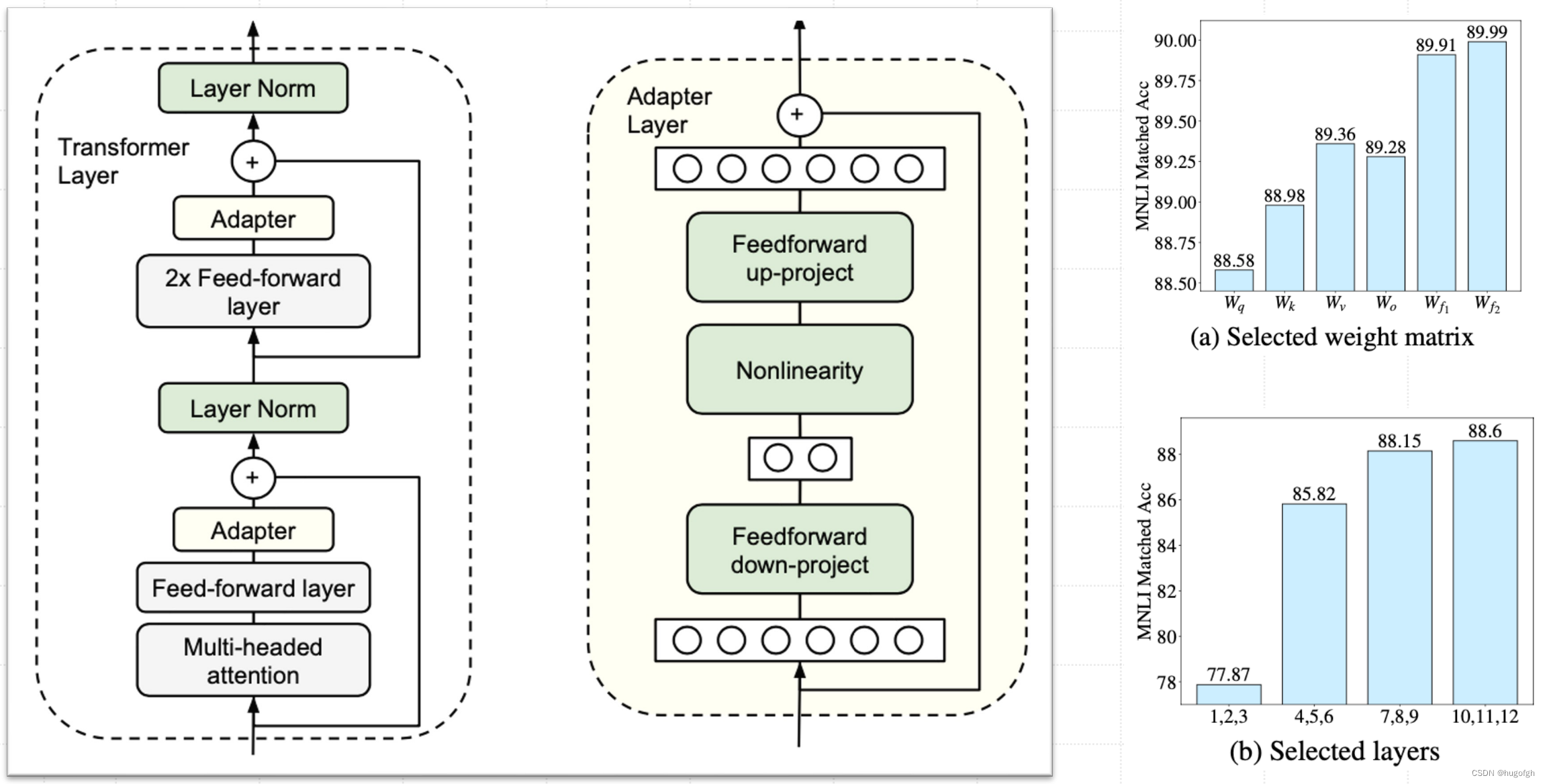
左侧是Adapter tuning的网络结构图,右侧是AdaLoRA的选择不同层和不同权重在数据集上的效果。
AdaLoRA使用SVD提升矩阵低秩分解性能
1.定义:
奇异值分解(Singular Value Decomposition, SVD)将任意一个矩阵分解为三个特定的矩阵的乘积:左奇异向量矩阵、奇异值矩阵和右奇异向量矩阵。
2.数学表示:
-
对于任意一个矩阵(A),SVD表示为(A = UΣV^T)。
-
其中,(U)和(V)是正交矩阵,表示左右奇异向量;Σ是对角矩阵, 对角线上的元素是奇异值。
-
正交矩阵:是一个方块矩阵,该矩阵的行向量与列向量皆为正交的单位向量,使得该矩阵的转置矩阵为其逆矩阵。
3.应用
-
在数据科学和机器学习中,SVD用于降维、数据压缩、噪声过滤等。
-
在自然语言处理中,SVD用于提取文本数据的潜在语义结构。

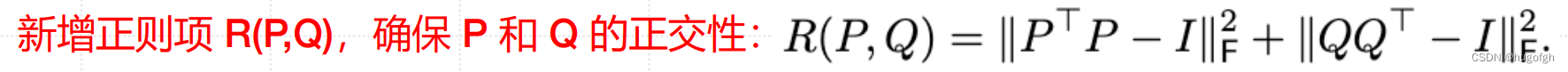
AdaLoRA对模块参数(特征)重要性建模

AdaLoRA根据重要性评分剪枝和自适应调整本征秩r

QLoRA量化低秩适配微调
论文《QLoRA:Efficient Finetuning of Quantized LLMs》提出了一种QLoRA训练微调方法,通过这种方式可以在单个48G的GPU显卡上微调65B的参数模型,采用这种方式训练的模型可以保持16字节微调任务的性能。QLoRA通过冻结的int 4量化预训练语言模型反向传播梯度到低秩适配器LoRA来实现微调。
FFT vs LoRA vs QLoRA
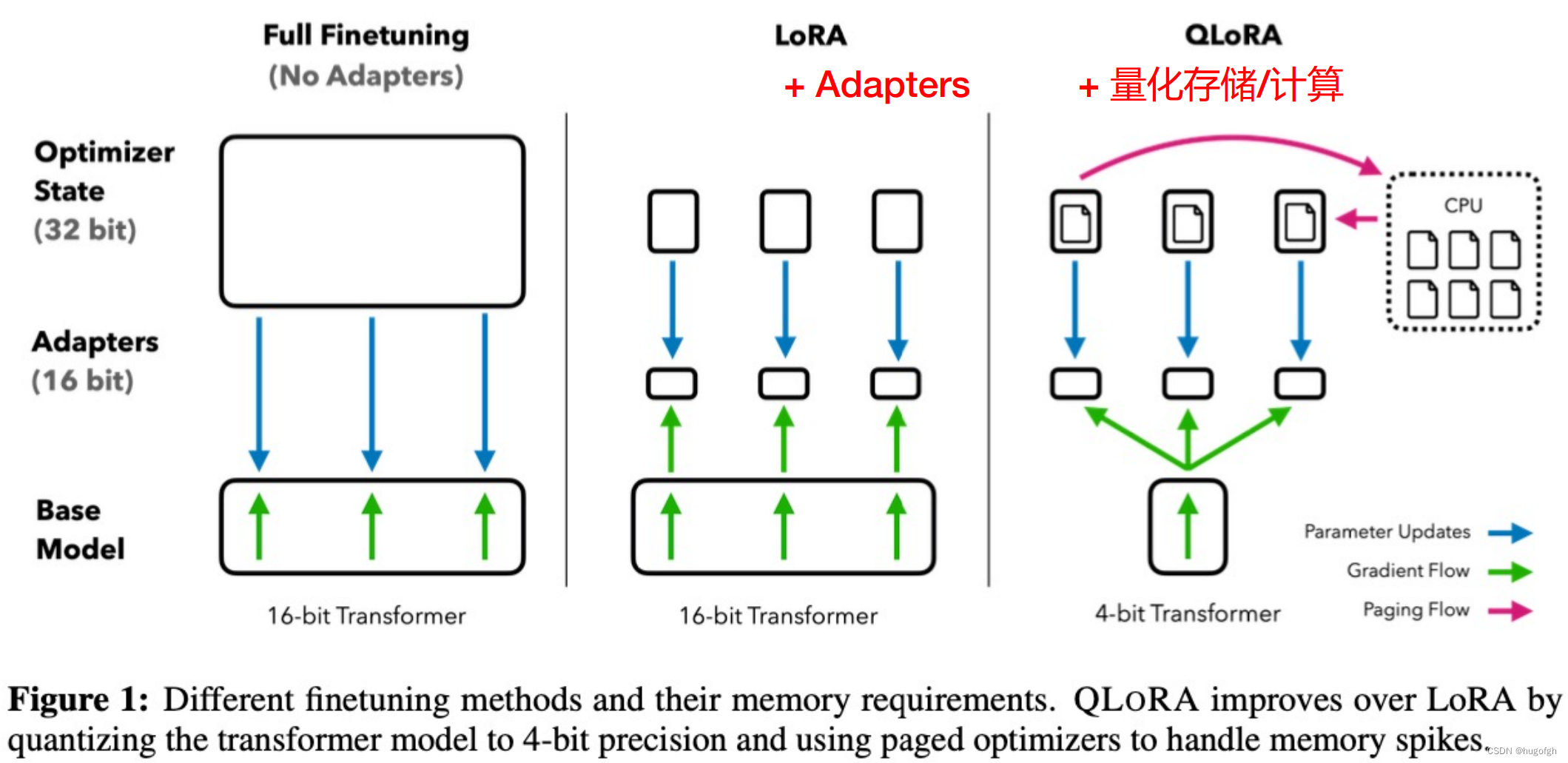
QLoRA提出新数据类型4-bit NormalFloat(NF4)
NF4就是将所有的权重转化到特定的分布上,并通过缩放因子还原初始值,并以正态因子的形式存储下来。

QLoRA 提出双量化技术:量化(量化常数)
-
双量化技术思想
通过分位数这个函数,将真实的数据存储到存储桶中。所存储的数据又可以通过解压缩的方式转化为初始数据。在存储过程中会产生量化常数,而量化常数需要进行解压缩,就必须乘上这些数字,这些数字也可以被量化存下来。
-
分页技术
核心思想:为了防止系统崩溃,需要选择数据并加载进来以后,再进行前向和后向传播计算的过程。一旦数据没有选择正确,就有可能导致所存储一层显存崩溃掉。为了解决这个问题,英伟达会自动对所选数据存储到CPU,分页技术实现了CPU和GPU之间传输数据不会导致数据异常,又可以实现数据之间的相互传输。
QLoRA 将权重从存储数据类型反量化为计算数据类型,以执行前向和后向传播,但仅计算 16-bitBrainFloat 的 LoRA 参数的权重梯度。权重仅在需要时才解压缩,因此在训练和推理期间内存使用率都能保持较低水平。
-
存算分离
针对参数的存储规模达到100GB,甚至上千GB的情况下,NF4通过极致压缩存储空间,并将计算和存储分离。需要计算的时候将压缩的数据进行解压缩,进行计算。计算完成以后再次将计算结果进行压缩存储。从而实现了“时间换空间”的策略。
UniPELT大模型PEFT统一框架
UIUC 和 Meta AI 研究人员发表的 UniPELT 提出将不同的 PEFT 方法模块化。通过门控机制学习激活最适合当前数据或任务的方法,尤其是最常见的3大类 PEFT 技术:
1、Adapter(适配器):
-
接入位置(如:FFN)
-
接入方式(串行 or 并行)
-
MLP 设计(△h)
2、Soft Prompts(软提示):
-
嵌入方式(Prompt-tuning, Prefix-Tuning, P-Tuning)
-
Prompt 微调方法(手工生成 or 连续可微优化)
3、Reparametrization-based(基于重参数方法):
-
缩放因子(Scale: Rank r)
-
模型参数/模块类型(如:WQ, WV)
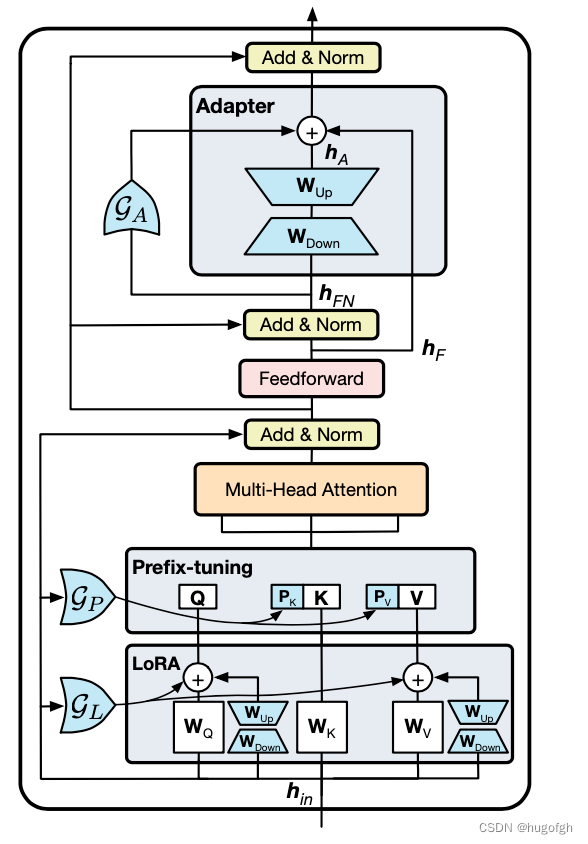
(IA)3 极简主义增量训练方法
通过学习向量来对激活层加权进行缩放,Infused Adapter by Inhibiting and Amplifying Inner Activations。
与LoRA相似,IA3具有许多相同的优势
-
通过大幅减少可训练参数的数量使微调更加高效。(对于T0,一个使用IA3模型仅有大约0.01%的可训练参数,而即使是LoRA也有大于0.1%的可训练参数)
-
原始的预训练权重保持冻结状态,这意味着您可以构建多个轻量且便携的IA3模型,用于各种基于它们构建的下游任务。
-
进行微调的模型的性能与完全微调模型的性能相媲美。
-
不会增加推理延迟,因为适配器权重可以与基础模型合并。
-
可以应用于神经网络中的任何权重矩阵子集,以减少可训练参数的数量。根据作者的实现,IA3权重被添加到Transformer模型的K、V和前馈层中。具体来说,对于Transformer模型,IA3权重被添加到K和V层的输出,以及每个Transformer块中第二个前馈层的输入。
鉴于注入IA3参数的目标层,可根据权重矩阵的大小确定可训练参数的数量。

大模型高效微调技术未来发展趋势
-
更高效的参数优化: 研究将继续寻找更高效的方法来微调大型模型,减少所需的参数量和计算资源。这可能包括更先进的参数共享策略和更高效的 LoRA 等技术。
-
适应性和灵活性的提升: 微调方法将更加灵活和适应性强,能够针对不同类型的任务和数据集进行优化。
-
跨模态和多任务学习: PEFT可能会扩展到跨模态(如结合文本、图像和声音的模型)和多任务学习领域,
-
以增强模型处理不同类型数据和执行多种任务的能力。
-
模型压缩和加速: 随着对边缘设备和移动设备部署AI模型的需求增加,PEFT技术可能会重点关注模型压缩
-
和推理速度的提升。
-
低资源语言和任务的支持: 将PEFT技术应用于低资源语言和特定领域任务,提供更广泛的语言和任务覆盖。
大模型量化技术
模型显存占用
模型参数与显存占用计算方法
为了详细说明模型的参数数量和每个参数在显存中占用的空间大小,我们以facebook OPT-6.7B模型为例。 逐步推理计算过程:
-
估计参数总量:OPT-6.7B模型指一个含有大约6.7 Billion(67亿)个参数的模型。
-
计算单个参数的显存占用:OPT-6.7B模型默认使用Float16,每个参数占用16位(即2字节)的显存。
-
计算总显存占用=参数总量×每个参数的显存占用。
-
代入公式计算:67亿参数×2字节/参数=134亿字节=13.4×109字节
-
换算单位:1GB = 230B ≈ 109字节
综上,OPT-6.7B以float16精度加载到GPU需要使用大约13.5GB显存。 如果使用int8精度,则只需要大约7GB显存。
只用来推理,float32精度加载,占用4个字节。所以一个粗略的计算方法就是,每10亿个参数,占用4G显存。如果用来训练,需要的显存是至少推理的5倍,到十几倍,还跟batch_size有关。
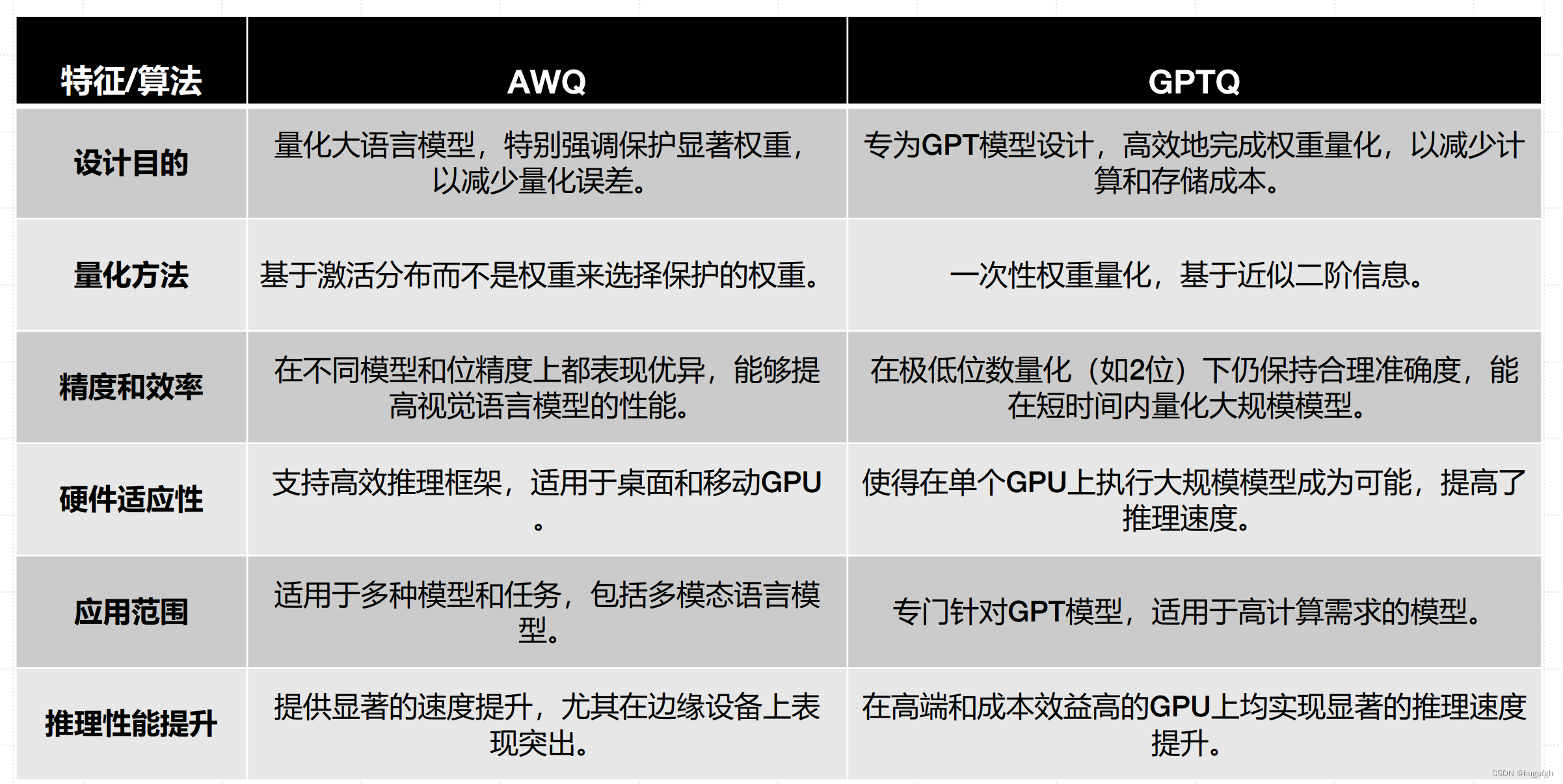
GPTQ:专为GPT设计的模型量化算法
GPTQ:Accurate Post-Training Quantization for Generative Pre-trained Transformers是一个高效、精准的量化技术,特别适用于大规模GPT模型,能够在显著降低模型大小和计算需求的同时,保持高准确度和推理速度。
GPTQ算法具有以下技术特点:
-
专为GPT模型设计:GPTQ针对大规模GPT模型(如1750亿参数规模的模型)进行优化,解决了这类模型因规模庞大导致的高计算和存储成本问题。
-
一次性权重量化方法:GPTQ是一种基于近似二阶信息的权重量化方法,能够在一次处理中完成模型的量化。
-
高效率:GPTQ能在大约四个GPU小时内完成1750亿参数的GPT模型的量化。
-
低位宽量化:通过将权重位宽降至每个权重3或4位,GPTQ显著减少了模型的大小。
-
准确度保持:即便在进行显著的位宽减少后,GPTQ也能保持与未压缩模型相近的准确度,减少性能损失。
-
支持极端量化:GPTQ还可以实现更极端的量化,如2位或三元量化,同时保持合理的准确度。
-
推理速度提升:使用GPTQ量化的模型在高端GPU(如NVIDIA A100)上实现了大约3.25倍的推理速度提升, 在成本效益更高的GPU(如NVIDIA A6000)上实现了大约4.5倍的速度提升。
-
适用于单GPU环境:GPTQ使得在单个GPU内执行大规模模型的生成推理成为可能,显著降低了部署这类模 型的硬件要求。
GPTQ量化算法实现原理
-
关键逻辑
使用存储在Cholesky(切尔斯基)分解中的逆Hessian(海森) 信息量化连续列的块(加粗表示),并在步骤结束时更新剩余的权重 (蓝色表示),在每个块内递归(白色中间块)地应用量化过程。
-
关键步骤
-
块量化:选择一块连续的列(在图中加粗表示),并将其作为当前步骤 的量化目标。
-
使用Cholesky分解:利用Cholesky分解得到的逆Hessian信息来量化选定 的块。Cholesky分解提供了一种数值稳定的方法来处理逆矩阵,这对于维 持量化过程的准确性至关重要。
-
权重更新:在每个量化步骤的最后,更新剩余的权重(在图中以蓝色表 示)。这个步骤确保了整个量化过程的连贯性和精确性。
-
递归量化:在每个选定的块内部,量化过程是递归应用的。这意味着量 化过程首先聚焦于一个较小的子块,然后逐步扩展到整个块。 通过这种方式,GPTQ方法能够在保持高度精度的同时,高效地处理大量 的权重,这对于大型模型的量化至关重要。这种策略特别适用于处理大 型、复杂的模型,如GPT系列,其中权重数量巨大,且量化过程需要特别 小心以避免精度损失。
AWQ:激活感知权重量化算法
激活感知权重量化(Activation-aware Weight Quantization, AWQ)。
激活感知权重量化(AWQ)算法,其原理不是对模型中的所有权重进行量化,而是仅保留小部分(1%)对LLM性能至关重要的权重。 其算法主要特点如下:
-
低位权重量化:AWQ专为大型语言模型(LLMs)设计,支持低位(即少位数)的权重量化,有效减少模型大小。
-
重点保护显著权重:AWQ基于权重重要性不均的观察,只需保护大约1%的显著权重,即可显著减少量化误差。
-
观察激活而非权重:在确定哪些权重是显著的过程中,AWQ通过观察激活分布而非权重分布来进行。
-
无需反向传播或重构:AWQ不依赖于复杂的反向传播或重构过程,因此能够更好地保持模型的泛化能力,避免对特定数据集的过拟合。
-
适用于多种模型和任务:AWQ在多种语言建模任务和领域特定基准测试中表现出色,包括指令调整的语言模型和多模态语言模型。
-
高效的推理框架:与AWQ配套的是一个为LLMs量身定做的高效推理框架,提供显著的速度提升,适用于桌面和移动GPU。
-
支持边缘设备部署:这种方法支持在内存和计算能力有限的边缘设备(如NVIDIA Jetson Orin 64GB)上部署大型模型,如70B Llama-2模型。
量化算法对比:AWQ vs GPTQ
BitsAndBytes(BnB)量化软件包

微调代码示例
# 定义全局变量和参数
model_name_or_path = 'THUDM/chatglm3-6b' # 模型ID或本地路径
train_data_path = 'HasturOfficial/adgen' # 训练数据路径
eval_data_path = None # 验证数据路径,如果没有则设置为None
seed = 8 # 随机种子
max_input_length = 512 # 输入的最大长度
max_output_length = 1536 # 输出的最大长度
lora_rank = 4 # LoRA秩
lora_alpha = 32 # LoRA alpha值
lora_dropout = 0.05 # LoRA Dropout率
resume_from_checkpoint = None # 如果从checkpoint恢复训练,指定路径
prompt_text = '' # 所有数据前的指令文本
compute_dtype = 'fp32' # 计算数据类型(fp32, fp16, bf16)
from transformers import AutoTokenizer
# revision='b098244' 版本对应的 ChatGLM3-6B 设置 use_reentrant=False
# 最新版本 use_reentrant 被设置为 True,会增加不必要的显存开销
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path,
trust_remote_code=True,
revision='b098244')
## 训练模型
### 加载 ChatGLM3-6B 量化模型
#使用 `nf4` 量化数据类型加载模型,开启双量化配置,以`bf16`混合精度训练,预估显存占用接近4GB
from transformers import AutoModel, BitsAndBytesConfig
_compute_dtype_map = {
'fp32': torch.float32,
'fp16': torch.float16,
'bf16': torch.bfloat16
}
# QLoRA 量化配置
q_config = BitsAndBytesConfig(load_in_4bit=True,
bnb_4bit_quant_type='nf4',
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=_compute_dtype_map['bf16'])
# revision='b098244' 版本对应的 ChatGLM3-6B 设置 use_reentrant=False
# 最新版本 use_reentrant 被设置为 True,会增加不必要的显存开销
model = AutoModel.from_pretrained(model_name_or_path,
quantization_config=q_config,
device_map='auto',
trust_remote_code=True,
revision='b098244')
# 预处理量化后的模型,使其可以支持低精度微调训练
from peft import TaskType, LoraConfig, get_peft_model, prepare_model_for_kbit_training
kbit_model = prepare_model_for_kbit_training(model)
#PEFT 适配模块设置
from peft.utils import TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING
#['query_key_value']
target_modules = TRANSFORMERS_MODELS_TO_LORA_TARGET_MODULES_MAPPING['chatglm']
### LoRA 适配器配置
lora_config = LoraConfig(
target_modules=target_modules,
r=lora_rank,
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
bias='none',
inference_mode=False,
task_type=TaskType.CAUSAL_LM
)
qlora_model = get_peft_model(kbit_model, lora_config)
qlora_model.print_trainable_parameters()
#训练超参数配置
#1个epoch表示对训练集的所有样本进行一次完整的训练。
# num_train_epochs 表示要完整进行多少个 epochs 的训练。
# 关于使用 num_train_epochs 时,
# 训练总步数 steps 的计算方法训练总步数:
# total_steps = steps/epoch * num_train_epochs
# 每个epoch的训练步数:steps/epoch = num_train_examples / (batch_size * gradient_accumulation_steps)
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir=f"models/{model_name_or_path}", # 输出目录
per_device_train_batch_size=16, # 每个设备的训练批量大小
gradient_accumulation_steps=4, # 梯度累积步数
# per_device_eval_batch_size=8, # 每个设备的评估批量大小
learning_rate=1e-3, # 学习率
num_train_epochs=1, # 训练轮数
lr_scheduler_type="linear", # 学习率调度器类型
warmup_ratio=0.1, # 预热比例
logging_steps=10, # 日志记录步数
save_strategy="steps", # 模型保存策略
save_steps=100, # 模型保存步数
# evaluation_strategy="steps", # 评估策略
# eval_steps=500, # 评估步数
optim="adamw_torch", # 优化器类型
fp16=True, # 是否使用混合精度训练
)
trainer = Trainer(
model=qlora_model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=data_collator
)
#开始训练
trainer.train()















 1307
1307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









