







Attention
注意力机制的特点和优势
-
注意力机制有助于克服循环神经网络(RNNs)的一些挑战,例如输入序列长度增加时性能下降和顺序处理输入导致的计算效率低下。
-
在自然语言处理(NLP)、计算机视觉(Computer Vision)、跨模态任务和推荐系统等多个领域中,注意力机制已成为多项任务中的最先进模型,取得了显著的性能提升。
-
注意力机制不仅可以提高主要任务的性能,还具有其他优势。它们被广泛用于提高神经网络的可解释性,帮助解释模型的决策过程,使得原本被认为是黑盒模型的神经网络变得更易解释。这对于人们对机器学习模型的公平性、可追溯性和透明度的关注具有重要意义。

-
查询(Q):当前词的特征向量。
-
键(K):所有词的特征向量,用于与查询向量进行匹配。
-
值(V):所有词的特征向量,包含需要加权求和的信息。
利用词向量,经过线性变换生成Q、K、V。
其中线性变换的选取是通过训练过程自动学习得到的。具体来说,线性变换矩阵 WQ、WK和 WV 是模型的可训练参数,在训练过程中通过反向传播和梯度下降来更新。
Q=WQ*输入序列的嵌入向量
K=WK*输入序列的嵌入向量
V=WV*输入序列的嵌入向量
1. 查询(Query, Q)
查询(Query)向量表示当前时间步或位置的输入数据,用于与其他输入数据进行对比,以确定与其相关的重要信息。它可以理解为当前需要注意的内容。
2. 键(Key, K)
键(Key)向量表示整个输入序列中每个时间步或位置的特征,用于与查询向量进行匹配。键向量用于计算输入数据之间的相似度,帮助确定哪些部分应该受到关注。
3. 值(Value, V)
值(Value)向量表示与键向量相关联的信息,即需要通过注意力机制获取的实际数据。值向量包含了与输入数据相关的具体信息,最终被注意力机制用来生成输出。
在注意力机制(Attention Mechanism)中,Q、K、V分别代表查询(Query)、键(Key)和值(Value)。这些概念是理解和实现注意力机制的基础,尤其是在Transformer架构中,如BERT、GPT等模型。
注意力机制的工作流程
注意力机制通过以下步骤来计算输出:

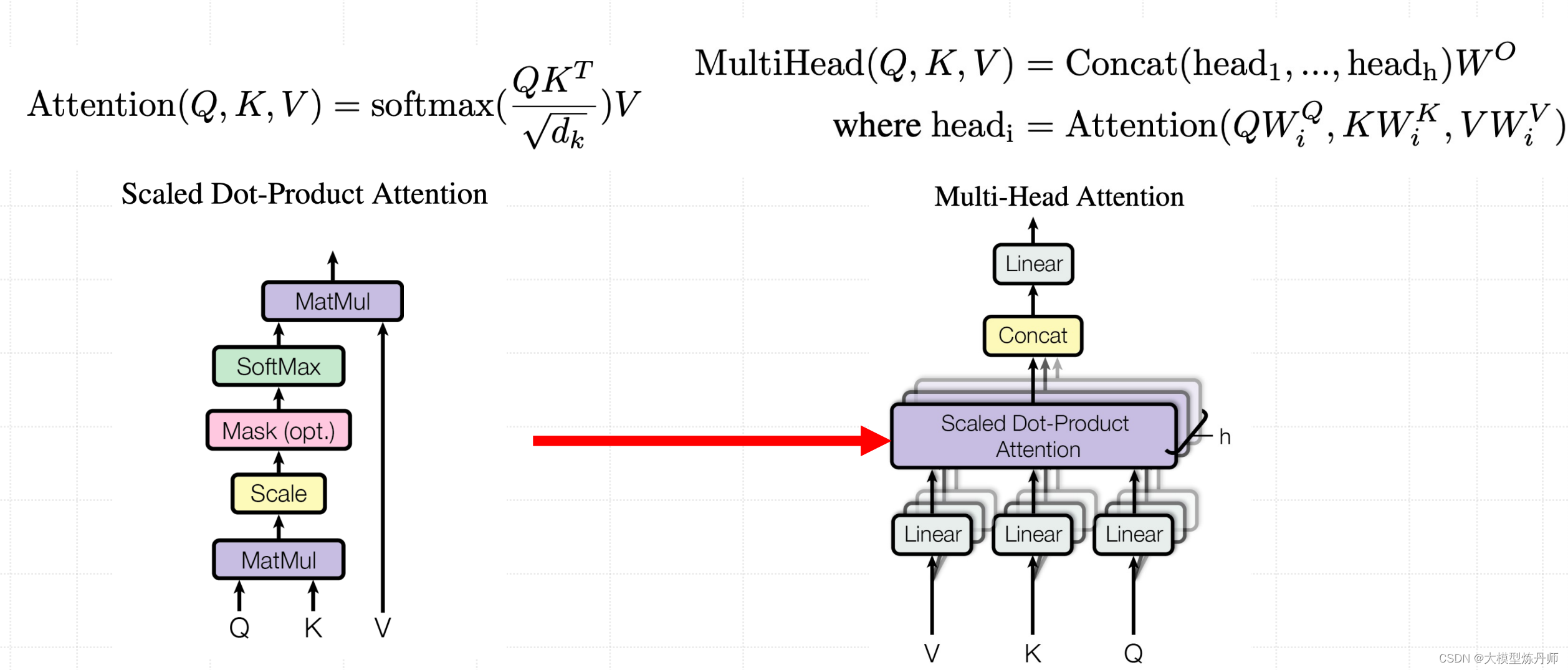
多头注意力机制(Multi-Head Attention)
为了捕捉输入序列中不同子空间的信息,Transformer模型引入了多头注意力机制。它通过并行计算多个独立的注意力头,每个头都有自己的查询、键和值向量,然后将所有头的输出连接起来,再通过线性变换得到最终结果。
总结
-
查询(Query, Q):需要注意的信息,代表当前时间步或位置的输入数据。
-
键(Key, K):输入序列中每个时间步或位置的特征,用于与查询向量匹配。
-
值(Value, V):与键向量相关联的信息,实际需要获取的内容。
注意力机制通过计算查询和键之间的相似度分数,利用这些分数加权求和值向量,从而确定哪些输入部分对当前输出最重要。多头注意力机制进一步增强了模型的表示能力,能够更好地捕捉输入序列中的复杂关系。
Self-Attention
在自注意力机制(Self-Attention Mechanism)中的“自”指的是,查询(Query)、键(Key)和值(Value)这三个向量都来自同一个输入序列。这与传统的注意力机制不同,后者通常是在不同的输入序列之间计算注意力。例如,在机器翻译中,编码器和解码器之间的注意力机制中,查询来自解码器的隐藏状态,而键和值来自编码器的隐藏状态。


Transformer
原理

Transformer 中单词的输入表示 x由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
transformer是一个Encoder-Decoder结构,其中Encode由多头注意力和前馈神经网络组成,每一层后面都接一个Add和Norm,即残差连接(用于防止网络退化)和正则化,正则化会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数。
Decoder
-
包含两个多头注意力层。
-
第一个多头注意力 层采用了 Masked 掩码操作。
-
第二个多头注意力 层的K, V矩阵使用 Encoder 的编码信息矩阵C进行计算,而Q使用上一个 Decoder block 的输出计算。
-
最后有一个 Softmax 层计算下一个翻译单词的概率。
Self-Attention
Self-Attention 接收的是输入(单词的表示向量x组成的矩阵X) 或者上一个 Encoder block 的输出。而Q,K,V正是通过 Self-Attention 的输入进行线性变换得到的。

Multi-Head Attention 包含多个 Self-Attention 层,Multi-Head Attention 将多个self-attention的输出拼接在一起 (Concat),然后传入一个Linear层,得到 Multi-Head Attention 最终的输出Z。
Transformer架构的关键创新点包括:
-
编码器-解码器结构
-
自注意力机制:允许模型在序列的每个位置同时关注序列中的所有位置。
-
多头注意力:通过多个注意力头并行处理信息,增强模型的表达能力。
-
位置编码:为模型提供序列中单词的位置信息。
-
残差连接:帮助梯度在深层网络中流动,减少梯度消失问题。
-
层归一化:稳定训练过程,加快收敛。
GPT架构
GPT-4,以及其他GPT(Generative Pre-trained Transformer)系列模型,主要使用了解码器(Decoder)部分,而没有使用完整的Transformer架构中同时包含编码器(Encoder)和解码器(Decoder)的设计。
主要区别
Transformer 架构
-
编码器-解码器结构:原始的Transformer模型由编码器和解码器组成。编码器处理输入序列,生成中间表示;解码器则使用这些表示生成输出序列。
-
用途:主要用于机器翻译等需要处理成对输入输出序列的任务。
GPT 架构
-
解码器结构:GPT使用的是解码器部分的变体,旨在生成文本。输入序列通过解码器处理,直接生成输出。
-
自回归生成:GPT模型逐步生成文本,一个时间步生成一个词,生成的词再作为下一步的输入。
GPT-4 的架构
GPT-4延续了之前GPT模型的设计,主要由以下组件组成:
-
输入嵌入 (Input Embedding):
-
输入的词通过嵌入层转换为固定维度的向量表示。
-
-
位置编码 (Positional Encoding):
-
由于Transformer架构无法捕捉顺序信息,位置编码被加到输入嵌入中,以便模型了解每个词的位置。
-
-
多头自注意力机制 (Multi-Head Self-Attention):
-
在解码器中,每个位置的表示通过自注意力机制与其他位置的表示相互作用,从而捕捉全局上下文信息。
-
-
残差连接和层归一化 (Residual Connections and Layer Normalization):
-
通过残差连接和层归一化,缓解梯度消失问题,并使训练更稳定。
-
-
前馈神经网络 (Feed-Forward Network):
-
对每个位置的向量进行独立的非线性变换。
-
-
输出层 (Output Layer):
-
解码器的输出经过线性变换和softmax操作,生成每个位置上的词汇分布。
-
GPT-4 工作流程
-
输入预处理:
-
输入文本通过词嵌入层和位置编码,转化为向量序列。
-
-
多层解码器处理:
-
输入向量序列通过多层解码器处理。每层包括多头自注意力机制、前馈神经网络、残差连接和层归一化。
-
-
逐步生成输出:
-
模型逐步生成输出文本,一个时间步生成一个词,每次生成的词作为下一时间步的输入。
-
总结
GPT-4只使用了解码器部分,而没有使用完整的编码器-解码器结构。这使得GPT-4能够高效地进行文本生成任务,如对话、文章写作和代码生成等。通过自回归生成机制,GPT-4能够基于给定的上下文生成连贯的长文本。















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









