






Swin Transformer: Hierarchical vision transformer using shifted windows (基于移动窗口的层级式的Vision Transformer)
- S w i n Swin Swin:来自于 S h i f t e d Shifted Shifted W i n d o w s Windows Windows 移动窗口;
- H i e r a r c h i c a l Hierarchical Hierarchical :让 V i s i o n Vision Vision T r a n s f o r m e r Transformer Transformer像卷积神经网络一样,做层级式的特征提取,从而提取多尺度的特征;
S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 是 I C C V 21 ICCV 21 ICCV21 的最佳论文,它之所以能有这么大的影响力,是因为在 V i T ViT ViT 证明了 T r a n s f o r m e r Transformer Transformer 可以用在视觉领域之后, S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 通过在一系列视觉任务上的强大表现 ,进一步证明了 T r a n s f o r m e r Transformer Transformer 是可以在视觉领域取得广泛应用的。
一、Swin Transformer 的前向过程:
1、数据预处理
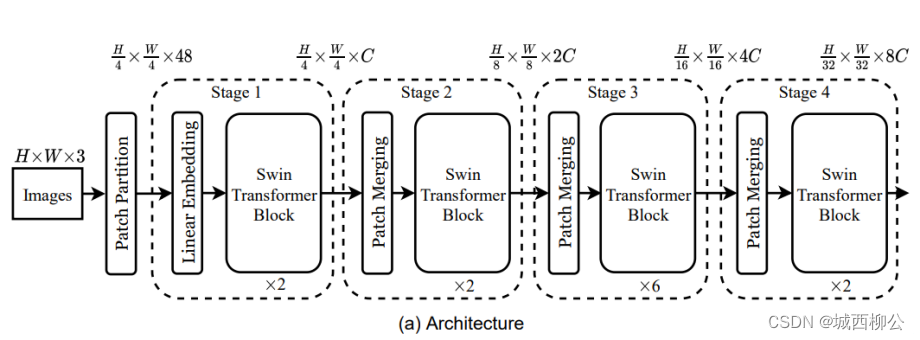
假设输入图像大小为: 224 ⋅ 224 ⋅ 3 224 \cdot 224 \cdot 3 224⋅224⋅3 。
- 第一步就是把图片打成若干个 p a t c h patch patch
1.1 Patch Partition
S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 的 p a t c h patch patch s i z e size size 是 4 ∗ 4 4 * 4 4∗4( V i T ViT ViT 的 patch size是 16 ∗ 16 16 *16 16∗16);因此,经过 P a t c h Patch Patch P a r t i t i o n Partition Partition 将输入图像打成 若干个 p a t c h patch patch 之后,得到图片的尺寸是 56 ⋅ 56 ⋅ 48 56 \cdot 56 \cdot 48 56⋅56⋅48 ,其中 224 224 224 ÷ \div ÷ 4 4 4 = 56 56 56 ,因为 p a t c h patch patch s i z e size size = 4 4 4,则向量的维度 4 ⋅ 4 ⋅ 3 = 48 4 \cdot 4 \cdot 3= 48 4⋅4⋅3=48 ;具体操作如下:
- 第二步就是把输入向量的长度变成一个预先设置好的值
1.2 Linear Embedding
在 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer里将这个向量长度的超参数设为 c c c,本文以 S w i n Swin Swin t i n y tiny tiny 网络为例, c c c = 96 96 96;具体操作如下:
因此经过 L i n e a r Linear Linear E m b e d d i n g Embedding Embedding 之后,输入的尺寸就变成了 56 ∗ 56 ∗ 96 56*56*96 56∗56∗96,前面的 56 ∗ 56 56*56 56∗56 就会拉直变成 3136 3136 3136 ,变成了序列长度,后面的 96 96 96 就变成了每一个token向量的维度(即输入有 3136 3136 3136 个单词,每个单词又由 96 96 96 维的向量表示),其实 P a t c h Patch Patch P a r t i t i o n Partition Partition 和 L i n e a r Linear Linear E m b e d d i n g Embedding Embedding 就相当于是 V i T ViT ViT 里的 P a t c h Patch Patch P r o j e c t i o n Projection Projection 操作,而这个操作在代码里也是用一次卷积操作就完成了。
2、特征提取
- 第三步就是基于窗口的自注意力计算
2.1 Swin Transformer Block
图1中
s
t
a
g
e
1
stage1
stage1 模块的
S
w
i
n
g
Swing
Swing
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer
B
l
o
c
k
Block
Block 是基于窗口计算自注意力的,在这里我们先暂时不考虑
S
w
i
n
g
Swing
Swing
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer
B
l
o
c
k
Block
Block 里的具体操作(后面会有详细的讲解),只关注它的输入和输出。
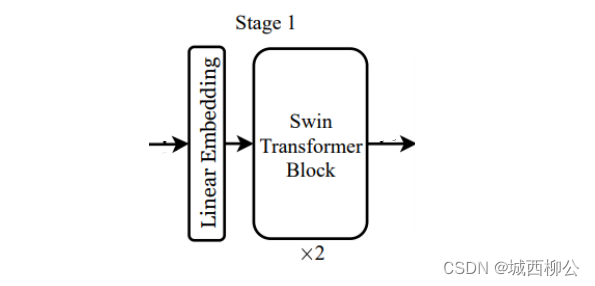
对于 T r a n s f o r m e r Transformer Transformer 来说,在不做其他约束的情况下, T r a n s f o r m e r Transformer Transformer输入的序列长度是多少,输出的序列长度也是多少,这是 T r a n s f o r m e r Transformer Transformer 的特性。所以,在 s t a g e 1 stage1 stage1 中经过 2 2 2 次 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer B l o c k Block Block 之后,输出还是 56 ∗ 56 ∗ 96 56 * 56 * 96 56∗56∗96 ,如图2。
- 第四步就是池化操作
若要获取多尺度的特征信息,就要像卷积神经网络一样构建一个层级式的 T r a n s f o r m e r Transformer Transformer,也就是说,需要有一个类似于池化的操作,因此 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 提出了 P a t c h Patch Patch M e r g i n g Merging Merging。
2.2 Patch Merging
-
P
a
t
c
h
Patch
Patch
M
e
r
g
i
n
g
Merging
Merging:把临近的小
p
a
t
c
h
patch
patch 合并成一个 大
p
a
t
c
h
patch
patch,从而得到与
m
a
x
p
o
o
l
i
n
g
maxpooling
maxpooling 下采样一样的效果。
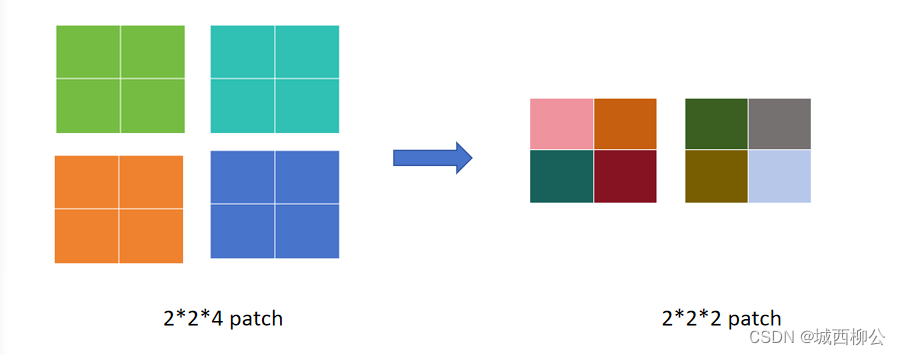
图3. Patch Merging 示意图
具体操作如下(以下采样2倍为例):
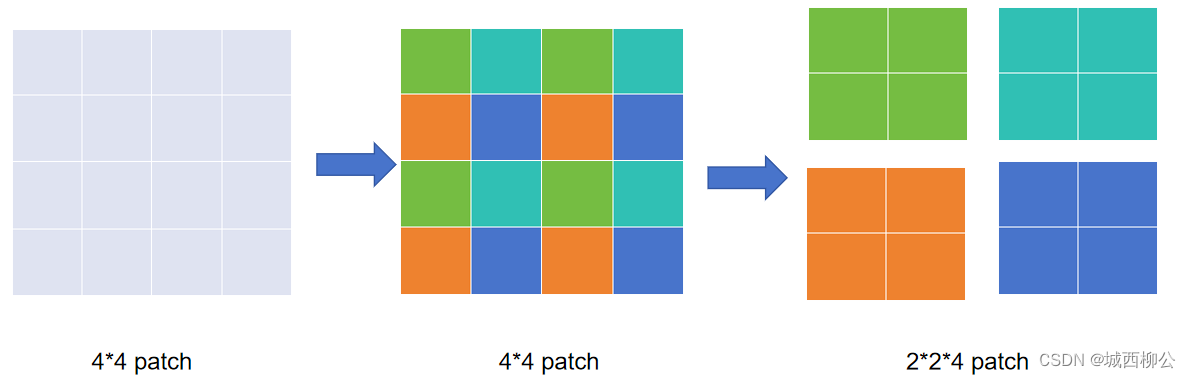
- 由于下采样倍数为 2 2 2,因此在采样时每隔一个 p a t c h patch patch 选一个,如上图4所示。
- 同样颜色的 p a t c h patch patch 会被 m e r g e merge merge 到一起;
- 所有 p a t c h patch patch 采样结束之后,原来的一个张量就变成了四个张量,即所有的绿色 m e r g e merge merge 到一起,所有的青色 m e r g e merge merge 到一起,所有的橙色 m e r g e merge merge 到一起,所有的蓝色 m e r g e merge merge 到一起。
- 如果原张量的维度是 h h h * w w w * c c c,经过 P a t c h Patch Patch M e r g i n g Merging Merging后就得到了 4 4 4 个张量,每个张量的大小是 h / 2 h/2 h/2、 w / 2 w/2 w/2,尺寸缩小了一倍。
- 最后将这四个张量在 c c c 的维度上拼接起来,张量的大小就变成了 h / 2 h/2 h/2 * w / 2 w/2 w/2 * 4 c 4c 4c,相当于用空间上的维度换了更多的通道数。
上述整个过程就是 P a t c h Patch Patch M e r g i n g Merging Merging,通过这个操作,就把原来一个大的张量变小了,就像卷积神经网络里的池化操作一样。
-
为了与卷积神经网络下采样前后的通道倍数保持一致,使用 1 ∗ 1 1*1 1∗1 的卷积对通道数进行降维。
- 不论是 V G G VGG VGG 还是 R e s n e t Resnet Resnet,一般在池化操作降维之后,通道数都会翻倍,即从 128 128 128 变成 256 256 256,从 256 256 256 再变成 512 512 512 ),所以 S w i n g Swing Swing T r a n s f o r m e r Transformer Transformer 也想让 P a t c h Patch Patch M e r g i n g Merging Merging后的通道数是之前的 2 2 2 倍,而不是上面的 4 4 4 倍。
- 因此在
P
a
t
c
h
Patch
Patch
M
e
r
g
i
n
g
Merging
Merging后紧接着又做了一次操作,即在
c
c
c 的维度上用一个
1
∗
1
1*1
1∗1 的卷积,把通道数降下来变成
2
∗
c
2 * c
2∗c,通过这个操作就能把原来一个大小为
h
h
h *
w
w
w *
c
c
c 的张量变成
h
/
2
h/2
h/2 *
w
/
2
w/2
w/2 *
2
c
2c
2c
的张量,也就是说空间上尺寸减半,在通道上翻倍,这样就跟卷积神经网络一 一对应起来了。
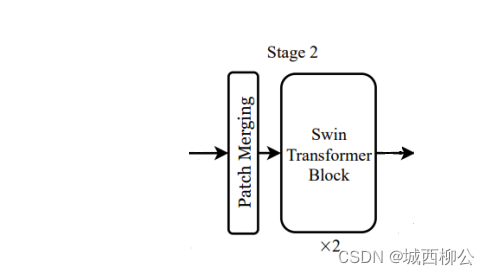
图6. stage 2
-
s t a g e 1 stage1 stage1 的输出,经过 s t a g e 2 stage2 stage2 的 P a t c h M e r g i n g Patch Merging PatchMerging 操作之后,维度从 56 ∗ 56 ∗ 96 56*56*96 56∗56∗96 变成了 28 ∗ 28 ∗ 192 28*28*192 28∗28∗192 ,再经过 s t a g e 2 stage2 stage2 中的 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer B l o c k Block Block ,由于 T r a n s f o r m e r Transformer Transformer 前后维度不变,所以 s t a g e 2 stage2 stage2 的输出尺寸即为 28 ∗ 28 ∗ 192 28*28*192 28∗28∗192 ,依此类推, s t a g e 3 stage3 stage3 的输出维度为 14 ∗ 14 ∗ 384 14*14*384 14∗14∗384, s t a g e 4 stage4 stage4 的输出维度为 7 ∗ 7 ∗ 768 7*7*768 7∗7∗768 。
从这里可以看出, S w i n g Swing Swing T r a n s f o r m e r Transformer Transformer B l o c k Block Block 得到与卷积神经网络一样的层级式特征图,我们再回想一下, R e s n e t Resnet Resnet 残差网络的多尺寸的特征,就是经过每个残差阶段之后的输出的特征,其特征图大小也是 56 ∗ 56 56*56 56∗56 、 28 ∗ 28 28*28 28∗28、 14 ∗ 14 14*14 14∗14、 7 ∗ 7 7*7 7∗7。
- 最后:基于多尺度特征,根据不同的任务接入分类头、检测头、分割头等
- 分类:对最后一层特征图 7 ∗ 7 ∗ 768 7*7*768 7∗7∗768 进行全局池化操作( g l o b a l global global a v e r a g e average average p o l l i n g polling polling),得到 1 ∗ 768 1*768 1∗768 ,再接入 1000 1000 1000 类的全连接层,最终得到 1 ∗ 1000 1*1000 1∗1000 。
- 目标检测:在多个特征图后接入检测头;
- 目标分割:在多个特征图后接入分割头;
二、Swin Transformer Block:
下图为
S
w
i
n
Swin
Swin
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer
B
l
o
c
k
Block
Block 的结构图:
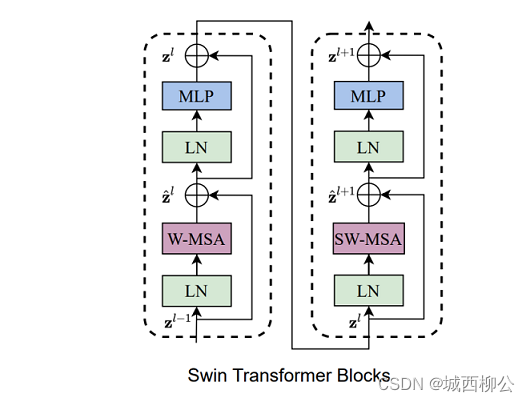
- S w i n Swin Swin T r a n s f o r m e r Transformer Transformer B l o c k Block Block 的输入数据先做一次 L a y e Laye Laye- N o r m Norm Norm,然后做 W W W- M S A MSA MSA(基于窗口的多头自注意力),接着在做一次 L a y e r Layer Layer- N o r m Norm Norm,最后经过 M L P MLP MLP 输出,到此左边的 b l o c k block block 就结束了;
- 接着,对左边 b l o c k block block 的输出,先做一次 L a y e r Layer Layer- N o r m Norm Norm,再进行 S h i f t e d Shifted Shifted w i n d o w window window 操作,也就是 S W SW SW- M S A MSA MSA (基于移动窗口的多头自注意力),然后再做一次 L a y e r Layer Layer- N o r m Norm Norm,最后经过 M L P MLP MLP 输出,到此右边的 b l o c k block block 结束;
- 这两个 b l o c k block block 加起来就是 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 的一个基本计算单元: S w i n Swin Swin T r a n s f o r m e r Transformer Transformer B l o c k Block Block;
这也就是为什么所有的 s t a g e stage stage 中的 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer B l o c k Block Block 的个数总是偶数,因为它始终都需要 2 2 2 个 b l o c k block block 连在一起作为一个基本单元,所以其数值一定是 2 2 2 的倍数。
1. Window
S
w
i
n
Swin
Swin
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer 的一个关键的设计因素,就是基于窗口的操作,接下来我们来具体看看如何划分
w
i
n
d
o
w
window
window 。
如下图9:
- S w i n Swin Swin T r a n s f o r m e r Transformer Transformer的 f e a t u r e feature feature m a p map map的最基本组成单元是 p a t c h patch patch,而每个 p a t c h patch patch 的大小为 4 4 4 * 4 4 4 ( p a t c h patch patch s i z e size size = 4 4 4);每个橙色的框是一个中型的计算单元,即 w i n d o w window window,而每个 w i n d o w window window 是由若干个 p a t c h patch patch 组成;
- 在 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 这篇论文里,默认一个 w i n d o w window window 由 7 ∗ 7 = 49 7 * 7 = 49 7∗7=49 个 p a t c h patch patch 组成。
1.1 Window的好处
S
w
i
n
Swin
Swin
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer 将第
L
L
L 层的输出特征图分成若干个小窗口,以窗口为基本的计算单元,则可以有效降低序列长度,从而减少计算的复杂度;我们拿
s
t
a
g
e
1
stage1
stage1 中的
S
w
i
n
Swin
Swin
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer
B
l
o
c
k
Block
Block 来举例,它的输入尺寸就是
56
∗
56
∗
96
56*56*96
56∗56∗96 ,将宽高
56
∗
56
56*56
56∗56 张量切成若干个不重叠的方格,如下图8。
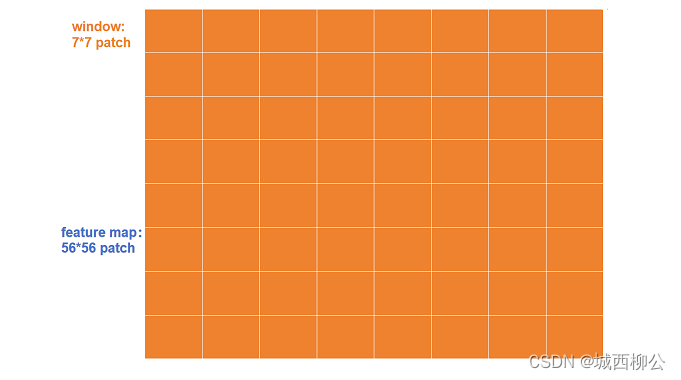
- 每一个橘黄色的方格就是一个窗口 w i n d o w window window ,但最小的计算单元并不是 w i n d o w window window,而是 p a t c h patch patch;因为每一个 w i n d o w window window 里包含了 m ∗ m m * m m∗m 个 p a t c h patch patch,在 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 中 m m m 默认为 7 7 7,即一个橘黄色的小方格里有 7 ∗ 7 = 49 7*7=49 7∗7=49 个 p a t c h patch patch;
- S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 的所有自注意力的计算都是在这些窗口 w i n d o w window window 里完成的,序列长度永远都是 7 ∗ 7 = 49 7*7=49 7∗7=49;
- 原来大的整体特征图到底里面会有多少个窗口呢?其实也就是 h h h、 w w w 方向上分别有 56 / 7 = 8 56/7= 8 56/7=8 个窗口,也就是一共 8 ∗ 8 = 64 8*8=64 8∗8=64 个窗口, S w i n Swin Swin T r a n s f o r m e r Transformer Transformer B l o c k Block Block 会在这 64 64 64个窗口里分别去算它们的自注意力。
接下来,我们来具体看看 w i n d o w window window 如何滑动:
2. Shifted Window
假如
S
w
i
n
Swin
Swin
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer
B
l
o
c
k
Block
Block 输入的
f
e
a
t
u
r
e
feature
feature
m
a
p
map
map大小为
8
∗
8
8*8
8∗8
p
a
t
c
h
patch
patch:
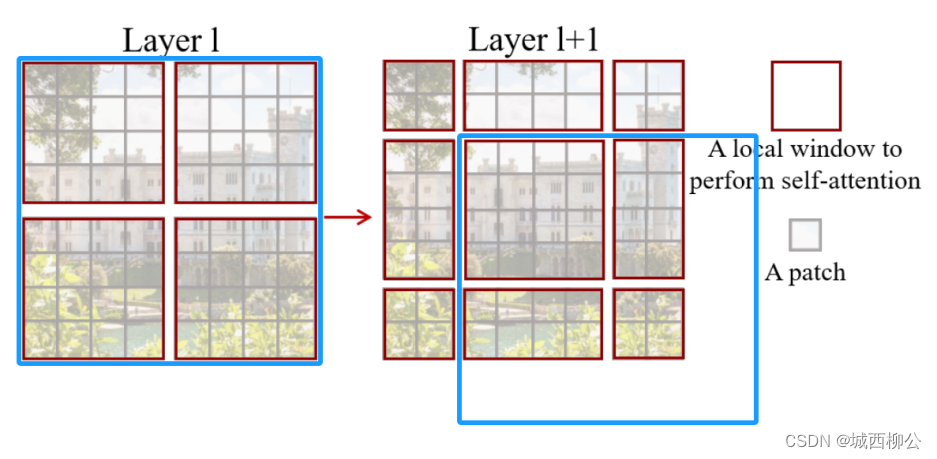
如果用一个大的蓝色框来描述 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 的第 L L L 层的输出特征图(图9左图):
-
首先将此 8 ∗ 8 8*8 8∗8 p a t c h patch patch的特征图分为 4 4 4 份;
-
其次蓝色框往右下角的方向整体移动 2 2 2 个 p a t c h patch patch,如上图9右图所示。
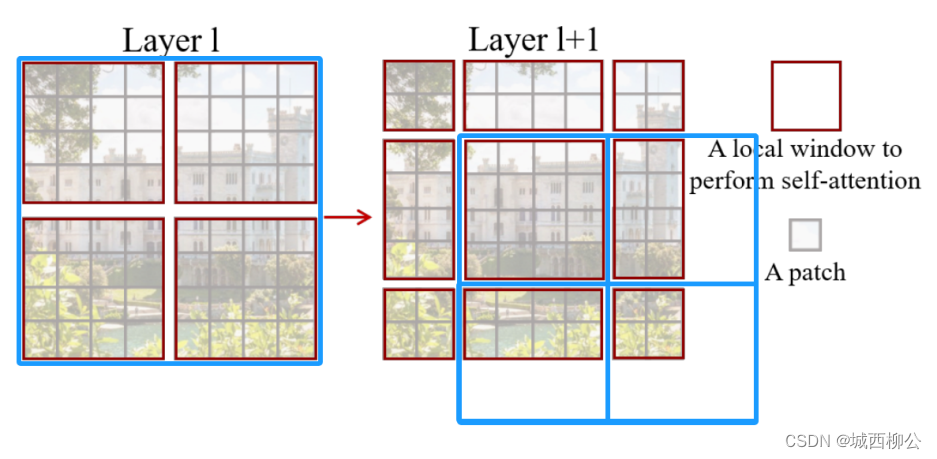
图10. -
在新的特征图里,再次将其分为 4 4 4 份,如上图10右图所示。
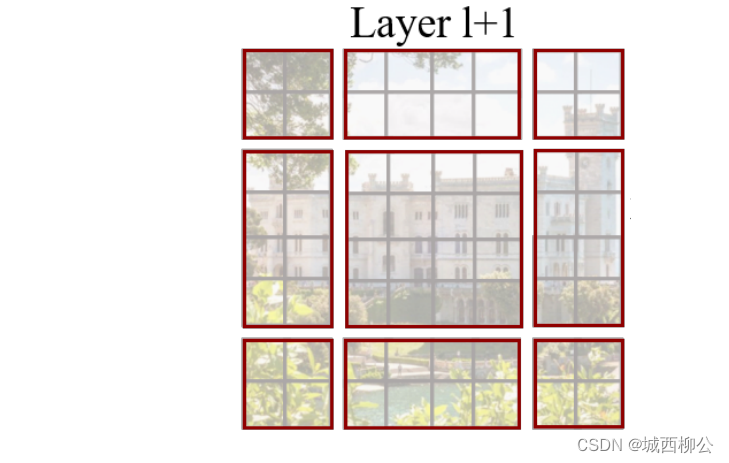
- S h i f t e d Shifted Shifted W i n d o w Window Window 完成后,得到最终的滑动窗口,如上图11。
滑动窗口的好处是窗口与窗口之间可以进行互动。如果按照以前 T r a n s f o r m e r Transformer Transformer 的方式(没有 s h i f t e d shifted shifted w i n d o w window window),这些窗口之间是互不重叠的,由于自注意力操作都是在 w i n d o w window window 里进行的,因此每个 w i n d o w window window 里的 p a t c h patch patch 就永远无法注意到其他 w i n d o w window window 里的 p a t c h patch patch 的信息,也就无法实现 T r a n s f o r m e r Transformer Transformer 的初衷(即 T r a n s f o r m e r Transformer Transformer 可获取前后上下文信息)。
2.2 Shifted Window Masking
为了提高移动窗口 S h i f t e d W i n d o w Shifted Window ShiftedWindow 的计算效率,作者采取了一种非常巧妙的 masking(掩码)的方式。
2.2.1 为什么需要cyclic shift
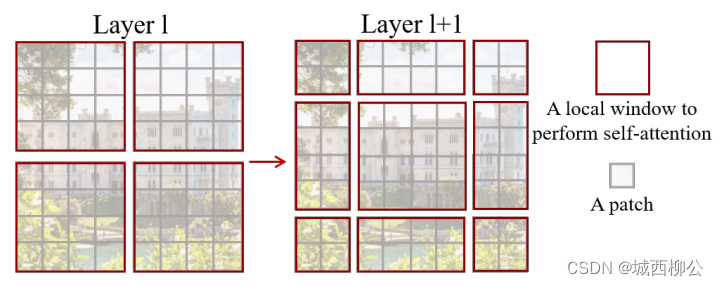
- 上图12是一个基础版本的移动窗口,就是把左边的窗口模式变成了右边的窗口方式;
- 虽然这种方式已经能够达到窗口和窗口之间的互相通信了,但会出现一个问题,在之前计算自注意力的时候,特征图上只有 4 4 4 个窗口,但是做完移动窗口操作之后得到了 9 9 9 个窗口,窗口的数量增加了,而且每个窗口里的元素大小不一,例如中间的窗口还是 4 ∗ 4 4*4 4∗4,它有 16 16 16 个 p a t c h patch patch,但是其他的窗口有的是 4 4 4 个 p a t c h patch patch,有的是 8 8 8 个 p a t c h patch patch,窗口大小不一样了,如果想要加速运算,就需要把这些小窗口全都 p a t c h patch patch 成同一尺寸;
- 有一个简单粗暴的解决方式:把一些尺寸小的窗口的周围 p a d pad pad 上 0 0 0 ,将它尺寸变成 4 ∗ 4 4*4 4∗4 的大小 (即中间窗口的大小),这样就有 9 9 9 个完全一样大的窗口,这样就可以每个窗口并行计算;
但是这样的话,相比之前的 4 4 4 个窗口,计算复杂度还是提升了,因为之前计算基于窗口的自注意力只需算 4 4 4 个窗口,然而现在需要去算 9 9 9个窗口,复杂度一下就提升了两倍多,那如何降低这个复杂度呢? 能不能保持之前的 4 4 4 个窗口去计算呢?
2.2.2 cyclic shift的原理是什么?
那怎么能让第二次移位完的窗口数量还是保持
4
4
4 个,而且每个窗口里的
p
a
t
c
h
patch
patch 数量也保持一致呢?作者提出了一个非常巧妙的掩码方式,如下图所示:
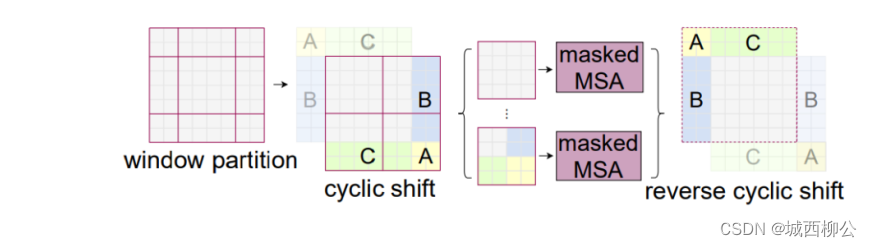
- 图13所示,当通过普通的移动窗口方式,得到 9 9 9 个窗口之后,不在这 9 9 9 个窗口上算自注意力,而是先做一次循环移位,即上图13的 c y c l i c cyclic cyclic s h i f t shift shift;
- 经过这次循环移位
(
c
y
c
l
i
c
(cyclic
(cyclic
s
h
i
f
t
)
shift)
shift) 之后,原来的窗口(虚线)就变成了现在窗口(实线),再把它分成四宫格的话,就又得到了
4
4
4 个窗口,也就是说,移位之前的窗口数是
4
4
4个,移位之后做一次循环移位得到的窗口数还是
4
4
4 个,这样窗口的数量就固定了,计算复杂度也就一样了。
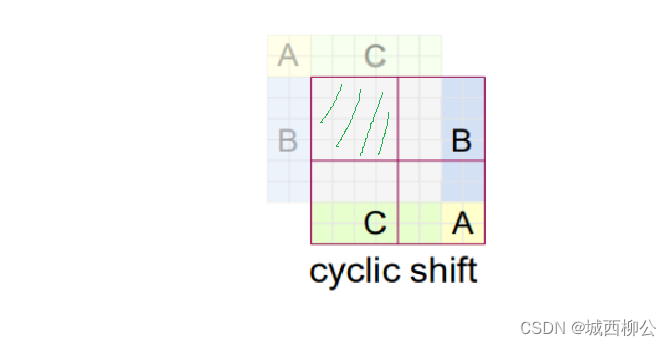
图14 - 那么新的问题就来了,对于上图15中的绿色划线区域来说,由于窗口里面的 p a t c h patch patch 都是原特征图的相邻数据,没有被打乱,可以直接做自注意力;
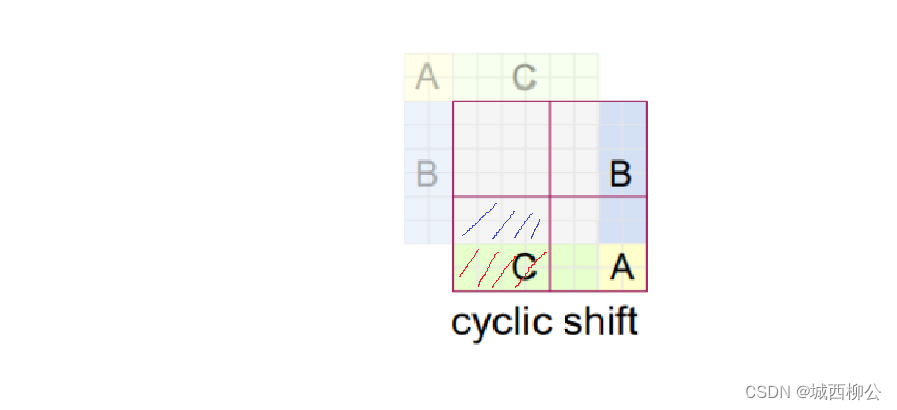
- 但是,如上图15,对于剩下的 3 3 3 个窗口 A 、 B 、 C A、B、C A、B、C 来说,它们里面的 p a t c h patch patch 是从别的地方移过来的,移过来的区域不应该去做自注意力,也就是说在一个 w i n d o w s windows windows 里,移动过来的区域与移动前的区域(即划线部分)不应该有什么太大的联系,例如:上图15中的原始C区域,如果它代表的是天空的特征,蓝色区域代表的是地面的特征,经过移动之后,天空的特征在地面特征之下了,这种情况明显是不符合常理的,所以在左下角这个窗口做自注意力计算时,蓝色划线区域不应该和红色划线区域做自注意力。
如何解决这个问题呢?
解决这个问题需要一个很常规的操作,
S
w
i
n
Swin
Swin
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer 提供了Masking的方法,也就是掩码操作。
2.2.3 Masking如何实现?
具体实现如下:
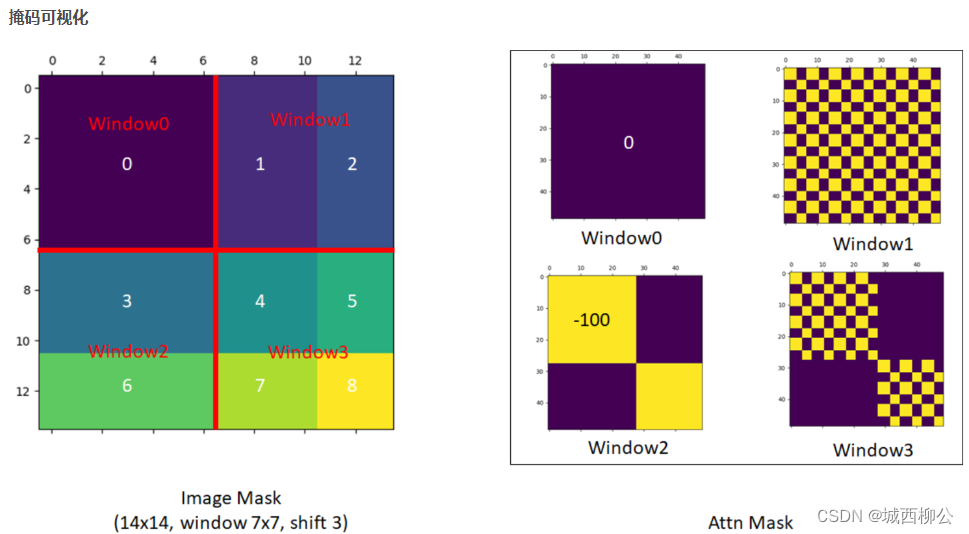
- 在 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer 这篇论文里,作者巧妙的设计了几种掩码的方式,使得 1 1 1 个窗口中的不同区域之间,只需一次前向过程就能把它们的自注意力算出来,而且每个窗口之间的计算都互不干扰,即 m a s k e d masked masked M u l t i Multi Multi- h e a d head head S e l f Self Self A t t e n t i o n ( M S A ,如图 13 ) Attention(MSA,如图13) Attention(MSA,如图13);
2.2.4 masked Multi-head Self-Attention(MSA)
以左下角的
w
i
n
d
o
w
2
window2
window2 为例,掩码操作具体如下:
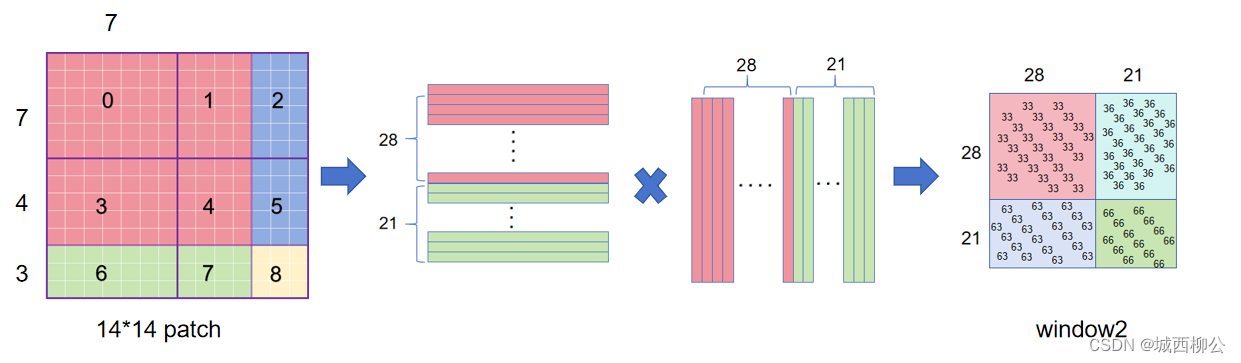
- 将 w i n d o w 2 window2 window2 的 p a t c h patch patch按照通道展平,再进行转置,二者再进行自注意力计算,最后得到自注意力的结果;
- 但是 3 3 3 区域和 6 6 6 区域不应该做自注意力计算,因此自注意力计算结果中 36 36 36 和 63 63 63 的区域应该舍弃。
使用mask进行操作:
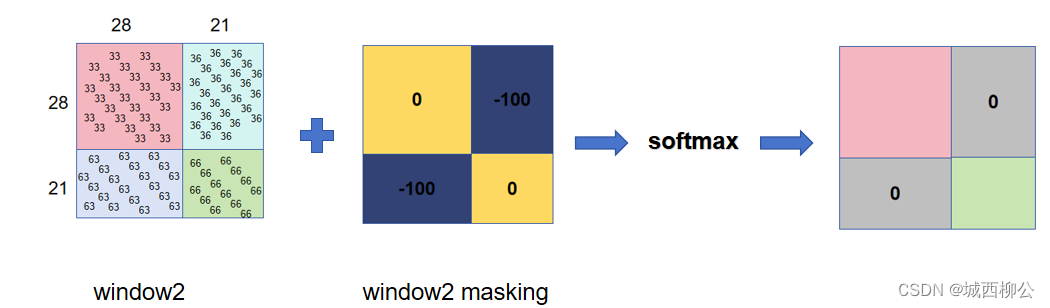
- 使用一个与 w i n d o w s 2 windows2 windows2结果区域尺寸一致的掩码 m a s k mask mask ,与自注意力结果相加,再进行 s o f t m a x softmax softmax,最后将不应该做自注意力计算的区域置为 0 0 0。
计算完了多头自注意力之后,还有最后一步把循环位移还原回去,也就是说需要把 A 、 B 、 C A、B、C A、B、C 再还原到原来的位置上去,这是因为保持原来特征图上特征的相对位置不变,进而保证整体图片的语义信息也是不变的,如果不把循环位移还原的话,就相当于在做 T r a n s f o r m e r Transformer Transformer 的操作之中,一直把输入特征图不停的往右下角移,这样图片的语义信息很有可能就被破坏掉了;
所以说整体而言,上图16介绍了一种高效的、批次的计算方式,比如说本来移动窗口之后得到了 9 9 9 个窗口,而且窗口之间的 p a t c h patch patch 数量每个都不一样,为了达到高效性,为了能够进行批次处理(并行处理),先进行一次循环位移,把 9 9 9 个窗口变成 4 4 4 个窗口,然后用巧妙的掩码方式让每个窗口之间能够合理地计算自注意力,最后再把算好的自注意力还原,就完成了基于移动窗口的自注意力计算。
3.基于窗口的自注意力模式的计算复杂度
基于窗口的自注意力计算方式能比全局的自注意力方式省多少呢?在
S
w
i
n
Swin
Swin
T
r
a
n
s
f
o
r
m
e
r
Transformer
Transformer 的论文里作者给出了一个大概估计的两个公式:
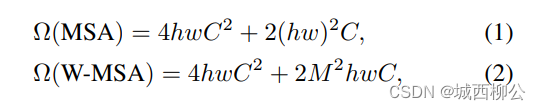
- 公式(1)对应的是标准的多头自注意力的计算复杂度(即 V i T ViT ViT 所使用的自注意力方式);
- 每一个特征图会有 h ∗ w h*w h∗w 个 p a t c h patch patch,在上述的例子里, h h h 和 w w w 分别都是 56 56 56, c c c 是特征的通道维度;
- 公式(2)对应的是基于窗口的自注意力计算的复杂度,这里的 M M M = 7 7 7,即表示一个 w i n d o w window window 在宽高上分别有几个 p a t c h patch patch 。
3.1 针对标准的多头自注意力
- 根据自注意力原理,如果现在有一个输入 a a a,自注意力首先把它变成 q 、 k 、 v q、 k、 v q、k、v 三个向量,这个过程其实就是原来的向量 a a a 分别乘了 3 3 3 个系数矩阵;
- 一旦得到 q q q 和 k k k 之后,再将它们相乘,最后得到 a t t e n t i o n attention attention,也就是自注意力矩阵;
- 有了自注意力之后,再和 v v v 做 1 1 1 次乘法,也相当于是做了 1 1 1 次加权;
- 因为是多头自注意力,所以最后需要
p
r
o
j
e
c
t
i
o
n
projection
projection
l
a
y
e
r
layer
layer,它会把向量的维度投射到我们想要的维度。
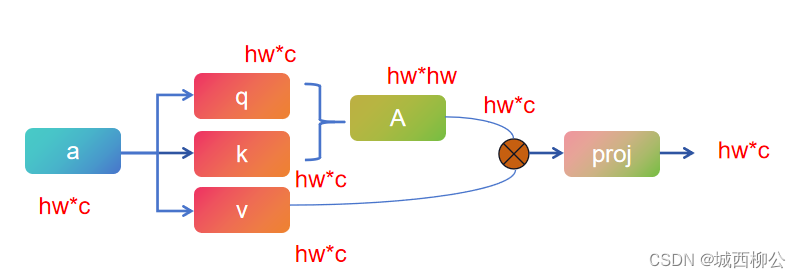
图19. 标准的多头自注意力流程
如果输入数据 a a a 维度为: h ∗ w ∗ c h*w*c h∗w∗c :
- 首先, q ( ) q() q()、 k ( ) k() k()、 v ( ) v() v() 是将 h ∗ w ∗ c h*w*c h∗w∗c 分别乘以一个 c ∗ c c*c c∗c 的系数矩阵,再分别输出 h ∗ w ∗ c h*w*c h∗w∗c ;所以 q ( ) q() q()、 k ( ) k() k()、 v ( ) v() v() 的复杂度分别是 h ∗ w ∗ c 2 h*w*c^2 h∗w∗c2 ,因此计算复杂度为: 3 ( h ∗ w ∗ c 2 ) 3 ( h*w*c^2) 3(h∗w∗c2) ;
- 其次,进行自注意力矩阵计算,即 q q q (即 h ∗ w ∗ c h*w*c h∗w∗c) 乘以 k k k 的转置( 即 c ∗ h ∗ w c*h*w c∗h∗w),输出 h w ∗ h w hw*hw hw∗hw ,则 A A A 的计算复杂度为: ( h ∗ w ) 2 ∗ c (h*w)^2*c (h∗w)2∗c;
- 接着,计算自注意力矩阵 A A A 和 v a l u e value value 的乘积,其计算复杂度为: ( h ∗ w ) 2 ∗ c (h*w)^2*c (h∗w)2∗c ;
- 最后,计算投射层,即 h ∗ w ∗ c h*w*c h∗w∗c 乘以 c ∗ c c*c c∗c 输出 h ∗ w ∗ c h*w*c h∗w∗c ,其计算复杂度为 h ∗ w ∗ c 2 h*w*c^2 h∗w∗c2;
将上述计算复杂度合并即可得到公式1:
3 ( h ∗ w ∗ c 2 ) + ( h ∗ w ) 2 ∗ c + ( h ∗ w ) 2 ∗ c + h ∗ w ∗ c 2 = 4 h w C 2 + 2 ( h w ) 2 C 3 ( h*w*c^2) + (h*w)^2*c + (h*w)^2*c + h*w*c^2 = 4hwC^2 + 2(hw)^2C 3(h∗w∗c2)+(h∗w)2∗c+(h∗w)2∗c+h∗w∗c2=4hwC2+2(hw)2C
3.2 针对基于窗口的多头自注意力
- 由于 S w i n Swin Swin T r a n s f o r m e r Transformer Transformer B l o c k Block Block 是在每个 w i n d o w window window 里计算多头自注意力,根据上述的标准多头自注意力计算复杂度的计算方式,只需将其高度和宽度 h ∗ w h * w h∗w ,改成窗口的大小 (即 M ∗ M M*M M∗M) 即可,也就是公式(1)中的 h h h 变成了 M M M, w w w 也变成了 M M M;
- 接着,代入公式(1)之后,即可得到一个 w i n d o w window window 多头自注意力的计算复杂度: 4 M 2 C 2 + 2 M 4 C 4 M^2 C^2 + 2 M^4 C 4M2C2+2M4C;而我们共有 ( h / M ) ∗ ( w / M ) (h/M) * (w/M) (h/M)∗(w/M) 个 w i n d o w window window,所以最终需要的计算复杂度为 ( h / M ) ∗ ( w / M ) ∗ ( 4 M 2 C 2 + 2 M 4 C ) (h/M) * (w/M) * (4 M^2 C^2 + 2 M^4 C) (h/M)∗(w/M)∗(4M2C2+2M4C) = 4 h w C 2 + 2 M 2 h w C 4hwC^2 + 2M^2hwC 4hwC2+2M2hwC ,即公式(2)。
对比公式(1)和公式(2),虽然这两个公式前面是一样的,后面从 ( h ∗ w ) 2 (h*w)^2 (h∗w)2 变成了 M 2 ∗ h ∗ w M^2 * h * w M2∗h∗w ,看起来好像差别不大,但如果我们带入具体的数字去计算就会发现,计算复杂度的差距是相当巨大的,假如 h ∗ w h*w h∗w = 56 ∗ 56 56*56 56∗56, M 2 = 7 ∗ 7 = 49 M^2 = 7 * 7 = 49 M2=7∗7=49,二者其实是相差了几十甚至上百倍的。















 1688
1688











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









