







随机森林是一种基于集成学习的机器学习算法,它通过组合多个决策树来进行分类和回归任务。随机森林在数据科学领域广泛应用,尤其在处理高维数据和大规模数据集时表现出色。本文将介绍随机森林算法的基本原理、优势以及如何解决决策树的缺点。
什么是随机森林算法?
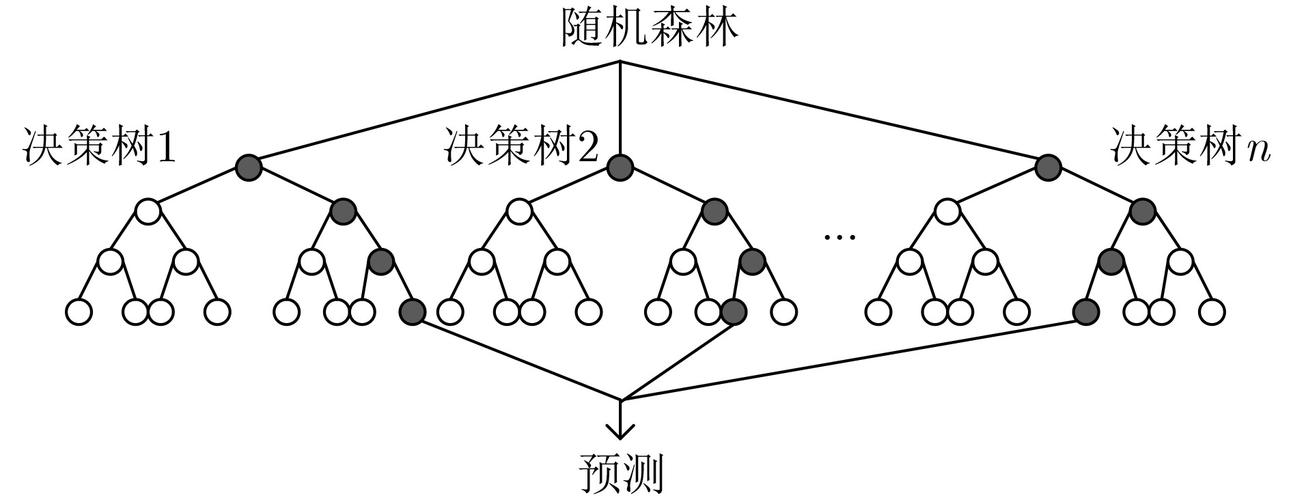
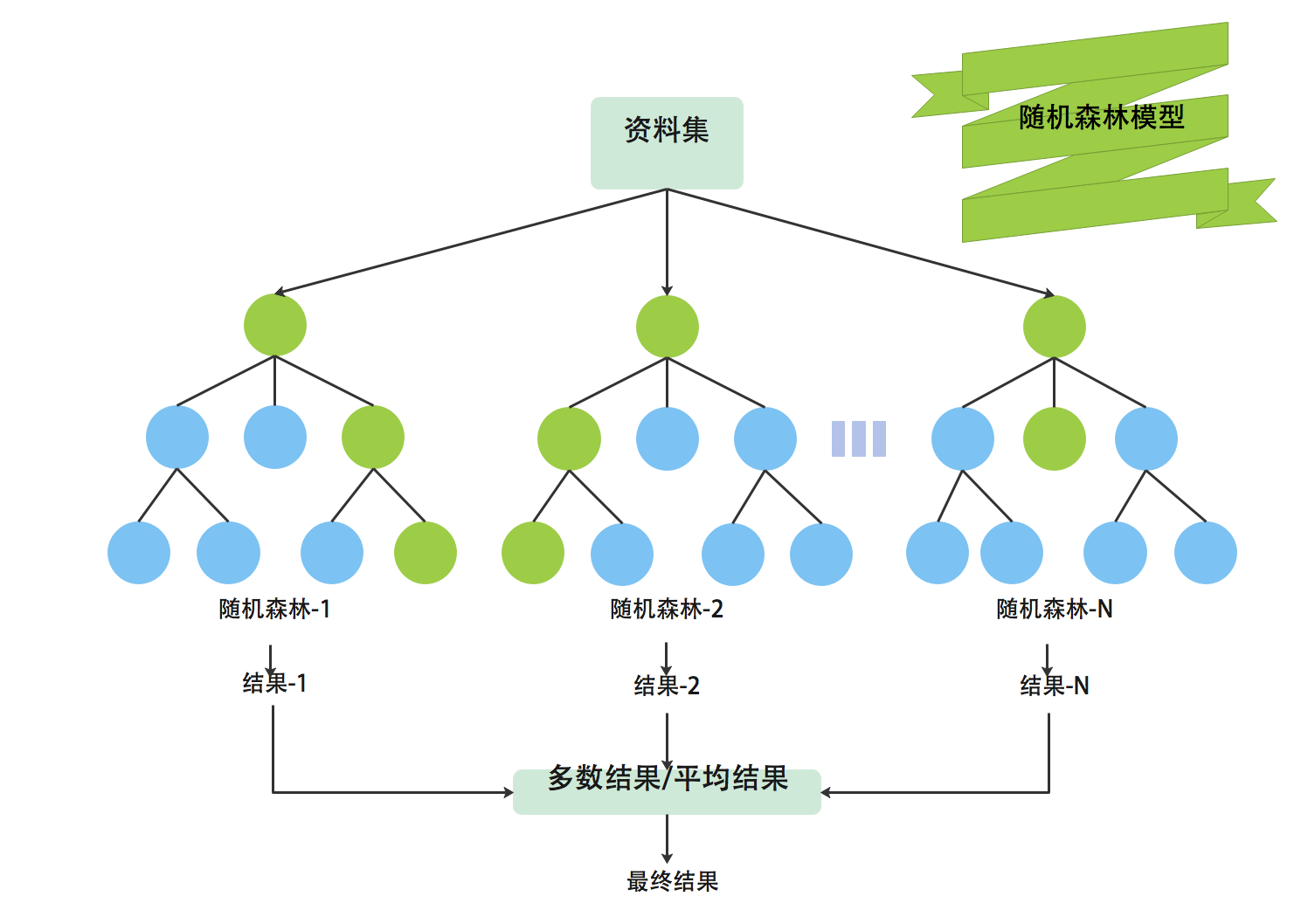
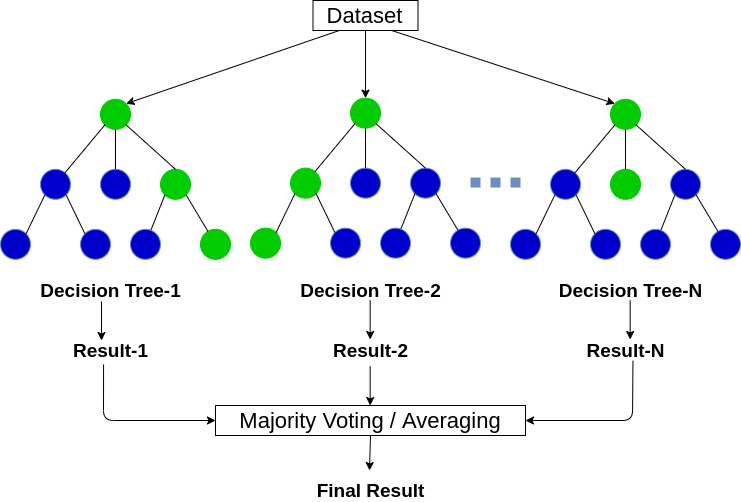
1. 随机森林的原理
随机森林采用集成学习的思想,它由多个决策树组成,每个决策树独立地对数据进行训练和预测。在训练随机森林时,对于每个决策树的训练样本,随机森林算法会随机选择一部分特征进行训练,而不是使用所有特征。这样做的目的是为了增加决策树的随机性,减少模型的方差,从而提高整体模型的泛化能力。
随机森林的预测过程是通过多个决策树的预测结果进行投票来决定最终的预测类别(分类问题)或平均预测值(回归问题)。由于随机森林中包含多个决策树,因此它可以减少单个决策树的过拟合问题,提高模型的稳定性和准确性。
2. 随机森林的优势
随机森林具有以下几个优势,使其在许多机器学习任务中成为首选算法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









