







上一节内容
LangChain学习一:入门-本地化部署-接入大模型
http://t.csdnimg.cn/aqx9W
学习目标:模型(models)
LangChain 支持的各种模型类型和模型集成。
学习内容一:模型分类
-
Chat 聊天模型
-
LLMs(大语言模型)
-
文本嵌入模型
Chat 聊天模型:这些模型通常由语言模型支持,但它们的API更加结构化。 具体来说,这些模型将聊天消息列表作为输入,并返回聊天消息。
LLMs:这些模型将文本字符串作为输入,并返回文本字符串作为输出
文本嵌入模型:这些模型将文本作为输入,并返回一个浮点数列表
学习内容二:不同模型实战
3.1 Chat-聊天模型
3.1.1 声明
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate, LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)

这个警告是应为PromptTemplate和LLMChain现在弃用了可以使用如下导入
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
3.1.2 Chat-聊天类型实战
# ChatOpenAI默认是chatGTP3.5的模型
# chat = ChatOpenAI(temperature=0)
# 我们在上一节内容部署了自己的模型
chat = ChatOpenAI(
streaming=True,
verbose=True,
# callbacks=[callback],
openai_api_key="none",
openai_api_base="http://127.0.0.1:8000/v1",
model_name="Qwen-7B-Chat"
)
LangChain目前支持的消息类型
- AIMessage
- HumanMessage
- SystemMessage
- ChatMessage
前面三个常用,后面ChatMessage接受任意角色的参数,大多数情况下只需要处理前三个。
3.1.2.1 AIMessage(AI 消息)
由人工智能生成和发送的消息。这些消息可能包含自动生成的回复、建议或信息。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
chat = ChatOpenAI(
streaming=True,
verbose=True,
# callbacks=[callback],
openai_api_key="none",
openai_api_base="http://127.0.0.1:8000/v1",
model_name="Qwen-7B-Chat"
)
out=AIMessage(content="你好,我是代码浪人", additional_kwargs={})
print("==========")
print(out)

这里的content就相当于大模型机器回答,干啥用呢,为了以后的多轮对话做准备。
3.1.2.2 HumanMessage(用户消息)
由真实用户生成和发送的消息。这些消息来自人类用户,包括文本、图片或其他形式的交流内容。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
chat = ChatOpenAI(
streaming=True,
verbose=True,
# callbacks=[callback],
openai_api_key="none",
openai_api_base="http://127.0.0.1:8000/v1",
model_name="Qwen-7B-Chat"
)
out=chat([HumanMessage(content="你好,你是谁")])
print("==========")
print(out)
print("==========")

这里才是我们提问的地方
3.1.2.3 SystemMessage(系统消息)
用于向用户提供系统通知、警告或其他重要信息的消息。这些消息通常由系统自动生成并发送。
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
chat = ChatOpenAI(
streaming=True,
verbose=True,
# callbacks=[callback],
openai_api_key="none",
openai_api_base="http://127.0.0.1:8000/v1",
model_name="Qwen-7B-Chat"
)
messages = [
SystemMessage(content="你现在是翻译专家,你会把我的话转化成英文"),
HumanMessage(content="我是个帅小伙,很开心认识大家")
]
out=chat(messages)
print("==========")
print(out)
print("==========")

看到没,这时候,我们的大模型就可以作为一个助手帮你了
还可有以下情况,就是上面说的模仿大模型说话,我们先看一下原生的
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
chat = ChatOpenAI(
streaming=True,
verbose=True,
# callbacks=[callback],
openai_api_key="none",
openai_api_base="http://127.0.0.1:8000/v1",
model_name="Qwen-7B-Chat"
)
print("==========")
res = chat(
[
SystemMessage(content="你现在是一个青春期叛逆少年,不喜欢学习,喜欢新事物"),
HumanMessage(content="老师让我写作业,我不想写,怎么办")
]
)
print(res)

加入之后
print("==========")
res = chat(
[
SystemMessage(content="你现在是一个青春期叛逆少年,不喜欢学习,喜欢新事物"),
HumanMessage(content="老师让我写作业,我不想写,怎么办"),
AIMessage(content="我要玩一会,我要玩一会!"),
HumanMessage(content="老师让我写作业,我不想写,怎么办")
]
)
print(res)

是不是很好玩
同时还支持批量操作
print("==========")
batch_messages = [
[
SystemMessage(content="你是一名鼓励师,你要夸我"),
HumanMessage(content="我是一个开发人员")
],
[
SystemMessage(content="你是一名翻译工作人员,帮我的话翻译成英文"),
HumanMessage(content="我是一个开发人员")
],
]
result = chat.generate(batch_messages)
print(result)
print("==========")
print(result.llm_output)
print("==========")
print(result.generations)

3.1.2.4 ChatMessage(聊天消息)
用于表示在聊天对话中交换的消息,可以是来自 AI 或真实用户的消息。
3.2 LLMs(大语言模型)
在介绍LLMs大语言模型不得不介绍python中的一个类叫LLM,它是和LLMs(大模型)进行交互的方式。
有许多LLM提供商(OpenAI、Cohere、Hugging Face等)-该类旨在为所有LLM提供商提供标准接口。
3.2.1 LLM提供商OpenAI
申明
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-ada-001", n=2, best_of=2)
调用(单例)
out=llm("给我说一个笑话")
print(out)
结果:
“那只鸡为什么过马路?去另一边。”
调用(批量)
llm_result = llm.generate(["给我说一个笑话", "给我说一个笑话"])
3.3 文本嵌入(Text Embedding)
嵌入会创建文本的向量表示。
这很有用,因为这意味着我们可以在向量空间中考虑文本,并执行诸如语义搜索之类的操作,其中我们在向量空间中寻找最相似的文本片段。
LangChain中的基本Embedding类公开了两种方法:embed_documents和embed_query。
- embed_documents:适用于多个文档
- embed_query:适用于单个文档
除此之外,将这两个方法作为两个单独的方法的另一个原因是,某些嵌入提供商针对要搜索的文档与查询本身具有不同的嵌入方法。

3.1.1实战
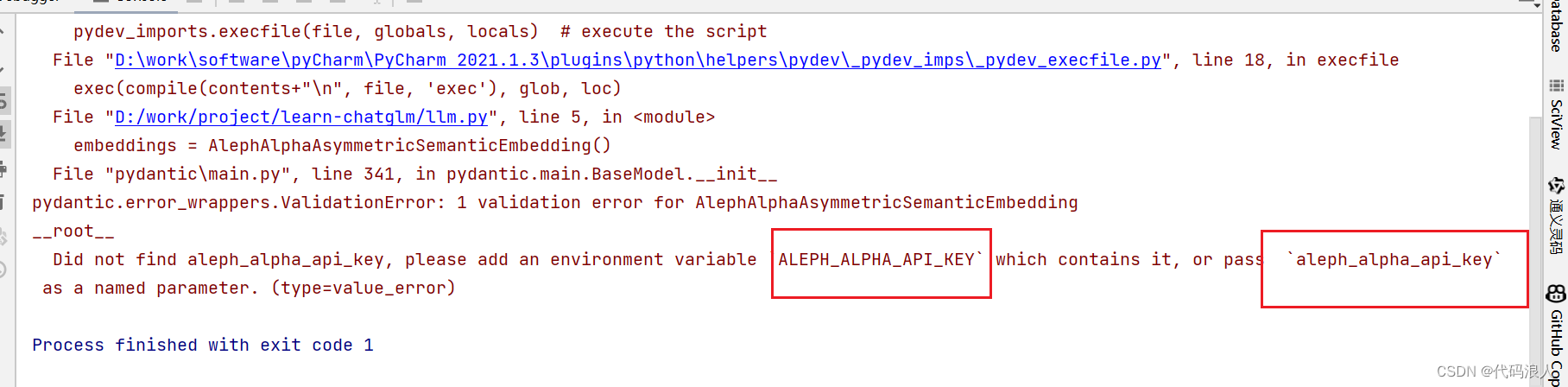
网上的有的是需要key
from langchain.embeddings import AlephAlphaAsymmetricSemanticEmbedding
document = "这是一个测试文档。"
query = "测试文档"
embeddings = AlephAlphaAsymmetricSemanticEmbedding()
doc_result = embeddings.embed_documents([document])
query_result = embeddings.embed_query(query)
print(query_result)
3.1.1.1 HuggingFaceEmbeddings
这个是HuggingFace,他是开源免费的,我看了一下源码的里面方法,说明这个他是需要安装sentence_transformers这个依赖的,然后支持cpu的
pip install sentence_transformers
这里我们使用的是FAISS向量库
import re
from langchain import FAISS
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.prompts import SemanticSimilarityExampleSelector
from langchain.text_splitter import RecursiveCharacterTextSplitter
def information_extraction(text_content,my_noun):
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n"], chunk_size=200, chunk_overlap=100)
# 将文本按照指定的方式进行分割
chunks = text_splitter.split_text(text_content)
# 创建包含content字段的字典并保存在数组中
examples = [{"content": chunk} for chunk in chunks]
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
# 这是用于生成用于测量语义相似性的嵌入的嵌入类
HuggingFaceEmbeddings(),
# 这是用于存储联入和进行相似性搜索的 VectorStore 类,
FAISS,
# 最想的要的示例要几个
k=3
)
input_variables = {
'content': my_noun
}
output=example_selector.select_examples(input_variables)
# 提取'input'内容并拼接成str,中间换行
res=''
for i, d in enumerate(output, start=1):
if 'content' in d:
res += f"第{i}段相关信息内容:\n{d['content']}\n"
return res.strip()
if __name__ == '__main__':
with open('wendang.txt', 'r', encoding="utf-8") as file:
text = file.read()
my_noun='添加微信'
print(information_extraction(text,my_noun))
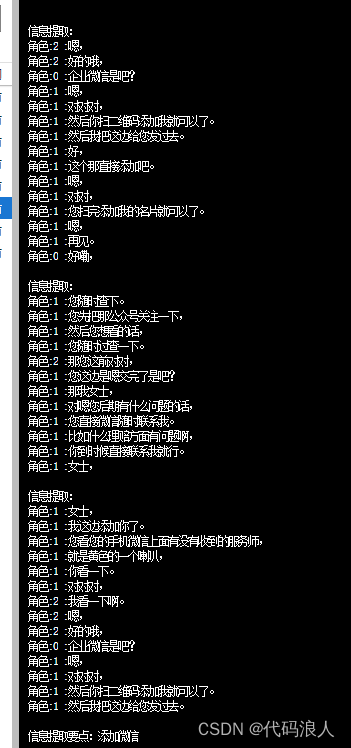
wendang.txt文本内容
角色:0 :哎,
角色:1 :你好你好好,
角色:2 :您是朱杰朱女士是吧?
角色:2 :啊,
角色:2 :对啊,
角色:2 :哎,
角色:1 :你女士您好,
角色:1 :打扰到您了。
角色:2 :我这边是XX燃气的工作人员,
角色:1 :就是您的那个江苏省兴化市安丰镇徐吴八组的一个房子啊,
角色:1 :当时在在户需要天然气的时候,
角色:1 :买这天然气保障是保保。
角色:1 :您谈两个联系的这个女士,
角色:1 :您还记得吧?
角色:0 :是什么时候啊?
角色:1 :呃,
角色:1 :就是您开户的时候是二一年二一年的时候买的那车。
角色:1 :嗯,
角色:1 :但是你是交钱去呃,
角色:1 :上门师傅给你上门安装的时候买的嘛,
角色:1 :一年应该是两百块钱左右。
角色:1 :然后当时买的话,
角色:1 :你是年的,
角色:1 :就是去年的十一月份就过去哦,
角色:0 :是买了什么保险是吧?
角色:0 :嗯,
角色:0 :对,
角色:2 :新望燃气保险。
角色:1 :嗯,
角色:1 :对对,
角色:1 :这边保健那块来好想去的,
角色:1 :然后这个现在不是断保了吗?
角色:1 :女士,
角色:1 :我这边通知到您啊,
角色:1 :为了确保您家房屋后期由于这个意外导致的一些损失啊,
角色:1 :可以这边给给你保险理赔,
角色:1 :所以耽误您几分钟时间,
角色:1 :现场协助。
角色:1 :另外那续保的女士,
角色:1 :嗯,
角色:1 :你看这里那个续保地址应该是没有更改吧。
角色:1 :女士呃,
角色:0 :没有,
角色:0 :还是那个嗯嗯好的女士。
角色:2 :呃,
角色:1 :那您看一下女士,
角色:1 :我这边用那个企业微信加您好友。
角色:1 :稍后我把新年的那个 q 码把信息给您发到微信上面去,
角色:1 :您打开手机看一下。
角色:1 :呃,
角色:1 :就您这个微信的话是二五八六,
角色:1 :尾号是二五八。
角色:1 :这地方女士啊,
角色:1 :对对对,
角色:1 :嗯嗯,
角色:1 :好的,
角色:1 :女士,
角色:1 :我这边添加你了。
角色:1 :您看您的手机微信上面有没有收到的服务师,
角色:1 :就是黄色的一个喇叭,
角色:1 :你看一下。
角色:1 :对对对,
角色:2 :我看一下啊。
角色:2 :嗯,
角色:2 :好的哦,
角色:0 :企业微信是吧?
角色:1 :嗯,
角色:1 :对对对,
角色:1 :然后你扫二维码添加我就可以了。
角色:1 :然后我把这边给您发过去。
角色:1 :好,
角色:1 :这个那直接添加吧。
角色:1 :嗯,
角色:1 :对对,
角色:1 :您扫完添加我的名片就可以了。
角色:1 :嗯,
角色:1 :再见。
角色:0 :好嘞,
角色:1 :哦我看到了女士,
角色:1 :你稍等一下,
角色:1 :我把这个给您发过去。
角色:1 :然后这个上面的话,
角色:1 :有你的这个今年的你一个手机号码,
角色:1 :还有你的地址,
角色:1 :你看看有没有需要更改的,
角色:1 :我给您发过去,
角色:1 :您稍等一下,
角色:2 :我已经啊,
角色:2 :女士,
角色:2 :我这边就不您发送了,
角色:2 :您仔细看一下。
角色:1 :对,
角色:1 :这个是您现在的投保信息。
角色:2 :您看您直接扫二维码,
角色:1 :看一下你上面这个信息,
角色:1 :对不对?
角色:0 :女士哦,
角色:0 :我要扫一下那个二维码,
角色:0 :看一下。
角色:0 :嗯,
角色:1 :对对对,
角色:1 :二维码里把里面里面有你的这个投保信息息里面有你的地址,
角色:2 :还有你的手机号码,
角色:1 :还应该是这个身份证号码,
角色:1 :你看核对对不对?
角色:0 :女士保费九百元。
角色:1 :对,
角色:1 :这个是三年的,
角色:1 :您直接保障二六年的十一月份就不需要那个车钱了。
角色:1 :因为因为这边很多老用户啊,
角色:1 :他是宝贝上涨了女士,
角色:1 :她是三百块钱,
角色:1 :涨到五百块钱左右。
角色:2 :我直接给您按三连续二时,
角色:1 :其中的话您这个宝贝再上涨五百块钱,
角色:1 :您也不用补其中差价。
角色:1 :女士哦,
角色:0 :他那个还是他那个是里面会加的吗?
角色:1 :嗯,
角色:1 :因为女士您之前不是两百吗?
角色:1 :现在是三百了,
角色:1 :女士对吧?
角色:1 :哦,
角色:1 :对对对,
角色:0 :我记得好像有一次两百块钱。
角色:0 :嗯,
角色:1 :对,
角色:1 :三百块钱。
角色:1 :我跟你说一下,
角色:1 :为什么三百块钱他多了一百来块钱的话,
角色:1 :他是姥姥给你上涨了,
角色:1 :你你保额之前是五百多万,
角色:1 :现在是一千一百多万,
角色:1 :就是你总共可以理赔的,
角色:1 :保额是一千一百多万。
角色:1 :嗯,
角色:1 :然后呢,
角色:1 :给您加了一下,
角色:1 :可以保家庭六伙人的人身意外险,
角色:1 :就是您后期这个意外险方面就不用买了,
角色:1 :他最多可以保啊家里六口人,
角色:1 :您的呃您的爱人和您的孩子啊,
角色:1 :您的您家的老人都可以保就是挪六个人。
角色:1 :就比如说啊包含了啊,
角色:0 :都是包含在这个里面的是吧?
角色:0 :嗯,
角色:2 :对对对,
角色:2 :就是后期两个。
角色:1 :对你这个意外险方面就可以不用再买了,
角色:1 :可以保最多六六人。
角色:1 :他像这个平时磕磕磕碰碰是吧?
角色:1 :那个磕磕碰碰边京马扎口有一些呃,
角色:1 :离去医院那个门诊费挂挂号的话,
角色:1 :或者是这些费用啊,
角色:1 :只要超过两百块钱以上,
角色:1 :我们是按百分之九十给你报销。
角色:1 :就是您这个医保用完之后话,
角色:1 :您可以再接着用,
角色:2 :用们这支付宝也可以女士。
角色:0 :嗯,
角色:0 :哦,
角色:0 :我先看一下自然灾害跟意外事故。
角色:2 :对,
角色:1 :那意外事故就是您这个房子里面呢,
角色:1 :比如说水源管爆裂造您一下一个一些损失啊。
角色:1 :嗯,
角色:1 :呃墙体发霉之类的,
角色:1 :就像意外事故的话,
角色:1 :到时候手机拍个照片,
角色:1 :我们呃师傅上门给您看一下。
角色:1 :呃,
角色:1 :这个是到时候会按情况给你理赔的女士嗯,
角色:0 :是这个意思吧?
角色:2 :对对,
角色:1 :就是比如说你们家里那个电器啊,
角色:1 :由于意外导致的损,
角色:2 :主要是女士,
角色:2 :主要是由于意外导致的损失,
角色:1 :我们这边都是可以给你把了一下,
角色:0 :这个管个嗯管道破裂它也可以的。
角色:2 :嗯,
角色:2 :对对对,
角色:0 :哦,
角色:0 :哦哦,
角色:0 :是这个意思。
角色:1 :嗯,
角色:1 :他不是说只是保个燃气,
角色:1 :燃气上,
角色:1 :就是您家里面能看得到的一些财产,
角色:1 :他主要是机己的。
角色:1 :嗯,
角色:1 :对,
角色:1 :主要是由于意外导致的损失,
角色:1 :然后你用手机拍个照片呃,
角色:1 :做个证据,
角色:1 :我们到时候给您上门看一下,
角色:1 :然后直接给您理赔的女生,
角色:1 :到时候如果情况属实的话,
角色:1 :是一个理赔预算。
角色:0 :哦,
角色:0 :那如果有这个的话,
角色:0 :那卧室我是联系谁呀?
角色:0 :呃,
角色:1 :这个您联系我客呃呃,
角色:1 :保险基金公司啊。
角色:1 :女士,
角色:1 :您不知道您您您这边有没有我们的客服电话?
角色:0 :女士好像没有?
角色:0 :哎,
角色:1 :客服电话的话,
角色:1 :您您直接关我们关注我们公众号,
角色:1 :嗯,
角色:1 :对你微信上下直接搜索,
角色:1 :关注我们就可以了。
角色:1 :如果你不知道号码的话,
角色:1 :您到时候可以查查,
角色:1 :都可以能查得到。
角色:1 :因为他这个号码的话,
角色:1 :您直接上网搜搜,
角色:1 :然后您这边投保完之后啊,
角色:1 :您需要看您的这个投保订单,
角色:1 :直接关注我们公众号里面就能看得到你的这个订单。
角色:1 :女士不能查得到买单你的传哦,
角色:0 :我这边的话,
角色:0 :去那个官方官方热线电话也可以的吧。
角色:0 :对,
角色:1 :嗯嗯,
角色:1 :都可以。
角色:1 :女士,
角色:1 :您找我们客服电话都可以吗?
角色:1 :四零零六零五三个八呃,
角色:1 :一个八三个零女士,
角色:1 :就那个客服电话啊。
角色:0 :对对对对对,
角色:0 :四零零六零八零零零零二。
角色:0 :对对对,
角色:0 :女士,
角色:1 :这是我们客服电话吗?
角色:1 :女士,
角色:1 :嗯,
角色:1 :哦对,
角色:1 :然后我这边就是按照您这个三年给您续嘛,
角色:1 :因为很多老用户的话也是担心宝贝上涨。
角色:1 :您这个三年之后直接保到三年八六年,
角色:1 :其中的话如果保费调到五百元,
角色:1 :这个也跟你没关系,
角色:1 :你也不用补其中差价嘛。
角色:1 :女士,
角色:0 :因为之前我知道这个在二六年之内吧,
角色:0 :反正是不需要的吧。
角色:2 :嗯,
角色:2 :对,
角色:2 :二六年呢,
角色:1 :就您如果保费上涨就不用补差价的车,
角色:1 :就直接是三百块钱一年。
角色:2 :对哦,
角色:0 :现在是直接三百亚,
角色:0 :对吧?
角色:2 :对对,
角色:2 :女士,
角色:1 :那您看您这个资料是不是正确的女士啊啊,
角色:2 :对,
角色:1 :跟跟对的啊。
角色:1 :嗯,
角色:1 :对,
角色:1 :那您下滑女士,
角色:1 :您下滑上面签个字就可以了。
角色:2 :对,
角色:0 :我看一下啊。
角色:1 :对,
角色:1 :它下面不有一个签字嘛,
角色:1 :看你本人的。
角色:1 :对呀,
角色:1 :对,
角色:1 :你点击签字提交,
角色:1 :然后您支付完之后就投保成功了。
角色:1 :女士,
角色:1 :到时候您可以下载一个你的那个投保订单,
角色:1 :不能下下载就可以了,
角色:1 :而且你的直接可以了。
角色:1 :很有理解的是思情好爱,
角色:0 :这样直接再查填就好了,
角色:0 :对吧?
角色:1 :对,
角色:1 :签字提交就可以了,
角色:1 :然后他直接支付就可以了,
角色:0 :我也接受成功了。
角色:1 :哦,
角色:1 :您支付成功了是吧?
角色:1 :嗯,
角色:1 :对,
角色:1 :嗯,
角色:1 :好的,
角色:1 :我这边帮您看一下。
角色:1 :嗯,
角色:1 :看到女士你这边退后成功了。
角色:1 :那您看有没有要您下载一个电子保单,
角色:1 :女士下载个电子保单吗?
角色:0 :啊,
角色:0 :那要点一下下载保单是吧?
角色:1 :嗯,
角色:1 :下载之后,
角色:1 :您上面不有一个电子保单吗?
角色:1 :或者说女士呃,
角色:1 :您可以关注我们这个新药保险经济公众号,
角色:1 :您这边有没有关注过?
角色:1 :女士?
角色:0 :没有,
角色:0 :好像那这个还要还要发送验证码呀,
角色:0 :呃,
角色:1 :零零四嘛。
角色:1 :嗯,
角色:1 :对,
角色:1 :因为你士你不是第一第一一登女士啊,
角色:1 :对,
角色:1 :京动的话需要发发京东吧,
角色:1 :或者女士您后期您要想学着查的话,
角色:1 :您关注一下。
角色:2 :那我们新浪保险经济公众号,
角色:0 :你给他发任务,
角色:0 :我要相信亲哦,
角色:2 :对你公众号呀,
角色:1 :对,
角色:1 :关注一下啊,
角色:0 :等我有时间再关注吧。
角色:0 :对对,
角色:1 :您想查的话,
角色:1 :您随时查下。
角色:1 :您先把那公众号关注一下,
角色:1 :然后您想看的话,
角色:1 :您随时过查一下。
角色:2 :那您这前对对,
角色:1 :您这边是嗯交完了是吧?
角色:1 :那我女士,
角色:1 :对嗯您后期有什么问题的话,
角色:1 :您直接微信随时联系我。
角色:1 :比如什么理赔方面有问题啊,
角色:1 :你到时候直接联系我就行。
角色:1 :女士,
角色:1 :我会协助您参加理赔的旅程,
角色:0 :联系你就好了。
角色:0 :嗯,
角色:0 :对对对,
角色:1 :到时候我会协助你们。
角色:1 :您如果家里出什么意外的那个损失,
角色:1 :您到时候联系我就可以了的,
角色:1 :万以上。
角色:0 :哦,
角色:0 :行行行,
角色:1 :可以。
角色:1 :嗯,
角色:1 :行,
角色:1 :那女士我这边就不耽误太多时间了,
角色:2 :好吧,
角色:2 :您有问题。
角色:2 :好的好的,
角色:2 :嗯,
角色:1 :好好好,
角色:1 :再见。
角色:1 :嗯,
角色:1 :好好,
角色:1 :再见,
角色:1 :嗯,
角色:1 :好,
角色:1 :再见。
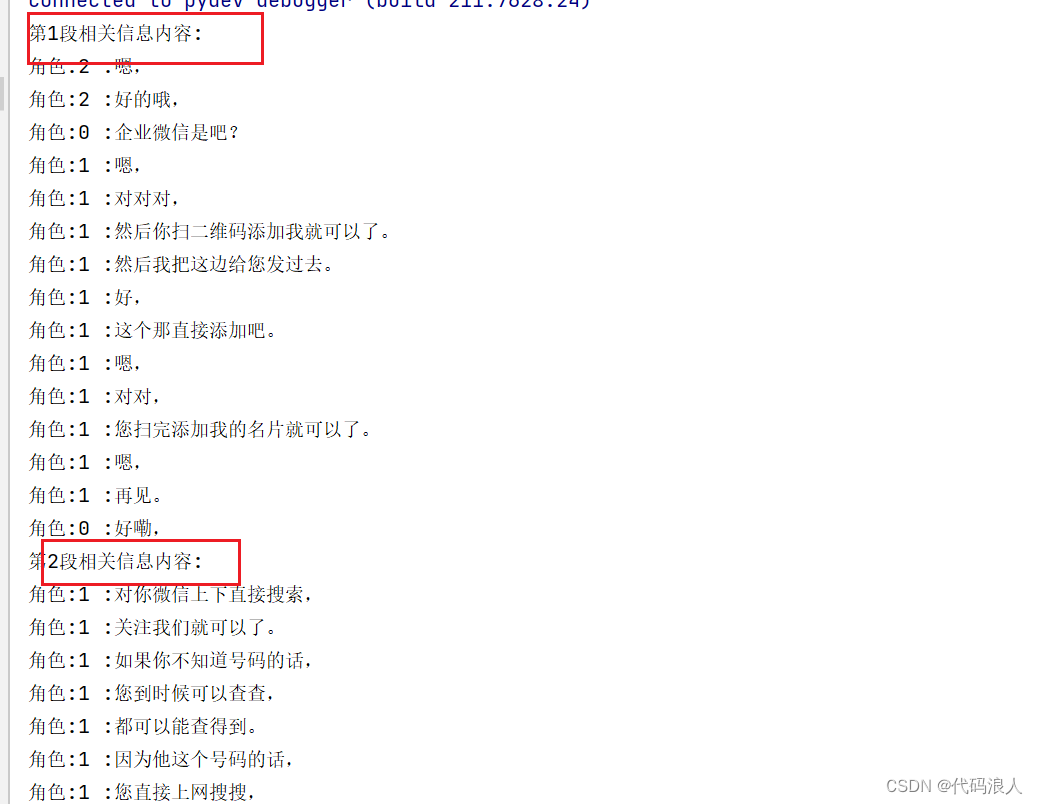
根据代码设置,我们这里就会出现三段相关信息的片段
3.1.1.2 m3e-base
比较
问了一下ChatGTP是一下结果,仅供参考
我查了一下资料,大概一下几个方向
- 开源公司不一样
- m3e-base 是由中国一家人工智能公司 Moka AI 开源的
- all-mpnet-base-v2 是由 Google AI 和 DeepMind 联合开发的,因此可以说是由这两个公司共同开源的
- 模型架构不一样
- m3e-base 是基于 Transformer 架构的模型
- all-mpnet-base-v2 是基于 MPNet 架构的模型
Transformer 架构是目前最流行的语言模型架构之一,具有良好的性能和效率。MPNet 架构是 Transformer 架构的一种改进,具有更大的模型容量和更好的性能。
- 训练数据
- m3e-base 是基于 BookCorpus 和 WikiText-103 数据集训练的模型
- all-mpnet-base-v2 是基于 BookCorpus、WikiText-103 和 OpenWebText 数据集训练的模型
-
性能
在 GLUE 基准测试中,all-mpnet-base-v2 的平均分数比 m3e-base 高出约 1.5 个点。这表明 all-mpnet-base-v2 在各种自然语言处理任务上具有更强的性能。 -
适用场景
m3e-base 和 all-mpnet-base-v2 都适用于文本表示和自然语言处理任务。然而,all-mpnet-base-v2 在性能方面更有优势,因此更适合需要高性能的任务,例如文本分类、问答和机器翻译。 -
总结
m3e-base 和 all-mpnet-base-v2 都是强大的语言模型,具有不同的优势。m3e-base 的优势在于效率和易用性,而 all-mpnet-base-v2 的优势在于性能和鲁棒性。具体选择哪个模型,需要根据具体的应用场景和需求来决定。
鲁棒性:鲁棒是Robust的音译,也就是健壮和强壮的意思
下载
from modelscope.hub.snapshot_download import snapshot_download
local_dir_root = "/root/autodl-tmp/models_from_modelscope"
snapshot_download('Jerry0/m3e-base', cache_dir=local_dir_root)
实战
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('/root/autodl-tmp/models_from_modelscope/Jerry0/m3e-base')
#Our sentences we like to encode
sentences = [
'* Moka 此文本嵌入模型由 MokaAI 训练并开源,训练脚本使用 uniem',
'* Massive 此文本嵌入模型通过**千万级**的中文句对数据集进行训练',
'* Mixed 此文本嵌入模型支持中英双语的同质文本相似度计算,异质文本检索等功能,未来还会支持代码检索,ALL in one'
]
#Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
#Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
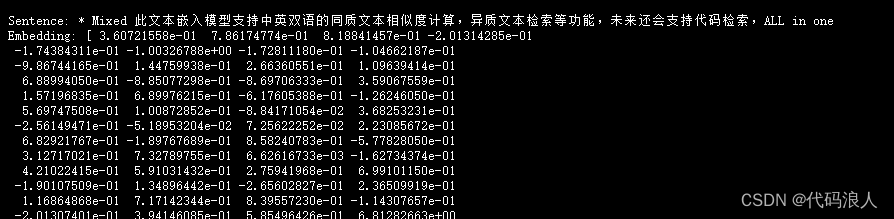
print("Sentence:", sentence)
print("Embedding:", embedding)
print("")
"""
@FileName:信息抽取.py
@Description:
@Author:lucky
@Time:2023/12/5 10:12
"""
from langchain import FAISS, PromptTemplate, FewShotPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.prompts import SemanticSimilarityExampleSelector
from langchain.text_splitter import RecursiveCharacterTextSplitter
from sentence_transformers import SentenceTransformer
embeddings = HuggingFaceEmbeddings(
model_name = "/root/autodl-tmp/models_from_modelscope/Jerry0/m3e-base",
model_kwargs = {'device': 'cuda'})
llm = ChatOpenAI(
streaming=True,
verbose=True,
# callbacks=[callback],
openai_api_key="none",
openai_api_base="http://127.0.0.1:8000/v1",
model_name="/Qwen-7B-Chat"
)
def information_extraction(text_content, prompt_object=None):
if prompt_object is None:
prompt_object = {}
num_tokens = llm.get_num_tokens(text_content)
print(f"=============本次分析token数量为:{num_tokens}==============")
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n"], chunk_size=200, chunk_overlap=100)
# 将文本按照指定的方式进行分割
chunks = text_splitter.split_text(text_content)
# 创建包含content字段的字典并保存在数组中
examples = [{"content": chunk} for chunk in chunks]
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples,
# 这是用于生成用于测量语义相似性的嵌入的嵌入类
embeddings,
# 这是用于存储联入和进行相似性搜索的 VectorStore 类,
FAISS,
# 最想的要的示例要几个
k=3
)
# 模板
example_prompt = PromptTemplate(
input_variables=["content"],
template="信息提取:\n{content}",
)
# 选择示例的模板
similar_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="根据下面信息提取,找出相关内容",
suffix="信息提取要点:{noun}\n",
input_variables=["noun"],
)
my_noun=prompt_object.get('content')
# 显示示例
output=similar_prompt.format(noun=my_noun)
return output
if __name__ == '__main__':
with open('wendang.txt', 'r', encoding="utf-8") as file:
text = file.read()
prompt_object={'content':'添加微信'}
out=information_extraction(text,prompt_object)
print(out)
流处理
只要在声明的地方加入streaming和callbacks
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()])
from langchain.chat_models import ChatOpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
chat = ChatOpenAI(streaming=True, callbacks=[StreamingStdOutCallbackHandler()],
verbose=True,
# callbacks=[callback],
openai_api_key="none",
openai_api_base="http://127.0.0.1:8000/v1",
model_name="Qwen-7B-Chat"
)
resp = chat([HumanMessage(content="你好,你是谁")])
print(resp)
然后就在控制台一个字一个字打印

关于我-一个默默打工小孩
我是去年本科计算机毕业的,一直在前进。不存在商业化博客,乱七八糟的。
如果帮到大家了,或者遇到什么麻烦欢迎和我一起讨论
18956043585(微信同号)
如果解决你的麻烦,也欢迎在这里留下你的兴奋
目标是2天一更新,继续加油吧

















 1264
1264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











