









怎样从0开始搭建一个测试框架_6
针对UI自动化,接下来我们用PO思想进行下封装。
对于不同的项目,不同的页面,我们都需要选择浏览器、打开网址等,我们可以把这些操作抽象出来,让不同的用例去调用,只需要传入不同参数即可,不用一遍遍复制粘贴。
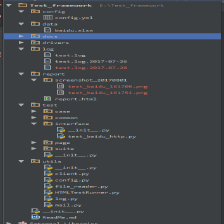
为此,我们对test目录再次进行分层,创建page、common、case、suite四个目录:
test
|--case(用例文件)
|--common(跟项目、页面无关的封装)
|--page(页面)
|--suite(测试套件,用来组织用例)
我们首先想要封装的选择浏览器、打开网址的类,所以放到common中,创建browser.py:
import time
import os
from selenium import webdriver
from utils.config import DRIVER_PATH, REPORT_PATH
# 可根据需要自行扩展
CHROMEDRIVER_PATH = DRIVER_PATH + '\chromedriver.exe'
IEDRIVER_PATH = DRIVER_PATH + '\IEDriverServer.exe'
PHANTOMJSDRIVER_PATH = DRIVER_PATH + '\phantomjs.exe'
TYPES = {'firefox': webdriver.Firefox, 'chrome': webdriver.Chrome, 'ie': webdriver.Ie, 'phantomjs': webdriver.PhantomJS}
EXECUTABLE_PATH = {'firefox': 'wires', 'chrome': CHROMEDRIVER_PATH, 'ie': IEDRIVER_PATH, 'phantomjs': PHANTOMJSDRIVER_PATH}
class UnSupportBrowserTypeError(Exception):
pass
class Browser(object):
def __init__(self, browser_type='firefox'):
self._type = browser_type.lower()
if self._type in TYPES:
self.browser = TYPES[self._type]
else:
raise UnSupportBrowserTypeError('仅支持%s!' % ', '.join(TYPES.keys()))
self.driver = None
def get(self, url, maximize_window=True, implicitly_wait=30):
self.driver = self.browser(executable_path=EXECUTABLE_PATH[self._type])
self.driver.get(url)
if maximize_window:
self.driver.maximize_window()
self.driver.implicitly_wait(implicitly_wait)
return self
def save_screen_shot(self, name='screen_shot'):
day = time.strftime('%Y%m%d', time.localtime(time.time()))
screenshot_path = REPORT_PATH + '\screenshot_%s' % day
if not os.path.exists(screenshot_path):
os.makedirs(screenshot_path)
tm = time.strftime('%H%M%S', time.localtime(time.time()))
screenshot = self.driver.save_screenshot(screenshot_path + '\\%s_%s.png' % (name, tm))
return screenshot
def close(self):
self.driver.close()
def quit(self):
self.driver.quit()这里做了非常简单的封装,可以根据传入的参数选择浏览器的driver去打开对应的浏览器,并且加了一个保存截图的方法,可以保存png截图到report目录下。
我们再封装一个页面类Page:
from test.common.browser import Browser
class Page(Browser):
# 更多的封装请自己动手...
def __init__(self, page=None, browser_type='firefox'):
if page:
self.driver = page.driver
else:
super(Page, self).__init__(browser_type=browser_type)
def get_driver(self):
return self.driver
def find_element(self, *args):
return self.driver.find_element(*args)
def find_elements(self, *args):
return self.driver.find_elements(*args)我们仅仅封装了几个方法,更多的封装还请读者自己动手,接下来我们需要对页面进行封装,在page目录创建如下两个文件:
baidu_main_page.py:
from selenium.webdriver.common.by import By
from test.common.page import Page
class BaiDuMainPage(Page):
loc_search_input = (By.ID, 'kw')
loc_search_button = (By.ID, 'su')
def search(self, kw):
"""搜索功能"""
self.find_element(*self.loc_search_input).send_keys(kw)
self.find_element(*self.loc_search_button).click()baidu_result_page.py:
from selenium.webdriver.common.by import By
from test.page.baidu_main_page import BaiDuMainPage
class BaiDuResultPage(BaiDuMainPage):
loc_result_links = (By.XPATH, '//div[contains(@class, "result")]/h3/a')
@property
def result_links(self):
return self.find_elements(*self.loc_result_links)一个是封装的百度首页,一个封装百度结果页,这样,我们的测试用例就可以改为:
import time
import unittest
from utils.config import Config, DATA_PATH, REPORT_PATH
from utils.log import logger
from utils.file_reader import ExcelReader
from utils.HTMLTestRunner import HTMLTestRunner
from utils.mail import Email
from test.page.baidu_result_page import BaiDuMainPage, BaiDuResultPage
class TestBaiDu(unittest.TestCase):
URL = Config().get('URL')
excel = DATA_PATH + '/baidu.xlsx'
def sub_setUp(self):
# 初始页面是main page,传入浏览器类型打开浏览器
self.page = BaiDuMainPage(browser_type='chrome').get(self.URL, maximize_window=False)
def sub_tearDown(self):
self.page.quit()
def test_search(self):
datas = ExcelReader(self.excel).data
for d in datas:
with self.subTest(data=d):
self.sub_setUp()
self.page.search(d['search'])
time.sleep(2)
self.page = BaiDuResultPage(self.page) # 页面跳转到result page
links = self.page.result_links
for link in links:
logger.info(link.text)
self.sub_tearDown()
if __name__ == '__main__':
report = REPORT_PATH + '\\report.html'
with open(report, 'wb') as f:
runner = HTMLTestRunner(f, verbosity=2, title='从0搭建测试框架 灰蓝', description='修改html报告')
runner.run(TestBaiDu('test_search'))
e = Email(title='百度搜索测试报告',
message='这是今天的测试报告,请查收!',
receiver='...',
server='...',
sender='...',
password='...',
path=report
)
e.send()现在,我们已经用PO把用例改写了,这里面还有不少问题,浏览器的设置、基础page的封装、log太少、没有做异常处理等等,这些相信你都可以逐步完善的。

















 552
552

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









