








【2020AAAI】
Wang, Li, Zechen Bai, Yonghua Zhang, and Hongtao Lu. “Show, Recall, and Tell: Image Captioning with Recall Mechanism.” arXiv preprint arXiv:2001.05876 (2020).
任务:image caption
问题:以前的方法在生成caption时,仅仅关注输入图像,而没有考虑到人类的先验知识
本文在完成image caption任务时提出了吸取相似图像的caption中的先验知识,提出了recall机制。
首先使用文本检索模型,计算图像与训练集中其他caption的相似度,选取前5相似度caption中的词作为回忆词。caption生成模型基于Up-Down模型,在两层LSTM的输出结果基础上,语义引导path对回忆词特征加权求和,再使用FC得到生成词的概率,回忆词path计算直接复制回忆词的概率,并使用权重平衡两个path的结果,得到最终的生成词概率。
在交叉熵的预训练的基础上,使用SCST的强化学习方法进一步调优,同时在CIDEr激励的基础上还采用了新提出的回忆词激励(使用最终概率采样的CIDEr值减去不使用回忆词path的caption的CIDEr值)。
模型结构

①文本检索模块
图像特征
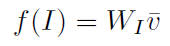
v
‾
\overline{v}
v 为不同图像区域特征的均值
文本特征
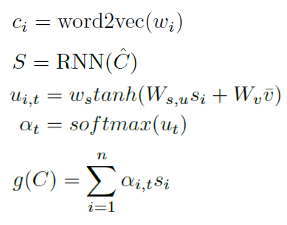
将词向量经过RNN,对再结合视觉信息对输出进行加权求和
图像和文本相似度
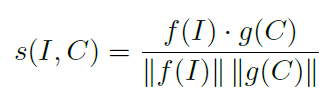
该模块训练时的损失函数(hard hinge-based triplet loss)
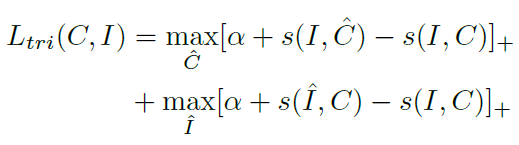
每张图选取相似度最高的5个caption,将其中的词作为回忆词集
②caption模块
1、基础模型:Up-Down模型

X
t
−
1
X_{t-1}
Xt−1为上一时间步输出的词向量
2、语义引导
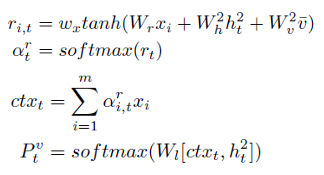
x
i
x_i
xi为回忆词向量
将回忆词向量、Up-Down模型输出及图像特征均值向量结合,计算该回忆词的权重(
α
t
r
α_t^r
αtr),并对回忆词特征进行加权求和后(
c
t
x
t
ctx_t
ctxt),拼接上Up-Down模型输出,通过FC层得到所有词的输出概率
3、回忆词path
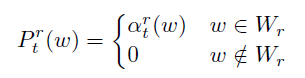
该部分考虑直接复制回忆词作为caption输出,
W
r
W_r
Wr 为回忆词集
上面两部分的结果通过soft switch作为系数进行求和,得到最终的该时间步生成词的概率
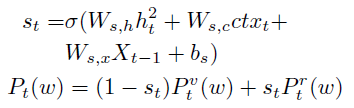
损失函数

生成caption的交叉熵损失
并在此基础上使用SCST强化学习方法,并在原来的CIDEr激励的基础上,
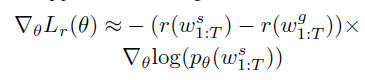
使用新提出的回忆词激励
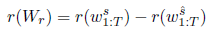
w
s
w_s
ws为根据最终概率采样的caption,
w
s
^
w^{\hat{s}}
ws^ 为
s
t
s_t
st 为0(即不使用回忆词path)的情况下采样的caption
将两种激励结合,得到最终的激励函数
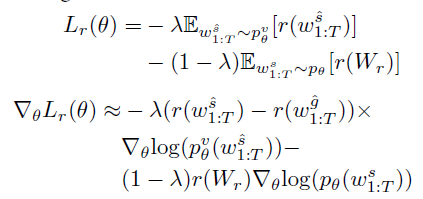
w
g
^
w^{\hat{g}}
wg^ 为不使用回忆词path的情况下,使用贪心算法的采样结果
数据集
MSCOCO2014:113287训练,5000验证,5000测试
Visual Genome:5.4M区域描述,108K图像,用于Faster-RCNN训练
评价指标
SPICE/CIDEr/METEOR/ROUGE-L/BLEU
实验
文本检索结果


















 3005
3005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









