







导读:三维装箱问题是一类经典的组合优化问题,具有巨大的学习研究和实际应用价值。传统的三维装箱问题都是给定了箱子的尺寸并以最小化箱子的使用数量为优化目标,但是在某些实际业务场景中并没有固定尺寸的箱子。

基于此类场景,本文提出了一类新型的三维装箱问题。在本问题中,需要将若干个长方体物体逐个放入一个箱子中(物品的摆放位置不能倾斜),优化目标为最小化能够容纳所有物品的箱子的表面积,因为箱子的表面积与其成本直接正相关。本文证明了此类新问题为NP-hard问题。对于装箱问题,箱子的表面积取决于物品的放入顺序、摆放的空间位置和摆放朝向。在这些因素中,物品的放入顺序有着非常重要的影响。所以本文基于近些年被提出的、能够有效解决某些组合优化问题的深度强化学习方法—Pointer Network方法来优化物品的放入顺序。
本文基于大量实际业务数据对网络模型进行了训练和检验。结果表明,相对于已有的启发式算法,深度强化学习方法能够获得大约5%的效果提升。
论文地址:https://arxiv.org/abs/1708.05930
1. 引言
装箱问题是一类非常经典且重要的优化问题,常被应用于物流系统和生产系统中。装箱问题有很多变型问题,其中最重要且最难求解的是三维装箱问题,在此问题中,需要将若干个不同大小的长方体物品放入箱子中,物品之间不能重叠且不能倾斜,箱子的尺寸和成本已知,优化目标为最小化箱子的使用数量,即最小化总成本。装箱问题一直是学术界非常流行的研究方向之一。除此之外,装箱问题在实际中也有很多应用。有效的装箱算法往往意味着计算时间、装箱成本的大量节省和资源使用效率的大幅提升。
在某些实际业务场景中,我们发现装箱时并不是使用固定尺寸的箱子(例如在跨境电商业务中,大部分是使用柔性的塑料材料,而不是箱子来包装货物),而且由于装箱的成本大部分都由装箱材料成本构成,而装箱材料成本又主要取决于材料的表面积。所以在本研究中,我们提出了一类新型的装箱问题。与传统三维装箱问题不同的是,本问题的优化目标为确定一个能够容纳所有物品的箱子,并最小化此箱子的表面积。
由于寻找装箱问题的最优解非常难,所以相关研究者们提出了不同的近似算法和启发式算法来求解此类问题。但是启发式算法往往有着较强的问题依赖性,一类启发式算法可能只适用于求解某种或某些业务场景中的装箱问题。近些年来,人工智能技术,尤其是深度强化学习(Deep reinforcement learning, DRL)技术有着非常快速的发展,并且在某些问题上取得了令人瞩目的成果。而且深度强化学习技术已经被发现在求解组合优化问题方面具有较大的潜力,所以本研究使用了一种基于深度强化学习的方法来求解新型三维装箱问题。本文基于大量实际业务数据训练了深度强化学习模型,并验证了模型的效果。
2. 相关研究介绍
2.1 三维装箱问题相关研究
装箱问题是一类非常经典和流行的优化问题。自从其在20世纪70年代被提出以来,大量研究者对此类问题进行了研究并获得了许多有价值的成果。[Coffman et al., 1980]证明了二维装箱问题是NP-hard问题,所以作为二维装箱问题的一般化问题,三维装箱问题也是NP-hard问题。由于此原因,很多之前的研究都集中于近似算法和启发式算法。[Scheithauer, 1991]首先提出了针对三维装箱问题的近似算法并分析了其近似比。

此外,研究者们还提出了很多不同类型的启发式算法,例如禁忌搜索([Lodi et al.,2002], [Crainic et al., 2009]), 引导式局部搜索 ([Faroe et al., 2003]), 基于极点的启发式算法 ([Crainic et al., 2008]),混合遗传算法([Kang et al.,2012])等。在精确解算法方面,[Chen et al., 1995]考虑了一种有多种尺寸箱子的三维装箱问题,并建立一个混合整数规划模型来求解最优解。[Martello et al.,2000]提出了一种分支定界算法来求解三维装箱问题,并通过数值实验表明90个物品以内的问题都可以在合理的时间内获得最优解。
另外,还有一些从实际业务中提出的装箱问题的变型问题,例如[Kang and Park, 2003]提出了一种可变尺寸的装箱问题,[Khanafer et al.,2010], [Gendreau et al., 2004]研究了一种考虑物品冲突的装箱问题,[Clautiaux et al.,2014]对一种考虑易碎物品的装箱问题进行了研究。
另一类装箱问题—条带装箱问题(Strippacking problem)与本文提出的新问题比较接近。在一般的条带装箱问题中,若干个长方体物品需要被逐个放入一个给定的条带中,条带的长度和宽度是已知且固定的,长度为无穷大(在二维条带装箱问题中,条带的宽度固定,但是长度为无穷大),优化目标为最小化使用的条带的高度。此类问题在钢铁工业和纺织工业中有很多应用,研究者们也提出了不同类型的求解算法,例如精确解算法([Martello et al., 2003],[Kenmochi et al., 2009]),近似解算法([Steinberg, 1997]),启发式算法([Bortfeldt and Mack, 2007], [Bortfeldt, 2006], [Hopper andTurton, 2001])等。
2.2 DRL方法在组合优化问题中的应用研究
虽然机器学习和组合优化问题已经分别被研究了数十年,但是关于机器学习方法在求解组合优化问题方面的研究却比较少。其中的一个研究方向是使用强化学习的思想来设计超启发式算法。[Burke et al., 2013]在一篇关于超启发式算法的综述论文中对于一些基于学习机制的超启发式算法进行了讨论。[Nareyek, 2003]使用了一种基于非平稳强化学习的方法来更新启发式算法被选择的概率。除此之外,强化学习思想在超启发式算法中的应用研究还包括二元指数补偿([Remde et al.,2009])、禁忌搜索([Burke et al.,2003])和选择函数等([Cowling et al., 2000])。
近些年来,序列到序列模型(sequence-to-sequence)的一系列研究突破激发了研究者们对于神经组合优化(neural combinatorial optimization)方向的兴趣。其中注意机制(attention mechanism)对于加强神经网络模型在机器翻译([Bahdanau et al.,2014])和算法学习([Graves et al.,2014])方面的效果中扮演了重要决策。 [Vinyals et al., 2015]提出了一种带有特殊注意机制的网络模型—Pointer Net,并使用有监督学习的方法来通过此模型求解旅行商问题(Travelling Salesman Problem)。[Bello et al., 2016]提出了一种基于强化学习思想的神经组合优化(neural combinatorial optimization)框架,并使用此种框架求解了旅行商问题和背包问题(Knapsack Problem)。因为此种框架的有效性和普适性,本研究在求解新型装箱问题中主要使用了此种框架和方法。
3. 针对三维装箱问题的DRL方法
3.1 问题定义
在经典的三维装箱问题中,需要将若干个物品放入固定尺寸的箱子中,并最小化箱子的使用数量。与经典问题不同的是,本文提出的新型装箱问题的目标在于设计能够容纳一个订单中所有物品的箱子,并使箱子的表面积最小。在一些实际业务场景中,例如跨境电商中,包装物品时使用的是柔性的塑料材料,而且由于包装材料的成本与其表面积直接正相关,所以最小化箱子的表面积即意味着最小化包装成本。
本文提出的新型装箱问题的数学表达形式如下所示。给定一系列物品的集合,每个物品i都有各自的长(li)、宽(wi)和高(hi)。优化目标为寻找一个表面积最小且能够容纳所有物品的箱子。我们规定(xi, yi,zi)表示每一个物品的左下后(left-bottom-back)角的坐标,而且(0, 0, 0)表示箱子的左下后角的坐标。决策变量的符号及其含义如表1所示。基于以上问题描述和符号定义,新问题的数学表达形式为:
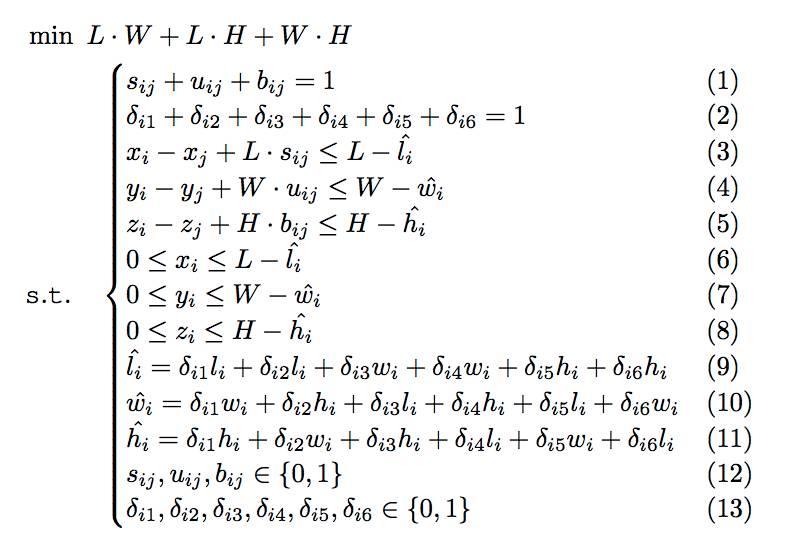

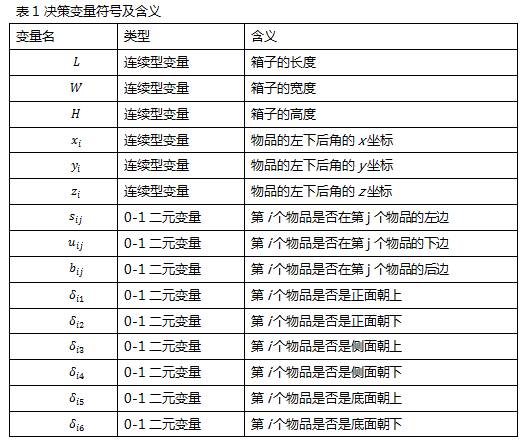
3.2 DRL方法
在本部分中,我们将介绍用于求解新型三维装箱问题的DRL方法。在求解三维装箱问题时,决策变量主要分为三类:
(1) 物品放入箱子的顺序;
(2) 物品在箱子中的摆放位置;
(3) 物品在箱子的摆放朝向。
我们首先设计了一种启发式算法来求解此类新型三维装箱问题。此种算法的基本思想为:在放入一个物品时,遍历所有可用的空余空间和物品朝向,并选择能够最小化表面积的组合。然后再遍历所有物品,确定一个能够最小化浪费空间体积(least waste space)的物品。算法的详细步骤请见附录。在本文中,我们使用DRL方法来优化物品的放入顺序,在确定了物品的放入顺序之后,选择物品的摆放位置和朝向时使用和以上启发式算法相同的方法。所以本研究的重点在于使用DRL方法来优化物品的放入顺序。在未来的研究中,我们将会把物品的放入顺序、摆放位置和朝向统一纳入深度强化学习方法框架中。
3.2.1 网络结构
本研究主要使用了[Vinyals et al.,2015]和[Bello et al.,2016]提出的神经网络结构。在Vinyals和Bello等人的研究中提出了一种名为Pointer Net (Ptr-Net)的神经网络来求解组合优化问题。例如,在求解旅行商问题时,二维平面中每个点的坐标被输入到网络模型中,经过计算之后,模型的输出为每个点被访问的顺序。这种网络结构与[Sutskever et al.,2014]提出的序列到序列模型非常相似,但是有两点不同:第一,在序列到序列模型中,每一步的预测目标的种类是固定的,但是在Ptr-Net中是可变的;第二,在序列到序列模型中,在解码阶段通过注意机制将编码阶段的隐层单元组合成为一个上下文向量信息,而在Ptr-Net中,通过注意机制来选择(指向)输入序列中的一个来作为输出。
本研究中使用的神经网络模型的结构如图1所示。网络的输入为需要装箱的物品的长宽高数据,输出为物品装箱的顺序。网络中包含了两个RNN模型:编码网络和解码网络。在编码网络的每一步中,首先对物品的长宽高数据进行嵌入表达(embedded),然后再输入到LSTM单元中,并获得对应的输出。在编码阶段的最后一步,将LSTM单元的状态和输出传递到解码网络。在解码网络的每一步中,在编码网络的输出中选择一个作为下一步的输入。如图1所示,在解码网络中的第3步的输出为4,则选择(指向)编码网络的第4步的输出,将其作为解码网络下一步(第4步)的输入。此外,在每一步的预测过程中还使用了[Bello et al., 2016]提出的Glimpse机制来整合编码阶段和解码阶段的输出信息。
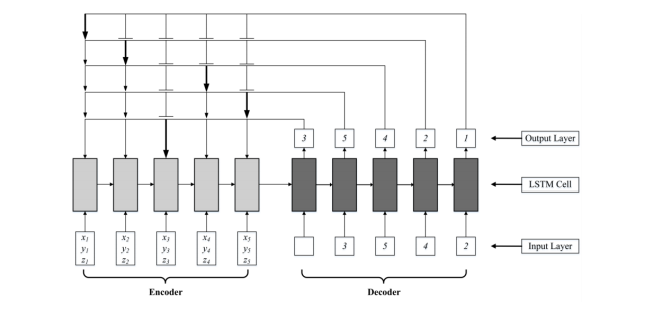 图1 神经网络模型的结构
图1 神经网络模型的结构
3.2.2 基于策略的强化学习方法


3.2.3 基准值的更新
在本研究中,我们使用了一种基于记忆重放的方法来不断地更新基准值。首先,对于每一个样本点si,通过启发式算法获取一个装箱方案,并计算其表面积,作为b(si)的初始值。之后在每一步的训练过程中,通过以下公式来更新基准值:
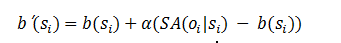

3.2.4 随机采样与集束搜索(Beam Search)
在模型的训练阶段,我们从模型预测的概率分布中进行随机选取作为输出。但是在验证阶段,我们采用贪婪策略来进行选择,即在每一步中,我们选取概率分布中概率最大的备选项作为输出。除此之外,我们还在验证阶段使用来集束搜索的方法来提高模型的效果,即在每一步中不是选择对应概率最高的备选项,而是选择概率最高的前k个备选项作为输出。
通过以上描述,模型的整个训练步骤总结为:

4. 数值实验
为了验证模型的效果,我们基于大量实际业务数据完成了数值实验。根据实验过程中每个订单中物品数量的不同(8,10和12),实验分为了三个部分,但是每次实验过程中的超参数均相同。在每次实验中,我们采用了15万条训练样本和15万条测试样本。在实验过程中,每批训练的样本量为128,LSTM的隐层单元的数量为128,Adam的初始学习速率为0.001,并且每5000步以0.96的比例衰减。网络模型的参数的初始值均从[-0.08, 0.08]中随机选取。为了防止梯度爆炸现象的出现,我们在训练过程中使用L2正则方法对梯度进行修剪。在更新基准值的过程中,的取值为0.7。在每次训练中,我们在Tesla M40 GPU上训练100万步,每次的训练时间大约为12小时。在验证阶段,使用集束搜索方法时,集束搜索的宽度为3。模型主要通过TensorFlow来实现。
数值实验的结果请见表2。主要评价指标为平均表面积(Average surface area, ASA).从表中可以看出,在使用集束搜索的情况下,本文提出的基于DRL的方法在三类测试集上分别可以获得大约4.89%, 4.88%, 5.33%的效果提升。此外,我们还通过穷举的方法获得了对于8个物品测试数据中5000个样本数据的最优物品放入顺序,并计算得到了启发式算法的结果与最优解的平均差距为10%左右,这说明基于DRL的方法的结果已经与最优解比较接近。
 表2 不同方法下获得的ASA
表2 不同方法下获得的ASA
5. 结论
本文提出了一类新型三维装箱问题。不同于传统的三维装箱问题,本文提出的问题的优化目标为最小化能够容纳所有物品的箱子的表面积。由于问题的复杂性和求解难度,此类问题非常难以获得最优解,而大部分启发式算法又缺乏普适性。所以本文尝试将Pointer Net框架和基于深度强化学习的方法应用到了对此类问题的优化求解中。本文基于大量实际数据对网络模型进行了训练和验证,数值实验的结果表明基于深度强化学习方法获得的结果显著好于已有的启发式算法。本项研究的主要贡献包括:第一,提出了一类新型的三维装箱问题;第二,将深度强化学习技术应用到了此类新问题的求解中。在之后的研究中将会深入探索更有效的网络模型和训练算法,并且会尝试将物品的摆放位置和朝向的选择整合到模型中。
附录:
A: 三维装箱问题的启发式算法
用于求解本文的新型三维装箱问题的启发式算法包括最小表面积(least surface area)算法和最小浪费空间(least wastespace)算法。算法的详细步骤如下所示:



B:关于新型三维装箱问题为NP-hard问题的证明
引理B.1: 本文提出的新型三维装箱问题为NP-hard问题。
证明:



 关注「技术边城」把握前沿技术脉搏
关注「技术边城」把握前沿技术脉搏

















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









