







对于下一个练习,我提供了一个Profiler类,它包含代码,使用一系列问题规模运行方法,测量运行时间和绘制结果。
你将使用
Profiler,为 Java 的实现ArrayList和LinkedList,划分add方法的性能。
Profiler.java包含上述Profiler类的实现。你会使用这个类,但你不必知道它如何工作。但可以随时阅读源码。ProfileListAdd.java包含此练习的起始代码,包括上面的示例,它测量了ArrayList.add。你将修改此文件来测量其他一些方法。
2.ArrayList的尾部添加
示例,展示如何使用分析器
public static void profileArrayListAddEnd() {
Profiler.Timeable timeable = new Profiler.Timeable() {
List<String> list;
@Override
public void setup(int n) {
list = new ArrayList<String>();//执行在启动计时之前所需的任何工作
}
@Override
public void timeMe(int n) { //执行我们试图测量的任何操作
for (int i=0; i<n; i++) {
list.add("anything");
}
}
};
Profiler profiler = new Profiler("ArrayListAddEnd",timeable);
int startN = 4000;
int endMils = 1000;
//绘制图像(好像MATLAB)
XYSeries series = profiler.timingLoop(startN,endMils);
profiler.plotResults(series);
}
此方法测量在ArrayList上运行add所需的时间,它向末尾添加新元素。
为了使用
Profiler,我们需要创建一个Timeable,它提供两个方法:setup和timeMe。
setup方法执行在启动计时之前所需的任何工作;这里它会创建一个空列表。- 然后
timeMe执行我们试图测量的任何操作;这里它将n个元素添加到列表中。
Profiler提供了timingLoop,它使用存储为实例变量的Timeable。它多次调用Timeable对象上的timeMe方法,使用一系列的n值。timingLoop接受两个参数:
startN是n的值,计时循环应该从它开始。endMillis是以毫秒为单位的阈值。随着timingLoop增加问题规模,运行时间增加;当运行时间超过此阈值时,timingLoop停止。
当你运行实验时,你可能需要调整这些参数。如果startN太低,运行时间可能太短,无法准确测量。如果endMillis太低,你可能无法获得足够的数据,来查看问题规模和运行时间之间的明确关系。
4000, 3
8000, 0
16000, 1
32000, 2
64000, 3
128000, 6
256000, 18
512000, 30
1024000, 88
2048000, 185
4096000, 242
8192000, 544
16384000, 1325 (超过预定时间)
第一列是问题规模,n;第二列是以毫秒为单位的运行时间。前几个测量非常嘈杂;最好将startN设置在64000左右。(每次得出的结果不同,可具体分析,最后得出一张图,如图所示)
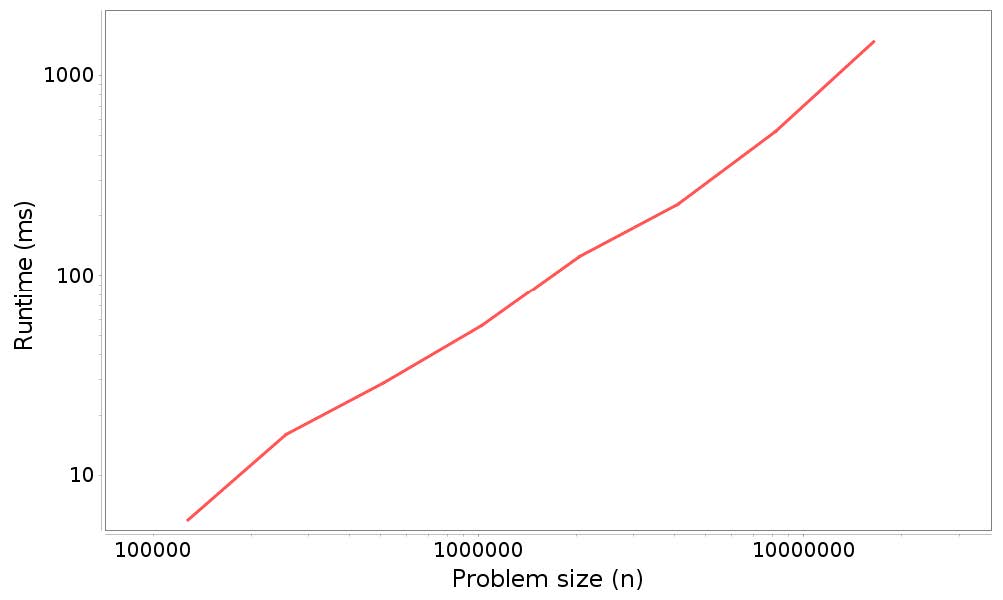
结果分析:
基于我们对
ArrayList工作方式的理解,我们期望,在添加元素到最后时,add方法需要常数时间。所以添加n个元素的总时间应该是线性的。为了测试这个理论,我们可以绘制总运行时间和问题规模,我们应该看到一条直线,至少对于大到足以准确测量的问题规模。在数学上,我们可以为这条直线编写一个函数:
runtime = a + b * n
其中a是线的截距,b是斜率。
另一方面,如果add是线性的,则n次添加的总时间将是平方。如果我们绘制运行时间与问题规模,我们预计会看到抛物线。或者在数学上,像:
runtime = a + b * n + c * n^2
对于n的较大值,最大指数项是最重要的,因此:
runtime ≈ c * n^k
其中≈意思是“大致相等”。现在,如果我们对这个方程的两边取对数:
log(runtime) ≈ log(c) + k * log(n)
这个方程式意味着,如果我们在重对数合度上绘制运行时间与n,我们预计看到一条直线,截距为log(c),斜率为k。我们不太在意截距,但斜率表示增长级别:如果k = 1,算法是线性的;如果k = 2,则为平方的。
看上一节中的数字,你可以通过眼睛来估计斜率。但是当你调用plotResults它时,会计算数据的最小二乘拟合并打印估计的斜率。在这个例子中:
Estimated slope = 1.06194352346708(这个值是不一定的)
它接近1;并且这表明n次添加的总时间是线性的,所以每个添加是常数时间,像预期的那样。
其中重要的一点:如果你在图形看到这样的直线,这并不意味着该算法是线性的。如果对于任何指数k,运行时间与n ** k成正比,我们预计看到斜率为k的直线。如果斜率接近1,则表明算法是线性的。如果接近2,它可能是平方的。
3.ArrayList的首部添加
预估:
我们每次在ArrayList的首部进行添加,需要移动n个元素,执行n次,所以我们预估时间复杂度为O(n^2).斜率接近于2.
public static void profileArrayListAddBeginning() {
Profiler.Timeable timeable = new Profiler.Timeable() {
List<String> list;
@Override
public void setup(int n) {
list = new ArrayList<String>();
}
@Override
public void timeMe(int n) {
for (int i=0; i<n; i++) {
list.add(0,"anything"); //使用双参方法,不断把最新的元素放到ArrayList首位
}
}
};
int startN = 4000;
int endMillis = 10000;
runProfiler("ArrayList add beginning", timeable, startN, endMillis);
}
这个方法几乎和profileArrayListAddEnd相同。唯一的区别在于timeMe,它使用add的双参数版本,将新元素置于下标0处。同样,我们增加了endMillis,来获取一个额外的数据点。
以下是时间结果(左侧是问题规模,右侧是运行时间,单位为毫秒):
4000, 14
8000, 35
16000, 150
32000, 604
64000, 2518
128000, 11555
以下是运行时间和问题规模曲线:
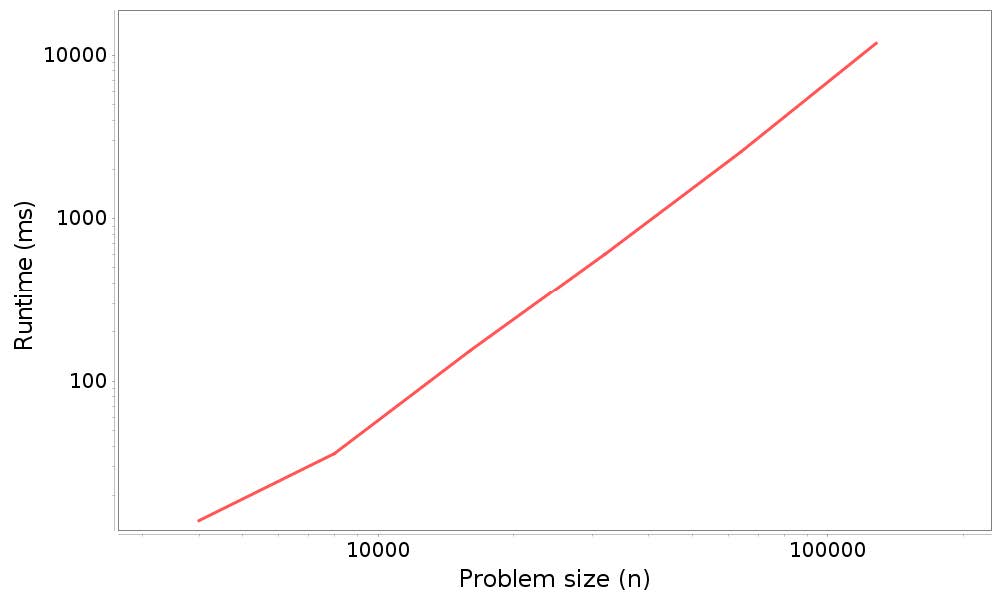
分析结果:
请记住,该图上的直线并不意味着该算法是线性的。相反,如果对于任何指数k,运行时间与n ^ k成正比,我们预计会看到斜率为k的直线。在这种情况下,我们预计,n次添加的总时间与n ^ 2成正比,所以我们预计会有一条斜率为2的直线。实际上,估计的斜率是1.992,非常接近。恐怕假数据才能做得这么好。(还是看斜率,与预期相符合)
4.LInkedList的首部添加
预估:
LinkedList首部添加不需要移动元素,操作时间复杂度为O(1),操作n次,预估时间复杂度为O(n^2),预估他是线性的.
public static void profileLinkedListAddBegining() {
Profiler.Timeable timeable = new Profiler.Timeable() {
List<String> list;
@Override
public void setup(int n) {
list = new LinkedList<String>(); //这边初始化为LinkedList
}
@Override
public void timeMe(int n) {
for (int i=0; i<n; i++) {
list.add(0,"lalalalala");
}
}
};
int startN = 128000; //这些数值是慢慢测试出来的
int endMils = 2000;
runProfiler("LinkedList add beginning",timeable,startN,endMils);
}
测试结果(有一点嘈杂这个结果):
128000, 16
256000, 19
512000, 28
1024000, 77
2048000, 330
4096000, 892
8192000, 1047
16384000, 4755
以下是运行时间和问题规模曲线:

结果分析:
并不是一条很直的线,斜率也不是正好是1,最小二乘拟合的斜率是1.23。但是结果表示,n次添加的总时间至少近似于O(n),所以每次添加都是常数时间。
5.LinkedList的尾部添加
预估:
LinkedList的尾部添加,需要逐个便利,操作是线性的,为O(n),操作n次,时间复杂度为O(n^2).
public static void profileLinkedListAddEnd() {
Profiler.Timeable timeable = new Profiler.Timeable() {
List<String> list;
@Override
public void setup(int n) {
list = new LinkedList<String>();
}
@Override
public void timeMe(int n) {
for (int i=0; i<n; i++) {
list.add("CN DOTA BEST DOTA");
}
}
};
int startN = 64000;
int endMils = 1000;
runProfiler("LinkedListAddEnd",timeable,startN,endMils);
}
测试结果:
64000, 9
128000, 9
256000, 21
512000, 24
1024000, 78
2048000, 235
4096000, 851
8192000, 950
16384000, 6160
以下是运行时间和问题规模曲线:
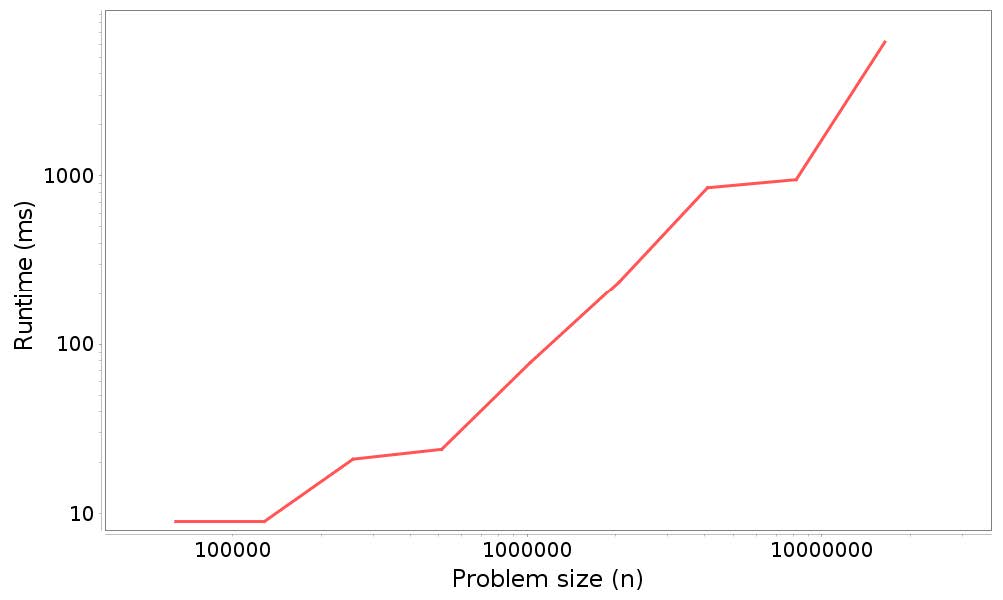
结果分析:
同样,测量值很嘈杂,线不完全是直的,但估计的斜率为1.19,接近于在头部添加元素,而并不非常接近2,这是我们根据分析的预期。事实上,它接近1,这表明在尾部添加元素是常数元素。(思考一个问题,它的问题规模为什么这么大,大概有0.2的偏差,经验证,问题规模在400w的时候会有一个明显的下降)
原书链接:https://wizardforcel.gitbooks.io/think-dast/content/5.html
GitHub链接(提供源码):https://github.com/huoji555/Shadow/tree/master/DataStructure















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









