







理想的数据集D,其中x,y都符合理想的分布,但是现实中的数据集,一般存在一定的噪声,存在一定的标签错误,定义这个数据集为
D
~
\tilde{D}
D~,数据为x,
y
~
\tilde{y}
y~。
这两个数据集之前存在一个转换矩阵
T
(
X
)
T(X)
T(X),
T
i
,
j
(
X
)
T_{i,j}(X)
Ti,j(X)表示在数据集X下,标签为i的数据被错误分配成标签j的概率。
只与类有关的噪声标签

第一种假设是类相关噪声,在这种情况下我们不考虑数据集特征的影响,我们假设数据集的特征和标签噪声是独立的。
第一种是对称T,即转移到其他类的概率是 ϵ \epsilon ϵ,这样保留在原始标签的概率是 1 − ϵ 1-\epsilon 1−ϵ,转移到其他任意一个标签的概率是 ϵ K − 1 \frac{\epsilon}{K-1} K−1ϵ。

第二种是非对称T,有两种假设:
- 标签i被错误标记成(i+1)%K的概率为 ϵ \epsilon ϵ
- 标签对 ( i c , j c ) (i_c, j_c) (ic,jc)互相错误分配的概率为 ϵ \epsilon ϵ
与实例有关的噪声标签

那明显,只与类有关的噪声标签,很大程度上脱离了现实情况,一张图片,有可能很容易分辨,那么就会以接近100%的概率被正确分类,但是如果比较模糊,ambiguous,那被正确分类的概率就会小一点。因此转移矩阵T也应该与X有关。
有一些技术可以合成与实例相关的标签噪声,例如多项式边缘递减标签噪声(Zhang等人;2021b),其中靠近决策边界的实例更容易被错误标记,部分依赖的标签噪声(Xia等,2020b),其中不同部分的特征可能贡献不同的噪声转移矩阵,以及组依赖的标签噪声(Wang等,2021a;Zhu等人,2021a),其中不同的亚种群可能具有不同的噪声率。

人类标注数据集,通过Amazon Mechanical Turk进行标注。分别是CIFAR-10和CIFAR-100,标注完记为CIFAR10N和CIFAR100N。
CIFAR-10N
对于CIFAR10而言,每一张图片有1个原始标签,和3个人类标注标签。作者定义了五种噪声标签数据集:
- Aggregate: 聚合三个人工标注结果,选取最多的作为标签,如果三个各不相同,随机选择
- Random i: 选择每张图片的第i次提交结果, i ∈ { 1 , 2 , 3 } i \in \{1,2,3\} i∈{1,2,3}
- Worst:只选择标错的标签,有多个标错的就从标错的里面随机选择。(只选择错的)
最终结果,有60.27%的完全无异议,aggregate方法存在9.03%的噪声。

CIFAR-100N
直接看结果

观察结果
1. 不平衡标注

有的标签被错误分配得多,有的标签少。
2. 嘈杂的标签翻转到相似的特征
就算被错误标记,也是在相似的特征图片之间错误分类,错误的结果不会偏离太多,例如“蛇”类数据的错误标签,一般不会多于4个,大约20%的蛇和蠕虫被相互错误分类。

3. 噪声转移矩阵的模式
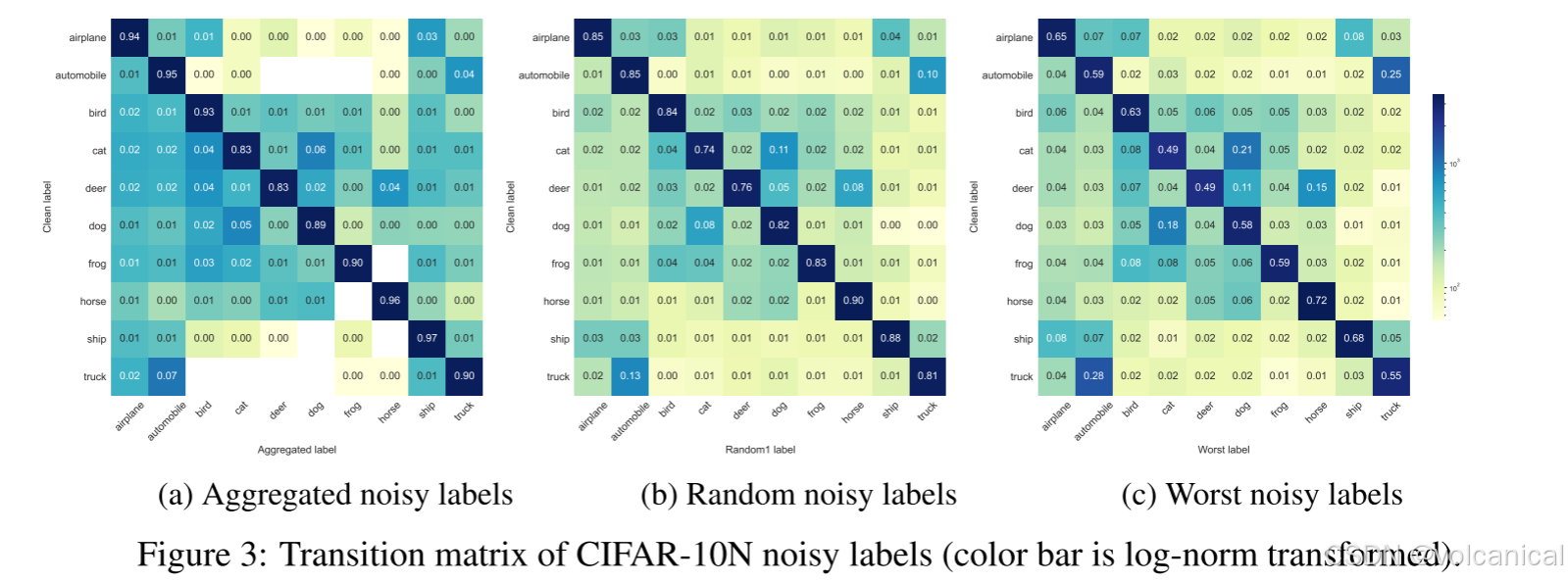
一样的结果,某些类之间的错误标记概率更高,真实世界的噪声标签比合成噪声标签复杂得多。
4. 噪声标签是好是坏?

一张图片可能不止一个标签,例如一个人抱着一条鱼,官方标注可能是鱼,但是人类错误地标注成人其实也是正确的,这是一个值得探讨的问题。


















 190
190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











