







- 第1章 对大型语言模型的介绍
- 第2章 分词和嵌入
- 第3章 解析大型语言模型的内部机制
- 第4章 文本分类
- 第5章 文本聚类与主题建模
- 第7章 高级文本生成技术与工具
- 第8章 语义搜索与检索增强生成
- 第9章 多模态大语言模型
- 第10章 构建文本嵌入模型
- 第11章 面向分类任务的表示模型微调
- 第12章 微调生成模型
本书前几章中,我们迈出了进入大语言模型(LLMs)世界的第一步。我们探讨了监督分类和非监督分类等各类应用,并使用了以文本表征为核心的模型,如BERT及其衍生模型。
随着学习的深入,我们开始使用以文本生成为主要训练目标的模型——这类模型通常被称为生成式预训练Transformer(GPT)。这些模型具有根据用户提示生成文本的卓越能力。通过提示工程(prompt engineering)技术,我们可以设计出能提升生成文本质量的提示模板。
本章将更详细地探索这些生成式模型,深入研究提示工程、基于生成模型的推理过程、结果验证,乃至评估其输出质量的方法论。通过系统性的学习路径,读者不仅能掌握生成式AI的核心原理,更能获得实际应用中的关键技巧。
使用文本生成模型
在深入探讨提示工程的基础知识之前,我们有必要先掌握文本生成模型的基本应用方法。我们需要如何选择适用的模型?应当采用商业授权模型还是开源模型?又该如何控制生成内容的输出?这些问题将作为我们踏入文本生成模型应用领域的基石。
选择文本生成模型
选择文本生成模型始于专有模型与开源模型之间的抉择。尽管专有模型通常性能更优,但本书着重探讨开源模型——它们不仅提供更高的灵活性,还完全免费可供使用。
图6-1展示了具有影响力的基础模型(LLMs)中的代表性示例。这些大语言模型通过预训练海量文本数据构建,并常针对特定应用场景进行微调优化。
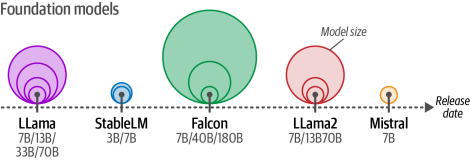
图6-1基础模型通常会以多种不同尺寸发布
从这些基础模型出发,已经衍生出数百甚至数千个经过微调的模型,每个模型都比其他模型更适用于特定任务。选择使用哪个模型可能是一项艰巨的任务!
我们建议从小型基础模型入手。因此继续使用参数量为38亿的Phi-3-mini模型,这使得它能够适配最高8GB显存的设备运行。总体而言,将模型规模升级往往比降级能带来更优的体验。小型模型既能提供绝佳的入门体验,又能为后续进阶大型模型打下坚实基础。
加载文本生成模型
加载模型的最直接方法——正如我们在前几章中所做的那样——是借助transformer库实现:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
# Create a pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
return_full_text=False,
max_new_tokens=500,
do_sample=False,
)与前面的章节相比,本章我们将更详细地探讨提示模板的开发与使用。例如,让我们回顾一下第1章中的案例:其中要求大型语言模型(LLM)编一个关于鸡的笑话:
# Prompt
messages = [
{"role": "user", "content": "Create a funny joke about chickens."}
]
# Generate the output
output = pipe(messages)
print(output[0]["generated_text"])Why don't chickens like to go to the gym? Because they can't crack the eggsistence of it!
在底层,transformers.pipeline 会先将我们的消息转换为特定的提示模板。我们可以通过访问底层的词元器(tokenizer)来探索这一过程:
# Apply prompt template
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False)
print(prompt)<s><|user|>
Create a funny joke about chickens.<|end|>
<|assistant|>
你可能在第2章中已经认识了<|user|>和<|assistant|>这两个特殊词元。如图6-2所示,这个提示模板在训练模型时被使用。它不仅能够标识说话人身份(谁说了什么),还通过<|end|>词元来指示模型何时应停止生成文本。整个提示会直接传递给大语言模型(LLM),并由其一次性处理完毕。
在下一章中,我们将学习如何自定义模板的部分内容。本章全程可以使用transformers.pipeline工具来自动处理聊天模板的加工流程。接下来,让我们探索如何控制模型的输出结果。
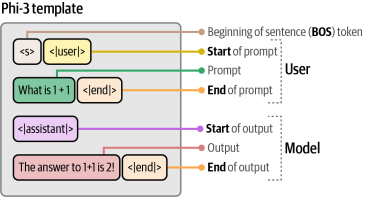
图6-2. Phi-3模板在与模型交互时所期望的(内容/格式)
控制模型输出
除了提示工程之外,我们还可以通过调整模型参数来控制期望的输出类型。在之前的示例中,您可能已经注意到我们在pipe函数中使用了多个参数,包括temperature和top_p。这些参数控制着输出的随机性。使大语言模型成为令人兴奋的技术的一部分原因在于,对于完全相同的提示,它可以生成不同的响应。每当大语言模型需要生成一个词元时,它会为每个可能的词元分配概率值。
如图6-3所示,在"I am driving a..."这个句子中,接续"car"(汽车)或"truck"(卡车)这类词元的概率通常会高于"elephant"(大象)。不过生成"大象"的可能性仍然存在,只不过要低得多。这种基于概率的生成机制,既保证了语言模型的创造性,也通过参数调控实现了对输出多样性的精确把握。
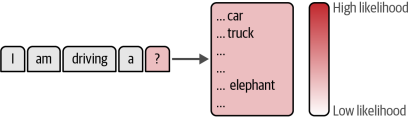
图6-3 该模型基于其概率得分选择下一个要生成的词元
当我们加载模型时,故意设置了 do_sample=False 以保证输出大致一致。这意味着不会进行任何采样,而只会选择最有可能的下一个词元。不过,若要使用 temperature 和 top_p 参数,我们需要将 do_sample=True,以便利用这两个参数。
温度
温度控制生成文本的随机性或创造性。它决定了选择低概率词汇的可能性大小。基本原理是:当温度为0时(如图6-4所示),模型每次都会输出完全相同的响应,因为此时只会选择概率最高的那个词汇。随着温度值的升高,系统会逐渐允许出现概率较低的词汇,从而增强生成内容的多样性。
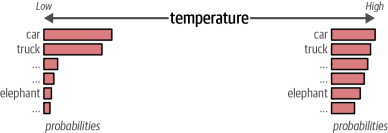
图6-4 温度越高,生成低概率词元的可能性越大,反之亦然
因此,较高的温度(例如,0.8)通常会导致更多样化的输出,而较低的温 度(例如,0.2)则会产生更具确定性的输出。
可以使用管道中的温度:
# Using a high temperature
output = pipe(messages, do_sample=True, temperature=1)
print(output[0]["generated_text"])Why don't chickens like to go on a rollercoaster? Because they're afraid they might suddenly become chicken-soup!
请注意,每次重新运行此代码片段时,输出结果都会发生变化!这是因为温度
(temperature)参数引入了随机行为——模型现在会根据概率分布随机选择词元(tokens)。
top_p
top_p(也称为核采样)是一种控制大语言模型(LLM)可考虑哪些token子集(即核)的采样技术。当累积概率达到设定阈值时,模型将停止考虑更多token。若将top_p设为0.1,模型只会考虑累积概率达到该阈值前的token;若设为1,则会评估所有token。
如图6-5所示,降低top_p值会减少模型考虑的token数量,通常会产生较不"创意"的输出;而提高该值则允许模型从更多token中进行选择,从而增强生成多样性。这种参数调节机制为平衡输出确定性(低top_p)与创造性(高top_p)提供了有效手段。
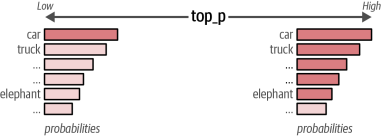
图6-5 较高的top_p值会增加可选用于生成的token数量,反之亦然
同样,top_k 参数用于精确控制大语言模型(LLM)需要考虑的词元(token)数量。如果将其值更改为 100,则 LLM 将仅考虑概率最高的前 100 个词元。您可以在流水线中按以下方式使用 top_p:
# Using a high top_p
output = pipe(messages, do_sample=True, top_p=1)
print(output[0]["generated_text"])如表6-1所示,这些参数使用户能够在保持创意性(高温、较高的top_p值)与确保可预测性(低温、较低的top_p值)之间进行灵活调整。通过调节这两个参数,用户可以创建出从高度随机创意到高度模式化输出的不同风格的生成结果,这种设计为内容创作提供了可控的探索空间。
表6-1. 温度与top_p参数取值选择场景示例
| 示例用例 | 温度 | top_p | 描述 |
| 头脑风暴会议 | 高 | 高 | 具有极高的随机性,同时拥有庞大的潜在词元资源库。生成结果将呈现高度多样性,往往能够产生极具创意且出人意料的效果。 |
| 电子邮件生成 | 低 | 低 | 通过高概率预测词元生成的确定性输出。这会导致输出结果具有可预测性、专注性和保守性 |
| 创意写作 | 高 | 低 | 高随机性与有限潜在词元的结合。这种组合既能产生富有创意的输出,仍能保持逻辑连贯性。 |
| 翻译 | 低 | 高 | 确定性输出结合高概率预测词元,生成连贯且词汇丰富的结果,从而实现语言多样性。 |
提示工程入门
与文本生成大语言模型(LLMs)协作时,提示工程(prompt engineering)是核心环节。通过精心设计提示词,我们能够引导大语言模型生成符合预期的回答。无论是提问、陈述还是指令形式,提示工程的核心目标都是从模型中获取有效回应。
提示工程不仅限于设计有效提示词,它还可作为评估模型输出质量的工具,并用于构建安全防护机制与风险缓解策略。这一过程需要持续的实验优化,且不存在也不可能存在完美的提示设计方案。
本节将探讨常见的提示工程方法,并分享一些实用技巧,帮助理解特定提示词的实际效果。这些技能不仅能帮助我们掌握大语言模型的能力边界,更是实现人机交互的基础。
首先需要解答的问题是:提示中应包含哪些关键要素?
提示的基本要素
大语言模型本质上是一个预测机器。基于特定的输入(即提示词),它会尝试预测可能随之而来的词语。如图6-6所示,在其核心机制中,提示词只需几个词就能引发大语言模型的响应。
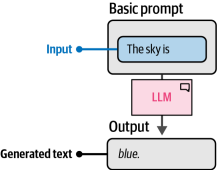
图6-6. 提示的基本示例。由于未提供具体指令,该大语言模型将尝试直接补全句子
然而,尽管该示例作为一个基础案例能够说明问题,但它未能完成特定任务。实际上,我们通常通过向大语言模型提出具体问题或任务来开展提示工程。为了获得预期的响应,我们需要构建结构更清晰的提示框架。
例如(如图6-7所示),我们可以要求大语言模型对句子进行积极或消极情感分类。这种设计将最基础的"提示工程入门"示例(| 173)扩展为由两个核心要素构成的提示结构——即明确的指令本身,以及与指令相关的具体数据。
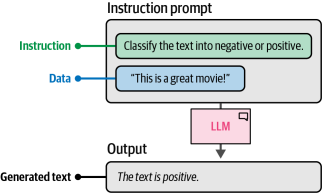
图6-7. 基本指令提示的两个组成要素:指令本身及其引用的数据
更复杂的应用场景可能需要提示词中包含更多组件。例如,为了确保模型仅输出"负面"或"正面",我们可以引入输出标识符来引导模型。如图6-8所示,我们在句子前添加"文本:"作为前缀,并冠以"情感:"标签,这样可以防止模型生成完整句子,而是通过这种结构明确要求从两个预设选项中选择答案。尽管模型可能未直接接受过这类组件的专项训练,但由于其接收过大量指令数据的训练,已具备足够的泛化能力来适应这种提示结构。
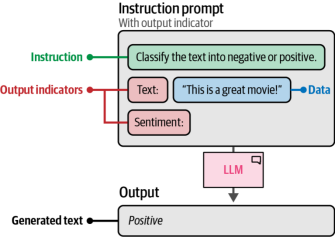
图6-8. 通过添加输出指示符扩展提示词以实现特定输出
我们可以通过持续添加或更新提示词的元素来引出我们想要的回应。我们可以添加更多示例、更详细地描述使用场景、提供额外背景信息等等。这些组成部分仅仅是示例而非限制性集合,设计这些元素时所迸发的创造力才是关键所在。
虽然提示词是一段独立的文本,但将其视为更大拼图中的碎片会极具启发性。我是否交代了问题的背景语境?提示词中是否包含期望输出的范例?
基于指令的提示
虽然提示(prompting)的形式多种多样——从与语言模型探讨哲学问题到与你最喜欢的超级英雄进行角色扮演——但提示技术通常用于让语言模型回答特定问题或完成具体任务。这种技术称为基于指令的提示(instruction-based prompting)。
图6-9展示了基于指令的提示发挥重要作用的多个应用场景。我们已经在本章前面的示例中实践过其中一种应用场景,即监督式分类任务(supervised classification)。
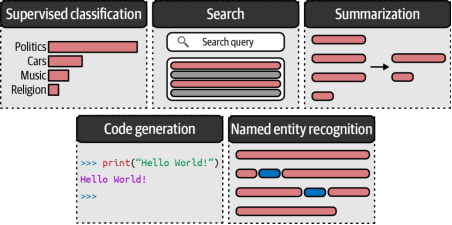
图6-9:基于指令的提示信息的用例
这些任务中的每一项都需要不同的提示格式,更具体地说,需要向大型语言模型(LLM)提出不同类型的问题。例如,要求LLM总结一段文本并不会自动触发分类功能。如图6-10所示,我们列举了部分应用场景下的提示词示例以作说明。

图6-10 常见用例的提示示例。请注意,在一个用例中,如何使用 指令的结构和位置可以被改变
虽然这些任务需要不同的指令,但用于提升输出质量的提示技巧实际上存在大量共通性。此类技术的非穷举清单包括:
明确性
要清晰阐述你的目标。不要笼统地要求大型语言模型(LLM)“撰写一段产品描述”,而是应明确指示:“在两句话以内,使用正式语气撰写一段产品描述。”
幻觉
大语言模型(LLMs)可能会自信地生成错误信息,这种现象被称为"幻觉"(hallucination)。为了减少其影响,我们可以要求大语言模型仅在确定答案时生成回复;若不知道答案,则回答"我不知道"。
顺序
将指令放在提示词的开头或结尾。尤其是较长的提示词,中间的信息容易被遗忘1。大语言模型通常更关注提示词开头(首因效应)或结尾(近因效应)的信息.
在这里,具体性(specificity)可以说是最重要的方面。通过限制并明确模型应该生成的内容范围,可以大幅降低其产生与应用场景无关内容的可能性。例如,如果我们省略"in two to three sentences"这个指令,模型可能会生成完整的段落。就像人类对话一样,若没有任何具体指示或补充背景信息,我们往往很难准确理解当前需要完成的实际任务是什么。
高级提示工程
表面上,创建一个优质的提示(prompt)似乎很简单:提出具体问题、确保准确性、添加示例,就能大功告成!然而在实际应用中,提示工程可能迅速变得复杂,因此它往往被低估为利用大型语言模型(LLMs)的关键要素。
本文将深入探讨构建提示的几种高级技巧,从搭建复杂提示的迭代式工作流程,到通过顺序调用多个大型语言模型以优化结果,最终我们将探索如何构建高级推理技术。
提示的潜在复杂性
正如我们在提示工程的介绍中所探讨的,提示通常由多个组件构成。在我们最初的示例中,提示包含了指令(instruction)、数据(data)和输出指示器(output indicators)。正如之前提到的,没有任何提示仅限于这三个组件——你可以根据需求将其构建得尽可能复杂。这些高级组件可以快速增加提示的复杂度。一些常见组件包括:
角色设定
描述LLM应承担的角色。例如,若要询问天体物理学相关问题,请使用“你是一位天体物理学专家”。
任务指令
具体任务内容。务必尽可能明确。我们不希望存在过多解读空间。
1 Nelson F. Liu et al. “Lost in the middle: How language models use long contexts.” arXiv preprint arXiv:2307.03172 (2023)
上下文
描述问题或任务背景的额外信息。它回答诸如“给出该指令的原因是什么?”之类的问题。
格式
大语言模型(LLM)应使用的输出文本格式。若不指定格式,LLM会自行决定格式,这在自动化系统中可能会带来麻烦。
受众
生成文本的目标对象。这也决定了输出内容的复杂度级别。例如教育场景中,使用ELI5(“像给五岁孩子解释一样”)风格会更有帮助。
语气
生成文本应采用的语调。例如给上级写正式邮件时,可能需要避免使用非正式语气。
数据
与任务本身相关的核心信息。
为了具体说明这一点,让我们扩展之前使用的分类提示模板,并整合前面提到的所有组件(如图6-11所示)。这种复合型提示展示了提示工程的模块化特性——我们可以自由增删组件并评估其对输出效果的影响。如图6-12演示的那样,可以通过渐进式构建提示的方式,系统性地探索每个调整带来的变化。
值得注意的是,优化过程不仅限于组件的简单叠加或移除。正如我们之前讨论过的近因效应和首因效应所示,组件排列顺序会显著影响大语言模型的输出质量。这意味着在寻找最佳提示方案时,实验验证是至关重要的。通过这种提示工程方法,我们实际上进入了一个持续迭代的实验循环过程。
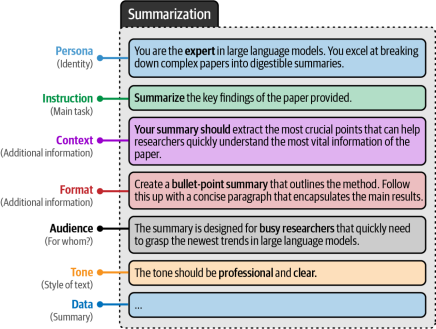
图6-11 一个包含多个组件的复杂提示示例
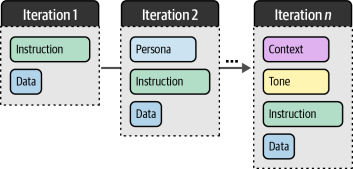
图6-12. 迭代式地调整模块化组件是提示工程的关键环节。
赶快亲自试试吧!通过使用复杂提示词来添加和/或删除部分内容,观察其对生成结果的影响。你会很快发现哪些拼图碎片值得保留。只需将你的数据添加到data变量中,即可使用自己的数据进行尝试:
# Prompt components
persona = "You are an expert in Large Language models. You excel at breaking
down complex papers into digestible summaries.\n"
instruction = "Summarize the key findings of the paper provided.\n"
context = "Your summary should extract the most crucial points that can help
researchers quickly understand the most vital information of the paper.\n"
data_format = "Create a bullet-point summary that outlines the method. Follow
this up with a concise paragraph that encapsulates the main results.\n"
audience = "The summary is designed for busy researchers that quickly need to
grasp the newest trends in Large Language Models.\n"
tone = "The tone should be professional and clear.\n"
text = "MY TEXT TO SUMMARIZE"
data = f"Text to summarize: {text}"
# The full prompt - remove and add pieces to view its impact on the generated
output
query = persona + instruction + context + data_format + audience + tone + data我们可以添加各种类型的组件,甚至能发挥创意使用情感刺激类组件(例如,This is very important for my career.2)。提示工程(prompt engineering)的乐趣之一在于,你可以充分发挥创造力,探索哪些提示组件组合最适合你的具体用例。制定适合自身需求的格式时几乎不受限制。
从某种意义上说,这是在尝试逆向解析模型的学习机制及其对特定提示的响应逻辑。不过需注意,由于训练数据可能存在差异或训练目标不同,某些提示对特定模型的效果会优于其他模型。
上下文学习:提供示例
在前面的章节中,我们尝试准确描述大语言模型(LLM)应该完成的任务。虽然准确且具体的描述有助于模型理解应用场景,但我们可以更进一步。与其单纯描述任务要求,不如直接向模型展示任务范例。这种方法通常被称为"上下文学习"——通过向模型提供正确的示例进行示范3。
2 Cheng Li et al. “EmotionPrompt: Leveraging psychology for large language models enhancement via emo‐ tional stimulus.” arXiv preprint arXiv:2307.11760 (2023).
3 Tom Brown et al. “Language models are few-shot learners.” Advances in Neural Information Processing Systems 33 (2020): 1877–1901.
如图6-13所示,根据向大型语言模型(LLM)展示的示例数量,提示(prompting)可分为多种形式:零样本提示(zero-shot prompting)不利用示例,单样本提示(one-shot prompting)使用单个示例,而少样本提示(few-shot prompting)则使用两个或更多示例。

图6-13. 包含多个组件的复杂提示示例
我们采用原话“一个例子胜过千言万语”,认为示例能直观展现大型语言模型(LLM)需要实现的目标与路径。该方法的核心理念可通过其原始论文中的一个简单示例阐明[4]:当需要生成包含虚构词汇的句子时,通过向生成模型展示符合要求的范例(即正确使用虚构词的参考句式),能有效提升输出质量。在此过程中,我们需明确区分用户提问(user)与模型回答(assistant),并通过标准化模板展示这种人机交互的处理流程:
# Use a single example of using the made-up word in a sentence
one_shot_prompt = [
{
"role": "user",
"content": "A 'Gigamuru' is a type of Japanese musical instrument. An example of a sentence that uses the word Gigamuru is:”
},
{
"role": "assistant",
"content": "I have a Gigamuru that my uncle gave me as a gift. I love to play it at home."
},
{
"role": "user",
"content": "To 'screeg' something is to swing a sword at it. An example of a sentence that uses the word screeg is:"
}
]
print(tokenizer.apply_chat_template(one_shot_prompt, tokenize=False))<s><|user|>
A 'Gigamuru' is a type of Japanese musical instrument. An example of a sentence that uses the word Gigamuru is:<|end|>
<|assistant|>
I have a Gigamuru that my uncle gave me as a gift. I love to play it at home.<| end|>
<|user|>
To 'screeg' something is to swing a sword at it. An example of a sentence that uses the word screeg is:<|end|>
<|assistant|>
该提示说明了区分用户与助手的必要性。若不进行区分,对话将呈现为系统在自说自话的效果。基于这种交互模式,我们可以生成如下对话输出:
# Generate the output
outputs = pipe(one_shot_prompt)
print(outputs[0]["generated_text"])During the intense duel, the knight skillfully screeged his opponent's shield, forcing him to defend himself.
它正确地生成了答案!
与所有提示组件一样,单样本或少样本提示并非提示工程的终极解决方案。我们可以将其作为拼图中的一块,进一步优化对模型的描述。然而需注意,由于模型依赖随机采样机制,它仍有可能"选择"忽视我们的指令。
链式提示:分步拆解问题
在之前的示例中,我们探讨了将提示拆分为模块化组件以提升大型语言模型性能的方法。虽然这对许多用例效果良好,但对于高度复杂的提示或场景可能并不适用。
此时,我们不必在单个提示内拆分问题,而是可以在多个提示之间进行任务拆解。其核心原理是将前一个提示的输出作为下一个提示的输入,从而构建连续的交互链条来解决复杂问题。
例如,假设我们想利用大型语言模型(LLM),根据一系列产品特性来生成产品名称、标语和销售文案。虽然我们可以要求大语言模型一次性完成这些任务,但也可以将问题拆解为多个步骤。如图6-14所示,这种拆分方式会形成一个顺序处理流程:首先生成产品名称,接着将该名称与产品特性共同作为输入生成标语,最终综合产品特性、产品名称和标语来生成完整的销售文案。
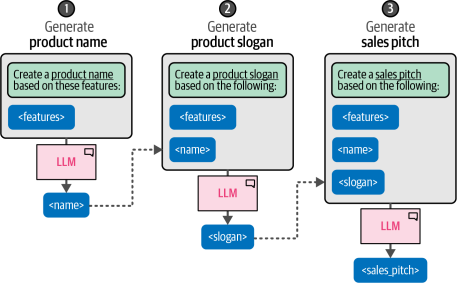
图6-14 基于产品特性描述,通过链式提示生成适配的命名、广告语及销售话术
这种"提示链"技术能够让大语言模型专注于单个问题而非整个任务。我们通过一个小例子来说明:首先为聊天机器人设计一个名称和标语:
# Create name and slogan for a product
product_prompt = [
{"role": "user", "content": "Create a name and slogan for a chatbot that leverages LLMs."}
]
outputs = pipe(product_prompt)
product_description = outputs[0]["generated_text"]
print(product_description)Name: 'MindMeld Messenger'
Slogan: 'Unleashing Intelligent Conversations, One Response at a Time’
然后,我们可以使用生成的输出作为LLM的输入来生成一个销售方案:
# Based on a name and slogan for a product, generate a sales pitch
sales_prompt = [
{"role": "user", "content": f"Generate a very short sales pitch for the =following product: '{product_description}'"}
]
outputs = pipe(sales_prompt)
sales_pitch = outputs[0]["generated_text"]
print(sales_pitch)Introducing MindMeld Messenger - your ultimate communication partner! Unleash intelligent conversations with our innovative AI-powered messaging platform. With MindMeld Messenger, every response is thoughtful, personalized, and timely. Say goodbye to generic replies and hello to meaningful interactions. Elevate your communication game with MindMeld Messenger - where every message is a step toward smarter conversations. Try it now and experience the future
of messaging!
尽管需要两次调用模型,但主要优势在于我们可以分别为每次调用设置不同的参数。例如,生成名称和标语时产生的词元数量相对较少,而生成宣传文案则可以更长。
这可以应用于多种场景,包括:
响应验证
要求LLM对先前生成的内容进行二次核查。
并行提示
通过并行创建多个提示并进行最终整合。例如,可以同时要求多个LLM生成多份食谱,再综合结果生成购物清单。
故事创作
通过将问题拆解为组件(如先撰写摘要、塑造角色、构建故事节奏,最后设计对话),利用LLM完成书籍或故事的创作。
在下一章中,我们将超越单纯的LLM链式调用,进一步实现自动化流程,并整合记忆、工具调用等更多技术!
在此之前,后续章节将深入探讨更复杂的提示链方法,包括自我一致性(Self-Consistency)、思维链(Chain-of-Thought)和思维树(Tree-of-Thought)。
用生成模型进行推理
在前面的章节中,我们主要聚焦于提示工程的模块化组件,通过迭代方式逐步构建提示框架。这些高级提示工程技术——例如提示链(prompt chaining)——已被证实是推动生成式模型实现复杂推理能力的重要基石。
推理是人类智能的核心组成部分,常被比作大型语言模型(LLMs)表现出的类推理行为。我们强调"类"这一限定词,因为就目前而言,这类模型的相关行为普遍被认为源于对训练数据的记忆与模式匹配,而非真正的推理。
尽管其输出结果可能展现出复杂行为,即便不涉及"真正"的推理,业界仍将其称为推理能力。换言之,我们通过提示工程(prompt engineering)与LLM协作,模拟推理过程以优化其输出效果。
为实现这种推理行为,有必要重新审视人类行为中的推理本质。简而言之,人类的推理方式可分为系统1与系统2两种思维模式:
- 系统1思维表现为自动化、直觉性和即时性特征,类似于生成模型自动输出词元(tokens)的过程,不涉及自我反思机制;
- 系统2思维则属于有意识、缓慢且逻辑化的思考过程,与头脑风暴和自我反思具有相似性。
若能使生成模型具备类自我反思能力,本质上即实现了对系统2思维的模拟。相较于系统1思维,系统2思维往往能产生更具深度的回应。本节将探讨多种试图模仿人类推理者此类思维模式的技术路径,旨在提升模型的输出质量。
思维链:在回答前先思考
生成式模型实现复杂推理的第一个关键步骤是通过一种名为"思维链"(chain-of-thought)的方法实现的。思维链旨在让生成式模型"先思考"而非直接给出未经推理的答案[6]。如图6-15所示,该方法通过在提示(prompt)中提供示范性推理样例,引导模型在生成回答前进行逻辑推演。这些推理过程被称为"思维步骤"。对于数学问题等需要较高复杂度的任务,这种方法具有显著效果。添加这种推理步骤后,模型能够在推理过程中分配更多计算资源。相较于基于少量输入直接计算完整解决方案,思维链中的每个额外token都能帮助大语言模型(LLM)更好地稳定输出结果。
5 Daniel Kahneman. Thinking, Fast and Slow. Macmillan (2011).
6 Jason Wei et al. “Chain-of-thought prompting elicits reasoning in large language models.” Advances in Neural Information Processing Systems 35 (2022): 24824–24837.
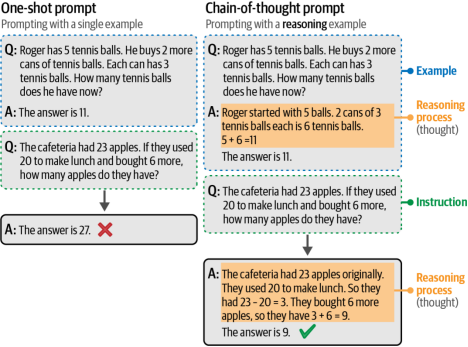
图6-15. 思维链提示通过使用推理示例来引导生成模型在其回答中运用推理过程
我们使用作者在论文中使用的例子来证明这一现象:
# Answering with chain-of-thought
cot_prompt = [
{"role": "user", "content": "Roger has 5 tennis balls. He buys 2 more cans
of tennis balls. Each can has 3 tennis balls. How many tennis balls does he
have now?"},
{"role": "assistant", "content": "Roger started with 5 balls. 2 cans of 3
tennis balls each is 6 tennis balls. 5 + 6 = 11. The answer is 11."},
{"role": "user", "content": "The cafeteria had 23 apples. If they used 20
to make lunch and bought 6 more, how many apples do they have?"}
]
# Generate the output
outputs = pipe(cot_prompt)
print(outputs[0]["generated_text"])The cafeteria started with 23 apples. They used 20 apples, so they had 23 - 20 = 3 apples left. Then they bought 6 more apples, so they now have 3 + 6 = 9 apples. The answer is 9.
请注意,该模型并非仅生成答案,而是在生成答案之前会提供解释。通过这种方式,模型可以利用迄今为止生成的知识来计算最终答案。
尽管思维链(chain-of-thought)是增强生成模型输出的强大方法,但它确实需要在提示中包含一个或多个推理示例,而用户可能无法获取这些示例。我们无需提供示例,而是可以直接要求生成模型进行推理(即零样本思维链)。虽然有许多不同的有效形式,但一种常见且高效的方法是使用"Let's think step-by-step"(让我们逐步思考)这一提示语,如图6-16所示。
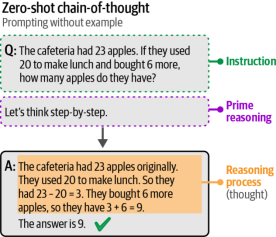
图6-16. 不使用示例的思维链提示。其通过使用"让我们一步步思考"这一短语来引导答案中的推理过程
通过使用我们之前用过的示例,我们可以简单地将该短语附加到提示词中,从而启发性地实现类似思维链的推理过程:
# Zero-shot chain-of-thought
zeroshot_cot_prompt = [
{"role": "user", "content": "The cafeteria had 23 apples. If they used 20
to make lunch and bought 6 more, how many apples do they have? Let's think
step-by-step."}
]
# Generate the output
outputs = pipe(zeroshot_cot_prompt)
print(outputs[0]["generated_text"])7 Takeshi Kojima et al. “Large language models are zero-shot reasoners.” Advances in Neural Information Processing Systems 35 (2022): 22199–22213.
Step 1: Start with the initial number of apples, which is 23.
Step 2: Subtract the number of apples used to make lunch, which is 20. So, 23 - 20 = 3 apples remaining.
Step 3: Add the number of apples bought, which is 6. So, 3 + 6 = 9 apples.
The cafeteria now has 9 apples.
即使无需提供示例,我们再次观察到了相同的推理行为。这正是为何在进行计算时需要“展示推导过程”——通过关注推理步骤,大型语言模型(LLM)能够将先前生成的信息作为生成最终答案的指引。
虽然“让我们逐步思考”这一提示可以提高输出质量,但你不必拘泥于这一确切表述。其他替代方式包括“深吸一口气,逐步分析”(Take a deep breath and think step-by-step)和“我们一步步解决这个问题吧”(Let’s work through this problem step-by-step)。
自一致性:采样输出
如果允许通过温度(temperature)和top_p等参数引入一定程度的创造性,多次使用同一提示词可能会得到不同的结果。因此,输出质量可能因随机选择的词元(token)而改善或下降——换句话说,这存在一定的运气成分!
为了抵消这种随机性并提升生成模型的性能,研究者提出了自一致性(self-consistency)方法。该方法会向生成模型多次提出同一提示词,并以多数结果作为最终答案。在此过程中,每次回答可能受不同的温度(temperature)和top_p值影响,从而增加采样的多样性。
如图6-17所示,此方法可通过结合思维链提示(chain-of-thought prompting)进一步优化:在保留答案用于投票流程的同时,借助思维链提升模型的推理能力。
8 Chengrun Yang et al. “Large language models as optimizers.” arXiv preprint arXiv:2309.03409 (2023).
9 Xuezhi Wang et al. “Self-consistency improves chain of thought reasoning in language models.” arXiv preprint arXiv:2203.11171 (2022).
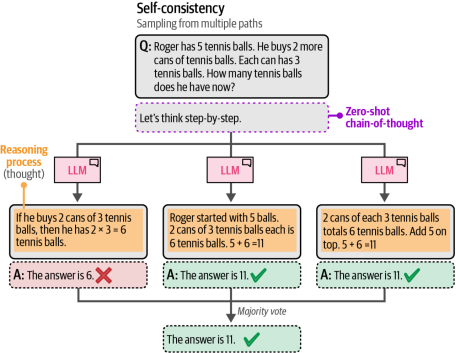
图6-17 通过从多条推理路径中进行采样,我们可以采用多数投票法来提取最可能的答案
然而,这确实需要多次提出同一个问题。因此,尽管该方法可以提升性能,但其速度会变为原来的n倍慢,其中n代表输出样本的数量。
思维树:探索中间推理步骤
思维链和自我一致性的理念旨在实现更复杂的推理。通过从多个"思维路径"中采样并增强其深度思考能力,我们旨在提升生成模型的输出质量。这些技术目前仅触及了模拟复杂推理的表层。在探索复杂推理的实践中,思维树(tree-of-thought)方法展现了改进潜力,它支持对多个思路进行深度探索。
该方法的工作机制如下:当面对需要多步推理的问题时,将其分解为若干子问题往往能提升解决效果。如图6-18所示,在每个推理步骤中,生成模型会被提示探索当前问题的不同解决方案。随后系统通过投票选择最优解,并基于此推进至下一推理阶段10。
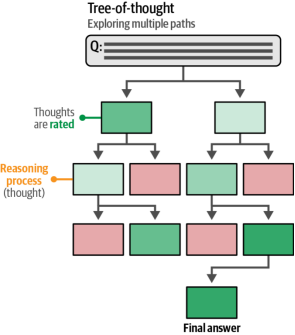
图6-18 通过利用基于树的架构,生成模型能够生成有待评分的中间思维。其中最具潜力的思维会被保留,而评分最低的思维则会被剪枝
这种方法在需要考虑多种路径时极为有用,比如在撰写故事或构思创意想法时。该方法的一个缺点是需要多次调用生成模型,这会显著降低应用程序的速度。幸运的是,已有成功尝试将思维树框架转化为一种简单的提示技术11。该方法无需多次调用生成模型,而是让模型通过模拟多位专家之间的对话来模仿这一行为。这些专家会相互质疑,直至达成共识。一个思维树提示的示例如下:
10 Shunyu Yao et al. “Tree of thoughts: Deliberate problem solving with large language models.” arXiv preprint arXiv:2305.10601 (2023).
11 “Using tree-of-thought prompting to boost ChatGPT’s reasoning.” Available at https://oreil.ly/a_Nos.
# Zero-shot tree-of-thought
zeroshot_tot_prompt = [
{"role": "user", "content": "Imagine three different experts are answering
this question. All experts will write down 1 step of their thinking, then share
it with the group. Then all experts will go on to the next step, etc. If any
expert realizes they're wrong at any point then they leave. The question is
'The cafeteria had 23 apples. If they used 20 to make lunch and bought 6 more,
how many apples do they have?' Make sure to discuss the results."}
]我们可以使用这个提示来探索一个LLM可能如何回答复杂的问题:
# Generate the output
outputs = pipe(zeroshot_tot_prompt)
print(outputs[0]["generated_text"])Expert 1: Step 1 - Start with the initial number of apples: 23 apples.
Expert 2: Step 1 - Subtract the apples used for lunch: 23 - 20 = 3 apples
remaining.
Expert 3: Step 1 - Add the newly bought apples: 3 + 6 = 9 apples.
Expert 1: Step 2 - Confirm the final count: The cafeteria has 9 apples.
Expert 2: Step 2 - Review the calculations: 23 - 20 = 3, then 3 + 6 = 9. The
calculations are correct.
Expert 3: Step 2 - Agree with the result: The cafeteria indeed has 9 apples.
All experts agree on the final count: The cafeteria has 9 apples.
我们再次通过一场“专家之间的讨论”得到了正确答案。看到这种体现提示工程创造力的“专家对话”实在有趣。
输出验证
使用生成式模型构建的系统及应用最终可能会投入生产环境。当这种情况发生时,验证和控制模型输出至关重要,这既能防止应用程序出现故障,又能打造稳健的生成式人工智能应用。
验证输出的原因可能包括:
结构化输出
默认情况下,大多数生成模型生成的是自由文本,除了自然语言本身定义的结构外,不会遵循特定的格式要求。但在某些应用场景中,用户可能需要模型输出符合特定格式的结构化内容(如 JSON)。
有效输出
即使允许模型生成结构化输出,它仍具备自由生成内容的能力。例如,当模型被要求在两个选项中择一时,不应生成第三种选项。
伦理规范
部分开源生成式模型缺乏防护机制,可能输出未考虑安全性或伦理要求的内容。例如,某些应用场景需确保输出内容不含粗俗语言、个人身份信息(PII)、偏见或文化刻板印象等。
准确性
许多应用场景要求输出内容符合特定标准或性能要求。核心目标是验证生成信息是否事实准确、逻辑连贯且不存在幻觉问题。
正如我们通过top_p和temperature等参数所探索的,控制生成模型的输出并非易事。这些模型需要借助外部手段才能生成符合特定规范的连贯输出。通常控制生成模型输出主要有三种方法:
示例引导法
提供预期输出的若干示例作为参考
语法控制法
通过控制词元(token)选择过程实现引导
模型微调法
在包含预期输出的数据集上对模型进行微调
在本章中,我们将探讨前两种方法。第三种方法——模型微调——则留待第十二章深入探讨其具体实现方式。
举例说明
修复输出的一个简单而直接的方法是为生成模型提供输出应该是什么样子的示 例。正如我们之前所探讨的,少镜头学习是一种指导生成模型输出的有用的技 术。该方法也可以推广到指导输出的结构。例如,让我们考虑一个例子,我们 希望生成模型为RPG游戏创建一个角色档案。我们首先不使用任何例子:
# Zero-shot learning: Providing no examples
zeroshot_prompt = [
{"role": "user", "content": "Create a character profile for an RPG game in
JSON format."}
]
# Generate the output
outputs = pipe(zeroshot_prompt)
print(outputs[0]["generated_text"])```json
{
"characterProfile": {
"name": "Eldrin Stormbringer",
"class": "Warlock",
"race": "Half-Elf",
"age": 27,
"gender": "Male",
"alignment": "Chaotic Good",
"background": "Rogue",
…
},
"attributes": {
"strength": 10,
"dexterity": 17,
"constitution": 12,
"intelligence": 12,
"wisdom": 10,
"charisma
前面的截断输出并非有效的 JSON,因为模型在开始生成 "charisma" 属性后停止了词元生成。此外,我们可能并不需要某些属性。相反,我们可以向模型提供多个示例来指定期望的格式:
# One-shot learning: Providing an example of the output structure
one_shot_template = """Create a short character profile for an RPG game. Make sure to only use this format:
{
"description": "A SHORT DESCRIPTION",
"name": "THE CHARACTER'S NAME",
"armor": "ONE PIECE OF ARMOR",
"weapon": "ONE OR MORE WEAPONS"
}
"""
one_shot_prompt = [
{"role": "user", "content": one_shot_template}
]
# Generate the output
outputs = pipe(one_shot_prompt)
print(outputs[0]["generated_text"]){
"description": "A cunning rogue with a mysterious past, skilled in stealth
and deception.",
"name": "Lysandra Shadowstep",
"armor": "Leather Cloak of the Night",
"weapon": "Dagger of Whispers, Throwing Knives"
}
该模型完美遵循了我们提供的示例,从而展现出更为稳定的表现。这也凸显了利用小样本学习优化输出结构(而非仅关注内容)的重要性。值得注意的是,模型是否遵循您建议的格式仍取决于其自身特性。不同模型在遵循指令方面的能力也存在显著差异。
语法:约束采样
少镜头学习有一个很大的缺点:我们不能明确地阻止某些输出的产生。虽然我 们指导了模型并给出了说明,但它可能仍然不能完全遵循它。
相反,软件包已经迅速开发出来来约束和验证生成模型的输出,如引导、护栏和LMQL。在一定程度上,它们利用生成模型来验证自己的输出,如图6-19所示。生成模型作为新的提示来检索输出,并试图基于一些预定义的护栏来验证它。
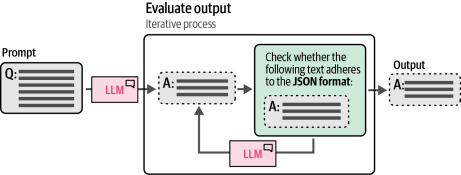
图6-19. 使用LLM检查输出是否符合规则要求
同样,如图6-20所示,由于我们已知输出结果应遵循的结构,因此可以利用该验证过程来控制输出格式,通过自行生成其中部分格式内容
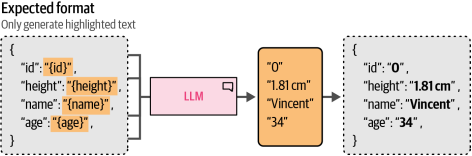
图6-20. 使用大语言模型仅生成我们事先不知道的信息片段
这一流程还可以更进一步——我们不仅可以在输出完成后进行验证,还可在词元采样过程中实施验证。具体而言,在生成词元时,我们可以为LLM设定需要遵循的语法规则或内容规范。例如,当要求模型执行情感分类任务时(应返回"positive/积极"、"negative/消极"或"neutral/中性"),模型仍有可能生成其他意外答案。如图6-21所示,通过对采样过程施加约束条件,我们可以确保LLM仅输出符合预期的目标内容。需要注意的是,这种方法仍会受到top_p和temperature等生成参数的影响。
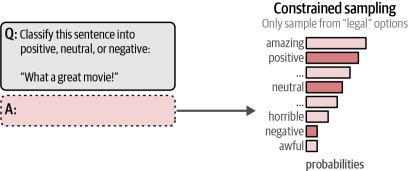
图6-21. 将词元选择限制为仅包含以下三个可能选项:"积极"、"中立"和"消极"
我们可以通过 llama-cpp-python 库来说明这种现象——这是一个类似于 Transformers 的库,可用于加载语言模型。它通常用于通过量化技术(见第12章)高效加载和使用压缩模型,但我们也可以用它来应用 JSON 语法结构。
我们加载了本章一直使用的同一模型,但改用了另一种格式:GGUF。llama-cpp-python 原生支持这种格式,该格式通常用于压缩(量化)模型。
由于我们正在加载新模型,建议重启笔记本。这将清除之前的所有模型并清空显存。您也可以运行以下命令来清空显存:
import gc
import torch
del model, tokenizer, pipe
# Flush memory
gc.collect()
torch.cuda.empty_cache()现在我们已经清空了内存,可以加载Phi-3模型。将n_gpu_layers设为-1表示希望模型的所有层都在GPU上运行。n_ctx指模型的上下文大小,repo_id和filename指向模型所在的Hugging Face仓库:
from llama_cpp.llama import Llama
# Load Phi-3
llm = Llama.from_pretrained(
repo_id="microsoft/Phi-3-mini-4k-instruct-gguf",
filename="*fp16.gguf",
n_gpu_layers=-1,
n_ctx=2048,
verbose=False
)要使用内置的JSON语法生成输出,只需将response_format指定为JSON对象。系统会自动应用JSON语法确保输出符合该格式。
例如,我们可以要求模型创建一个用于《龙与地下城》会话的JSON格式RPG角色:
# Generate output
output = llm.create_chat_completion(
messages=[
{"role": "user", "content": "Create a warrior for an RPG in JSON for mat."},
],
response_format={"type": "json_object"},
temperature=0,
)['choices'][0]['message']["content"]要验证输出是否确实是有效的JSON,可以尝试按JSON格式解析:
import json
# Format as json
json_output = json.dumps(json.loads(output), indent=4)
print(json_output)"name": "Eldrin Stormbringer",
"class": "Warrior",
"level": 10,
"attributes": {
"strength": 18,
"dexterity": 12,
"constitution": 16,
"intelligence": 9,
"wisdom": 14,
"charisma": 10
},
"skills": {
"melee_combat": {
"weapon_mastery": 20,
"armor_class": 18,
"hit_points": 35
},
"defense": {
"shield_skill": 17,
"block_chance": 90
},
"endurance": {
"health_regeneration": 2,
"stamina": 30
}
},
"equipment": [
{
"name": "Ironclad Armor",
"type": "Armor",
"defense_bonus": 15
},
{
"name": "Steel Greatsword",
"type": "Weapon",
"damage": 8,
"critical_chance": 20
}
],
"background": "Eldrin grew up in a small village on the outskirts of a
war-torn land. Witnessing the brutality and suffering caused by conflict, he
dedicated his life to becoming a formidable warrior who could protect those
unable to defend themselves."
}
输出被正确地格式化为JSON。这使我们能够在我们期望输出遵循某些格式的应 用程序中更自信地使用生成模型。
{
"name": "Eldrin Stormbringer",
"class": "Warrior",
"level": 10,
"attributes": {
"strength": 18,
"dexterity": 12,
"constitution": 16,
"intelligence": 9,
"wisdom": 14,
"charisma": 10
},
"skills": {
"melee_combat": {
"weapon_mastery": 20,
"armor_class": 18,
"hit_points": 35
},
"defense": {
"shield_skill": 17,
"block_chance": 90
},
"endurance": {
"health_regeneration": 2,
"stamina": 30
}
},
"equipment": [
{
"name": "Ironclad Armor",
"type": "Armor",
"defense_bonus": 15
},
{
"name": "Steel Greatsword",
"type": "Weapon",
"damage": 8,
"critical_chance": 20
}
],
"background": "Eldrin grew up in a small village on the outskirts of a war-torn land. Witnessing the brutality and suffering caused by conflict, he dedicated his life to becoming a formidable warrior who could protect those unable to defend themselves."
}
输出被正确格式化为JSON。这使得我们能够在期望输出遵循特定格式的应用场景中,更有信心地使用生成模型。
总结
在本章中,我们通过提示工程和输出验证探讨了使用生成模型的基础知识。我们重点关注了提示工程所蕴含的创造性与潜在复杂性。提示的各个组成部分对于生成和优化适用于不同场景的输出内容至关重要。
我们进一步研究了上下文学习(in-context learning)和思维链(chain-of-thought)等高级提示工程技术。这些方法通过提供示例或引导性语句,指导生成模型通过逐步推理解决复杂问题,从而模拟人类思维过程。
总体而言,本章表明提示工程是与大语言模型(LLMs)协作的核心要素,它使我们能够有效地向模型传达需求与偏好。通过掌握提示工程技术,我们可以释放大语言模型的潜力,生成符合要求的高质量响应。
下一章将在这些概念基础上,深入探索利用生成模型的进阶技术。我们将超越提示工程的范畴,研究大语言模型如何结合外部记忆与工具实现更强大的功能。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









