







Nerf: 可用于多视角生成的场景表示
一、初代Nerf
《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》一文提出了一种基于光照模型隐式场表示的场景表示方法Nerf,用于生成一个场景的不同视角。
Nerf作为一种场表示,其输入是三维空间某个顶点的三维坐标以及视角方向
,是一个5D的向量。其输出为该位置发射的光线颜色
以及该点的体密度
。该隐式场的函数表示为
。考虑到空间中点的体密度应该独立于视角方向,
首先将输入的三维坐标x经过8层(Relu,256通道)的全连接层编码为体密度
和256D的隐向量。该隐向量随后与输入的视角拼接并经过一层(Relu,128通道)的全连接层回归出取决于视角信息的RGB颜色值c。
体密度表示光线到达此处后终止的概率,因此对于某个视角o发出的方向为d的光线,其在t时刻到达点
,那么沿这个方向对颜色积分,获得最终的颜色值为:
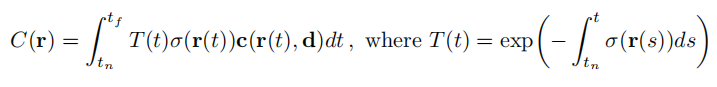
实际渲染方式为,将光线在最近最远距离上等距分割为N个部分,在每部分中均匀采样出一个点,获得N个点,对于N个点进行离散的积分近似。公式如下:
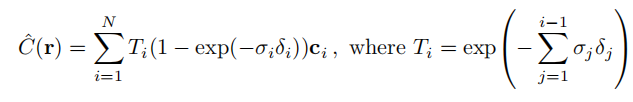
以上便是Nerf的核心部分,但是作者通过训练发现这样的深度模型并不能达到state-of-the-art的效果,接着给出了两个改进方式。
- 位置编码
作者根据了Rahaman等人在ICML 2018上的《On the spectral bias of neural networks. In: ICML (2018) 》工作给出的结论:深度网络更偏向于学习空间中的低频信号。如果对于跳变剧烈的信号,仅仅使用坐标表示作为输入的深度网络是难以拟合的。因此作者将坐标表示通过高频函数映射到了更高维空间中,具体方式是通过多周期的正余弦函数将坐标和方向映射到更高维空间中: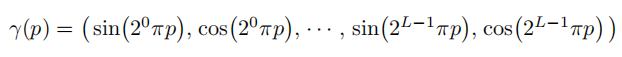
其中对于坐标L取10,对于方向L取4. - 层级体采样
对于每条光线统一的采用均匀的N个样本点采样有时会造成浪费。因为不同区域对于最终的颜色输出具有不同的贡献,应该着重于采样那些更具贡献的区间。将C用新的形式表示: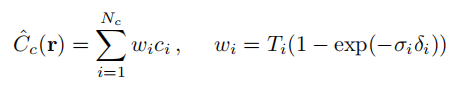
便可以获得每个点对应的贡献权重。作者同时训练两个网络,一个用于粗渲染,另一个用于精细渲染。后者利用前者获得的样本点贡献值权重进行重新加权采样,能够更为关注贡献值较大的区域,达到更为精确的渲染结果。
最终Loss定义为两个网络的Loss之和:
最终作者给出的结果还是非常炫酷的:

二、Nerf++
- 分析了Nerf内在的形状-光线模糊性,并解释了Nerf如何克服这种模糊性的。
- 解决了初代Nerf存在的远距离背景的参数化困难,让Nerf可以更好的对Unbounded的场景进行建模。
第一点,Nerf确实存在这形状-光线的歧义性,或者说是模糊性。对于在一个场景数据下训练好的Nerf表示,其空间的几何表示可能是错误的,但仍然可以在训练样本上渲染出正确的结果。作者通过一个实验证明了这一点。固定几何为一个单位半球,在训练样本上得到了接近GT的结果,但其在测试样本上惨不忍睹。

作者认为有两点因素让Nerf避免受这样的歧义性干扰,一点是如果和正确的几何形状偏差较大,那么c的建模必然是关于方向d的高频信号。对于正确的几何建模,c的建模会是平滑的。受限于MLP的有限回归能力,
与正确几何偏差较大的表示对应的c是难以训练出来的。另一点因素是方向d参数在靠后的层数才被输入,这更加限制了利用该信息拟合高频信号的能力,再加上考虑对于d的正余弦编码到高维空间的空间维度2L的L参数,方向d的L值为4,相比于x的10小,也限制了其表达能力。因此最终训练得到的隐式场反映的会是正确的几何。
第二点,作者分析了Nerf在建模室外场景时遇到的困难。对于远景,如果不对其进行建模,则会造成背景误差,如果对其建模,由于尺度问题会造成前景的分辨率下降。为了克服这个困难,作者对前后景分别进行建模。前景被约束在一个单位半球中,后景在半球之外。半球内部的Nerf积分方式与之前相同,对于半球之外的颜色积分,采用作为积分变量。整体的公式可以写为如下形式:
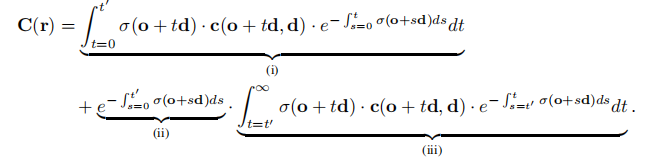
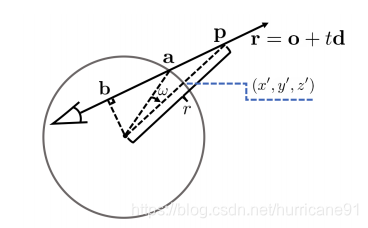
最终作者给出了相较于Nerf对前后景更为精准的建模。

三、Nerf in the Wild
《NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections》这篇文章对Nerf进行了另一种补充改进。考虑到Nerf建模对象是静态环境,每张图片描述的场景具备同样的几何内容,光照条件,因此它无法胜任在不同光照条件和场景内容有区别的场景建模。
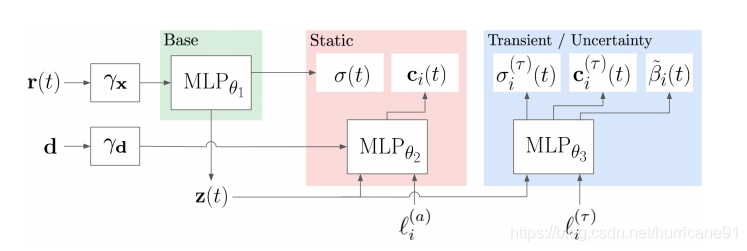
如上图所示,作者将每张图片的Appearance和Transient都预先编码成两个固定向量。这两个向量作为条件决定了静态场景颜色和瞬变物体颜色以及不确定度。值得注意的是这套方法仅仅用在fine Nerf上,对于coarse Nerf,其配置与初代Nerf保持一致。
Nerf in the Wild 在动态场景和变换光照的数据上能够取得不错的效果。

四、Neural Sparse Voxel Fields
《Neural Sparse Voxel Fields》使用了稀疏体素结合Nerf隐式场的方式对场景进行建模。对于空间中某个点关于某个方向的颜色输出和不透明度,是通过其所在的voxel的八个顶点的特征,通过插值和编码,再由共享参数的函数F进行计算得到。

自剪枝:NSVF通过阈值控制一个体素被剪枝。如果八个顶点的occupacy都小于某个阈值,那么该体素被去除。剪枝后的模型可以用于下一轮细化训练。如下图所示:
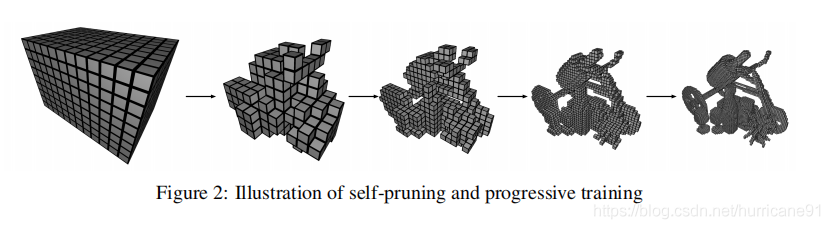
体素的初始化可以通过扫描点云或者凸包来进行粗略的估计。
五、Neural Scene Flow Fields for Space-Time View Synthesis of Dynamic Scenes
这篇文章利用Nerf建模了动态场景。模型输入包含坐标、方向、时间,输出包含了空间密度,反射颜色,时域双向流,以及遮挡权重。公式如下形式:
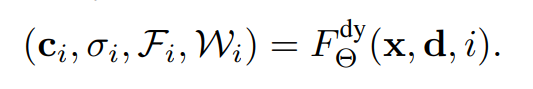
为了训练这样的模型,作者给出了多种优化约束。
空域光度一致性:i时刻通过光线ri积分计算得到的像素点颜色,要与该光线经过流动之后,在新的坐标位置下,在j时刻积分计算得到的像素点颜色相同。该约束旨在让i时刻的nerf和j时刻的nerf分别在ri光线和经过流变换的ri曲光线上的积分得到相同的颜色值。但是这点约束存在一个问题,就是经过时间变换之后,由于流变换,物质表面法向量也变换,相同方向射入的光线不一定能够接收到相同的颜色值,因此积分结果不一定相同。该约束形式如下:
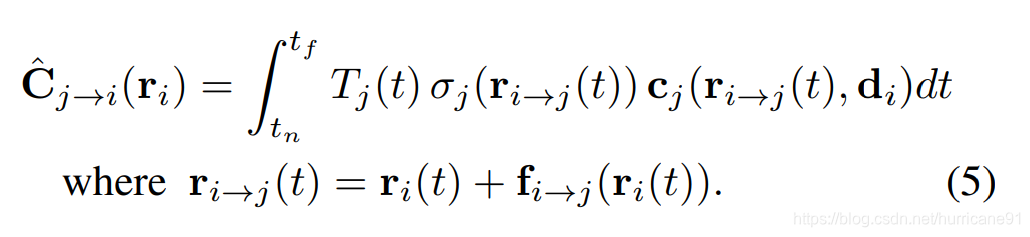
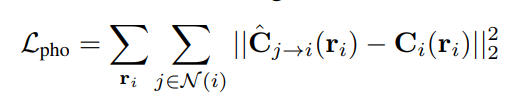
注意到使用的方向仍然是di,说明该约束默认动态flow仅仅是空间中的平移变换,默认约束位置对应的ci和cj在相同的方向有着相同的输出。
考虑到在i时刻未被遮挡的光线ri在j时刻被前景遮挡,那么上述约束就不合理了,因为经过流变换后的颜色不是j时刻该有的颜色,而是新的前景颜色,此时不应该约束j时刻的nerf去恢复背景色,而应鼓励其产生前景色。因此文中使用了一个遮挡权重作为遮挡区域的置信度,通过L1约束其零点稀疏,几乎处处为1,为1只在边缘遮挡区域起效。公式如下:

场景流先验:对于i到j和j到i时刻的场景流,通过循环一致性进行了约束,在出去遮挡发生的区域,两者应该是逆向的。
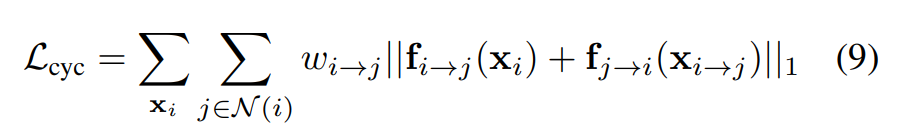
数据驱动先验:上述约束训练动态场景重建模型实在是太难了,很容易陷入局部最优,因此作者利用了数据驱动的方法来辅助模型训练。作者的手段包括两点:几何约束和深度约束。几何约束是将场景流映射到像素坐标上得到光流,再用训练好的光流网络进行光流L1约束。深度约束则是将场景的深度期望和深度网络预测的深度值进行L1约束。
文中对于场景的建模是结合了动态场和静态场的,因此最终的形式和loss为:

六、INerf: Inverting Neural Radiance Fields for Pose Estimation
有了一个训练好的nerf之后,我们注意到颜色积分公式是对坐标可导的。坐标又可以对相机参数进行求导,因此便可以使用nerf渲染得到的图片和目标图片的loss对相机参数进行梯度优化来进行相机姿态估计。
INerf一文中使用了Rodrigues Formula对相机姿态矩阵参数化表示,具体形式如下:
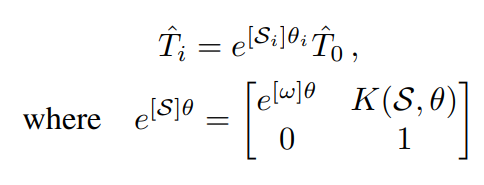
w是旋转轴,theta是旋转角度。该仿射变换矩阵定义了相机姿态。
为了更有效的进行相机姿态优化,图像采样尤为重要。由于直接采样整张图片的内存开销太大,作者采用了ROI采样,对于感兴趣部位的区域进行采样优化。
七、NeRV: Neural Reflectance and Visibility Fields for Relighting and View Synthesis
在看到这篇文章之前也有过仿真反射折射来对nerf进行改进的想法,但是这篇文章已经把反射做掉了。
这篇文章只考虑直接反射和one bounce反射,多次的反射并不考虑。考虑反射模型,就要对空间的反射参数进行估计。改写Nerf的公式为:
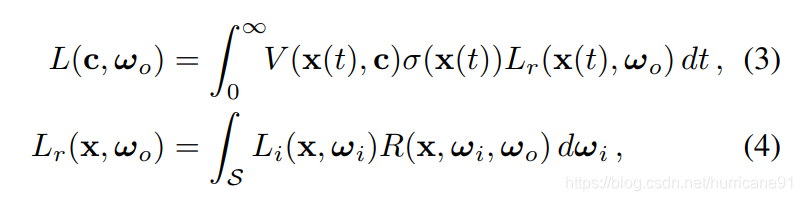
公式中的R是和材质纹理有关的反射参数,Li是入射光线。公式4对于半球角度进行积分累加。文中并不对光源到当前位置发射光线的衰减利用空间密度场σ进行积分计算,而是使用一个额外网络V进行估计。综合直接反射和one bounce反射,最终的颜色公式为:
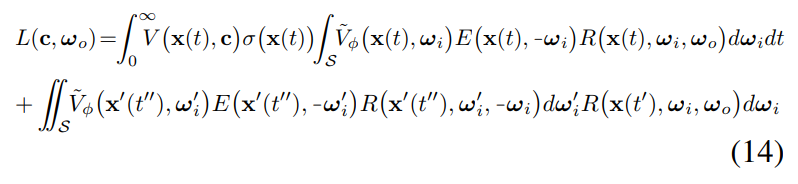
V表示从点到光源之间的衰减系数,与场景几何相关。E表示光源入射到该点的光度值。其中t',也就是one bounce发生的位置,是用一个单独的网络D进行估计的,t'=D(x(t), -wi)预测了期望深度。为了保持D和V与建模的几何σ一致,Loss中除了重建loss还包括D和V的约束:
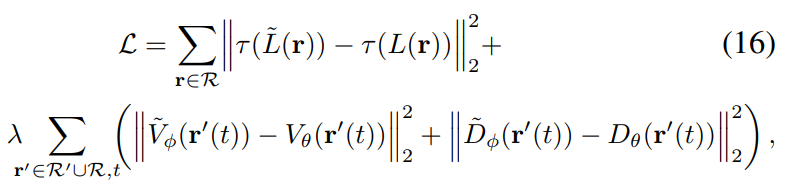
最终的效果为,可以通过调整E来重新设定光源。

八、Deformable Neural Radiance Fields
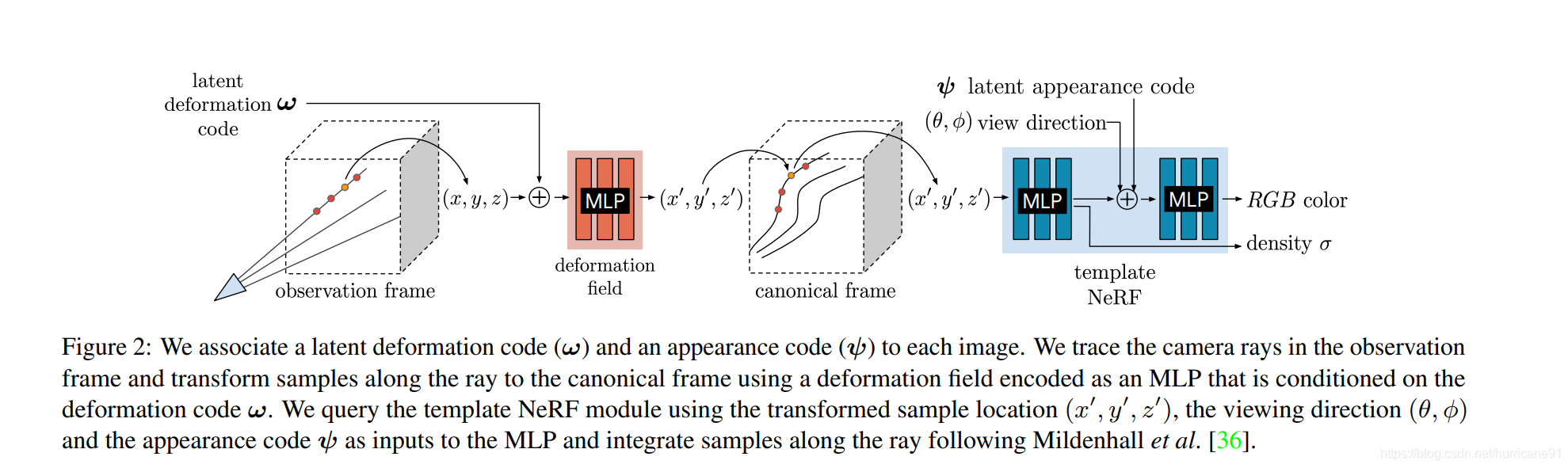
DNerf建模了场景内容的变形,但其目的不是为了提供多视角的动态图,而是为了对场景内容发生微小扰动更鲁棒。方法针对的是人的自拍图像,通过前后景分割,获得多张无背景的自拍人像。背景的信息用于相机标定,估计相机姿态参数和内参。在光线追踪过程中,为每一帧事先编码好变形特征,利用特征估计每个点的形变位移,通过位移获取标准空间中的位置,来估计颜色和密度。同样为每一帧准备了外观特征向量,用于处理各帧之间的差异性。Loss中除了重建误差还包括变形的弹性正则项,防止过拟合。类似于Nerf,该方法对空间坐标进行了三角函数编码,转换为更高维的向量。但空间编码在训练过程中被设定为从低频到高频的coarse2fine过程,在防止过拟合的同时不断增加清晰度。















 2633
2633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









