









内容主要来源于机器学习实战这本书,加上自己的理解。
1.KNN算法的简单描述
K最近邻(k-Nearest Neighbor,KNN)分类算法可以说是最简单的机器学习算法了。它采用测量不同特征值之间的距离方法进行分类。它的思想很简单:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。下图是大家引用的一个最经典示例图。
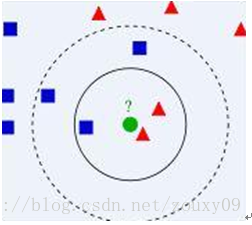
比如上面这个图,我们有两类数据,分别是蓝色方块和红色三角形,他们分布在一个上图的二维中间中。那么假如我们有一个绿色圆圈这个数据,需要判断这个数据是属于蓝色方块这一类,还是与红色三角形同类。怎么做呢?我们先把离这个绿色圆圈最近的几个点找到,因为我们觉得离绿色圆圈最近的才对它的类别有判断的帮助。那到底要用多少个来判断呢?这个个数就是k了。如果k=3,就表示我们选择离绿色圆圈最近的3个点来判断,由于红色三角形所占比例为2/3,所以我们认为绿色圆是和红色三角形同类。如果k=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。从这里可以看到,k的值选取很重要的。
KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
该算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。因此可以采用权值的方法(和该样本距离小的邻居权值大)来改进。该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。目前常用的解决方法是事先对已知样本点进行剪辑,事先去除对分类作用不大的样本。该算法比较适用于样本容量比较大的类域的自动分类,而那些样本容量较小的类域采用这种算法比较容易产生误分。
总的来说就是我们已经存在了一个带标签的数据比对库,然后输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似(最近邻)的分类标签。一般来说,只选择样本数据库中前k个最相似的数据。最后,选择k个最相似数据中出现次数最多的分类。其算法描述如下:
1)计算已知类别数据集中的点与当前点之间的距离;
2)按照距离递增次序排序;
3)选取与当前点距离最小的k个点;
4)确定前k个点所在类别的出现频率;
5)返回前k个点出现频率最高的类别作为当前点的预测分类。
二:python程序部分
2.1 python导入数据
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
创建了数据集和标签。
根据上面说到的算法描述中五个步骤K-近邻算法核心部分程序:
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet # tile :construct array by repeating inX dataSetSize times
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5 # get distance
sortedDistIndicies = distances.argsort() # return ordered array's index
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
不知道是不是编码设置问题,注释没法写成中文,只能是英文。
K-近邻算法书上应用到了改进约会网站的配对效果上面具体流程:
准备数据部分:从文本文件中解析数据,文本中说到3种特征:飞行里程、玩游戏时间、消费冰淇淋数量。我不知道作者为什么选择这三种特征,好像跟约会配对没什么毛关系。
这部分用到很多numpy中处理矩阵的函数。
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip() # delete character like tab or backspace
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3] # get 3 features
classLabelVector.append(int(listFromLine[-1])) # get classify result
index += 1
return returnMat,classLabelVector处理数据中涉及到数据值的归一化。意思就是说上面约会配对有三个特征,但是会发现飞行距离这个数值远远大于其它两个,为了体现3个特征相同的影响力,对数据进行归一化。
def autoNorm(dataSet):
minVals = dataSet.min(0) # select least value in column
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
另外一个应用是在手写识别系统。类似于前面约会网站应用,准备数据时需要进行图像到向量转换,然后调用K-近邻的核心算法实现。
下面是所有的代码综合和测试代码:主函数里添加了一些matplotlib画图测试代码
'''
kNN: k Nearest Neighbors
Input: inX: vector to compare to existing dataset (1xN)
dataSet: size m data set of known vectors (NxM)
labels: data set labels (1xM vector)
k: number of neighbors to use for comparison (should be an odd number)
Output: the most popular class label
'''
from numpy import *
import operator
from os import listdir
import matplotlib
import matplotlib.pyplot as plt
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet # tile :construct array by repeating inX dataSetSize times
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5 # get distance
sortedDistIndicies = distances.argsort() # return ordered array's index
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createDataSet():
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group, labels
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip() # delete character like tab or backspace
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3] # get 3 features
classLabelVector.append(int(listFromLine[-1])) # get classify result
index += 1
return returnMat,classLabelVector
def autoNorm(dataSet):
minVals = dataSet.min(0) # select least value in column
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def datingClassTest():
hoRatio = 0.50 #hold out 10%
datingDataMat,datingLabels = file2matrix('E:\PythonMachine Learning in Action\datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
print m
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
def classifyperson():
resultList = ['not at all','in small doses','in large doses']
percentTats = float(raw_input('percentage time spent on games ?'))
ffmiles = float(raw_input('frequent flier miles per year?'))
iceCream = float(raw_input('liters of ice cream consumed each year?'))
datingDataMat,datingLabels = file2matrix('E:\PythonMachine Learning in Action\datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr = array([ffmiles,percentTats,iceCream])
classifierResult = classify0((inArr-minVals)/ranges,normMat,datingLabels,3)
print "your probably like this person :" ,\
resultList[classifierResult-1]
def img2vector(filename):
returnVect = zeros((1,1024))
fr = open(filename)
for i in range(32):
lineStr = fr.readline()
for j in range(32):
returnVect[0,32*i+j] = int(lineStr[j])
return returnVect
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('E:/PythonMachine Learning in Action/trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('E:/PythonMachine Learning in Action/trainingDigits/%s' % fileNameStr)
testFileList = listdir('E:/PythonMachine Learning in Action/testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('E:/PythonMachine Learning in Action/testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)
if (classifierResult != classNumStr): errorCount += 1.0
print "\nthe total number of errors is: %d" % errorCount
print "\nthe total error rate is: %f" % (errorCount/float(mTest))
if __name__=='__main__':
#classifyperson()
datingClassTest()
dataSet, labels = createDataSet()
testX = array([1.2, 1.0])
k = 3
outputLabel = classify0(testX, dataSet, labels, 3)
print "Your input is:", testX, "and classified to class: ", outputLabel
testX = array([0.1, 0.3])
outputLabel = classify0(testX, dataSet, labels, 3)
print "Your input is:", testX, "and classified to class: ", outputLabel
handwritingClassTest()
datingDataMat,datingLabels = file2matrix('E:\PythonMachine Learning in Action\datingTestSet2.txt')
print datingDataMat
print datingLabels[0:20]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
plt.show()
这里要注意:
trainingFileList = listdir('E:/PythonMachine Learning in Action/trainingDigits') 调用这个函数时路径写法,如果不想复杂指定路径简单就把文件夹和knn.py文件放在一起。















 3663
3663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









