






1. 导库
import pandas as pd
2. 读取数据
euro12 = pd.read_csv(r'C:\pandas\pandas_exercise\exercise_data\Euro2012_stats.csv')
3. 只选取Goals这一列
euro12.Goals
# 或者 euro12['Goals']
结果:

4. 参与了2012欧洲杯的球队数
euro12.shape[0] # 16
# 或者 euro12.Team.nunique()
# 或者euro12['Team'].nunique()
5. 该数据集中一共有多少列
euro12.info()
# 或者 euro12.shape[1]
结果:

6. 将数据集中的列Team, Yellow Cards和Red Cards单独存为一个名叫discipline的数据框
discipline = euro12[['Team','Yellow Cards','Red Cards']]
print(discipline)
结果:

7. 对数据框discipline按照先Red Cards再Yellow Cards进行排序
discipline.sort_values(['Red Cards','Yellow Cards'],ascending = False)
结果:

sort_values()函数使用方法:
DataFrame.sort_values(by=‘##’,axis=0,ascending=True, inplace=False, na_position=‘last’)
'by’是指定列名
'axis’为0是指按指定列中数据大小排列
ascending为True是指按升序排序,为False是指按降序排序
inplace是指替代原数据
na_position是指缺失值的显示位置
8. 计算每个球队拿到的黄牌数的平均值
round(discipline['Yellow Cards'].mean()) # 7
9. 找到进球数Goals超过6的球队数据
euro12[euro12.Goals > 6]
结果:

这属于pandas的DataFrame的布尔类型数据处理操作,是用来选择非索引列的值。
10.选取以字母G开头的球队数据
euro12[euro12.Team.str.startswith('G')]
结果:

startswith()函数是判断字符串是否以指定字符或字符串开头。
使用方法:Pandas.Series.str.startswith(self, pat, na=nan)
参数pat是指字符串;na为True是指object中没有字符串的话就不显示,反之为False
参考https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Series.str.startswith.html
返回值:布尔类型值
此处代码本质上等同于9处的代码
11. 选择前七列
euro12.iloc[:,0:7]
结果:

12. 找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)
euro12.loc[euro12.Team.isin(['England','Italy','Russia']),['Team','Shooting Accuracy']]
结果:
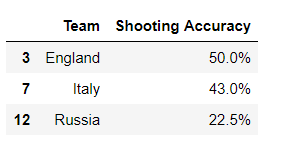
isin函数是判断该列中的元素是否在指定的列表中
isin函数返回值同样是布尔类型值
详情可参考:https://blog.csdn.net/lzw2016/article/details/80472649
区分iloc和loc的用法:
共同点:
iloc和loc都是用来对DataFrame数据进行切片处理
不同点:
iloc是用索引值定位处理
loc是用column名和index名定位处理















 1808
1808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









