






一、实验目的
1.理解python语言中pandas库的各函数作用;
2.掌握pandas库中常用函数,能够用其解决实际问题;
二、实验内容
用pandas库中函数完成对数据过滤与排序的操作,内容包括但不限于:
(1)读取数据(2012欧洲杯数据)
(2)打印数据集完整摘要
(3)任选3不同列存入一个dataframe数据类型中并输出
(4)分别求出每个球队拿到的红牌数、黄牌数的平均值
(5)找到进球数Goals超过6个的球队数据
(6)选取展示前n列数据
(7)选取以字母G开头的球队数据
(8)选取展示除了最后3列之外的全部列数据
(9)找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)
(10)求所有球队的进球总数(Goals)和失球总数(Goals conceded)
(11)对球队的进球数进行排序
可能会用到的pandas库中的数据结构及函数:dataframe、read_csv、head、series.str.startswith、iloc、isin、sum、sort_values
根据课堂上对该问题的描述和分析,自行完成程序设计并实现,要求算法描述准确且程序运行正确。
三、设计与实现
详细描述设计过程、关键问题的实现方法及算法的分析说明。
1、读取数据,通过read_csv读取2012年欧洲杯csv文件;
2、打印数据,通过head打印数据集前五行内容,通过info打印DataFrame的简单摘要,显示有关DataFrame的信息,包括索引的数据类型dtype和列的数据类型dtype,非空值的数量和内存使用情况;
3、通过DataFrame构建一个表格型的数据结构,这里选取数据集中的’Team’, ‘Shots on target’, ‘Shots off target’三列;
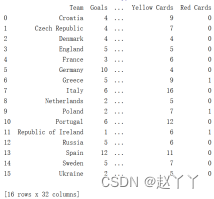
4、将数据集中的列Team,Yellow Cards和Red Cards拿出来,单独存为一个名叫discipline的数据框,通过sort_values对数据框discipline按照先Red Cards再Yellow Cards的原则从大到小进行排序,ascending表示是否升序排序,默认为true,降序则为false,再利用mean对Yellow Cards,Red Cards两列求平均值,round表示四舍五入,没有参数时表示取整;
5、先找出数据集中进球数Goals大于6的数据,满足条件时返回True,不满足条件时返回False,在打印满足条件的球队数据;
6、iloc索引器用于按位置进行基于整数位置的索引或者选择。可以选择多行多列,iloc[:,0:3]表示选取所有行,前三列的数据进行展示;
7、startswitch()用于检测字符串是否以指定字符串开头。如果是则返回True,否则返回False。先找出数据集中的Team的数据,再找出以G开头的球队数据;
8、同理6,iloc[: , :-3]表示选取所有行以及从第一列开始到倒数第四列的所有数据;
9、loc不仅可以输入数字也可以直接输入column的名字,需要注意的是先行后列,isin是series中的一个函数,用于查看某列中是否包含某个字符串,返回值为布尔Series,来表明每一行的情况。这里首先可以通过isin判断Team列中是否包含’England’, ‘Italy’, ‘Russia’三个字符,从而选出这三列作为loc的行,再找出’Team’,'Shooting Accuracy’这两列打印输出,从而可得到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy);
10、找出数据集中Goals和Goals conceded这两列数据,利用sum分别进行求和;
11、利用sort_values进行排序,参数by表示通过Goals进行排序。
四、测试与分析(附测试用例,运行结果截图等)

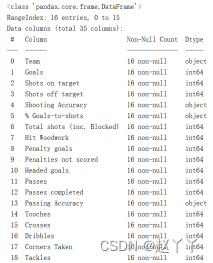

如上图,head()可以看出数据集前五行信息,每行信息有35列。Info()打印DataFrame的简单摘要,显示有关DataFrame的信息,包括索引的数据类型dtype和列的数据类型dtype,非空值的数量和内存使用4.5+KB;
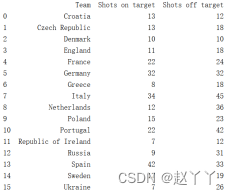
如上图,选取数据集中的’Team’, ‘Shots on target’, 'Shots off target’三列,构建一个DataFrame的数据结构,进行打印。

如上图,黄牌数的平均值为7,红牌数的平均值为0,进球数超过6的队伍有两支Germany和Spain,进球数分别为10和12。
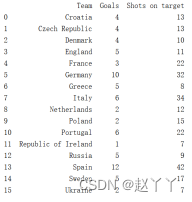
如上图,展示了数据集中前三列的数据和除了最后三列所有列的数据。
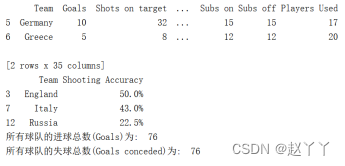
如上图,球队以“G”开头的分别是Germany和Greece;England的射击准确率为50.0%,Itaty的射击准确率为43.0%,Russia的射击准确率为22.5%;所有球队的进球数相加为76,失球数相加为76。
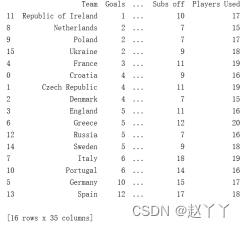
如上图,对进球数按照从小到大的顺序进行排序,最少为Republic of Ireland进一个球,最多为Spain进12个球。
五、设计技巧及体会
1.实验过程中遇到的问题及解决办法;
问题:对函数的应用不熟练;对于iloc和loc函数的区分不清楚,对于代码设计的过程需要大量的思考。
解决办法:对之前学习的知识进行整理回顾,在分析实验要求时,一步一步理清思路,对一些数据分析案例进行学习,从而满足本实验的需求。
2.对设计进行评价(优点与不足);
优点:基本完成实验要求,掌握了pandas中常见的函数,设计过程有条有理,循序渐进,简单明了。
缺点:在完成实验的基础上,应该对其他数据分析的需求进行思考,发现更多的数据规律与应用价值。
3.对设计及调试过程的心得体会;
首先是对于思路的分析,明确目标,需要使用的数据,对数据进行预处理,需要使用的到的函数,了解函数对应的参数,其次,在完成实验要求的基础上,保证代码简洁,适当添加注释进行说明,然后对于Python库的学习不能停留在简单的掌握,课下还需进行深入的自主学习,最后一点,就是多练习多敲代码,只有真正的将学到的知识,应用到实际中,完成数据分析,才能真正掌握。
4.思考对原实验方案的改进,写出改进思路。
可将代码分步完成,虽然繁琐,但是可以直观的看出每个函数返回的数据;应用其他数据集解决实际问题。
六、附源代码
import pandas as pd
# 1、读取数据
euro= pd.read_csv("Euro2012_stats.csv")
# 2、打印数据集完整摘要
print(euro.head()) #前五行信息
print(euro.info()) #数据集标签
# 3、任选3不同列存入一个dataframe数据类型中并输出
neweuro= pd.DataFrame(euro, columns=['Team', 'Shots on target', 'Shots off target'])
print(neweuro)
# 4、分别求出每个球队拿到的红牌数、黄牌数的平均值
discipline=euro[['Team','Yellow Cards','Red Cards']]
discipline.sort_values(['Red Cards', 'Yellow Cards'], ascending = False)
print("黄牌数的平均值",round(discipline['Yellow Cards'].mean()))
print("红牌数的平均值",round(discipline['Red Cards'].mean()))
# 5、找到进球数Goals超过6个的球队数据
print(euro[euro['Goals']>6])
# 6、选取展示前n列数据
print(euro.iloc[:,0:3] )
# 7、选取以字母G开头的球队数据
print(euro[euro.Team.str.startswith('G')])
# 8、选取展示除了最后3列之外的全部列数据
print(euro.iloc[: , :-3])
# 9、找到英格兰(England)、意大利(Italy)和俄罗斯(Russia)的射正率(Shooting Accuracy)
print(euro.loc[euro.Team.isin(['England', 'Italy', 'Russia']), ['Team','Shooting Accuracy']])
# 10、求所有球队的进球总数(Goals)和失球总数(Goals conceded)
print("所有球队的进球总数(Goals)为: ", euro["Goals"].sum())
print("所有球队的失球总数(Goals conceded)为: ", euro["Goals conceded"].sum())
# 11、对球队的进球数进行排序
print(euro.sort_values(by="Goals"))















 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









