







基础算法–KMP
KMP算法是一种改进的字符串匹配算法,可以在
O
(
n
+
m
)
O(n+m)
O(n+m)的时间复杂度内实现两个字符串的匹配,其中
n
n
n和
m
m
m分别为主串和模式串的长度。其算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的
暴力匹配
如果我们暴力对主串AAAAAAB和模式串AAAB进行匹配
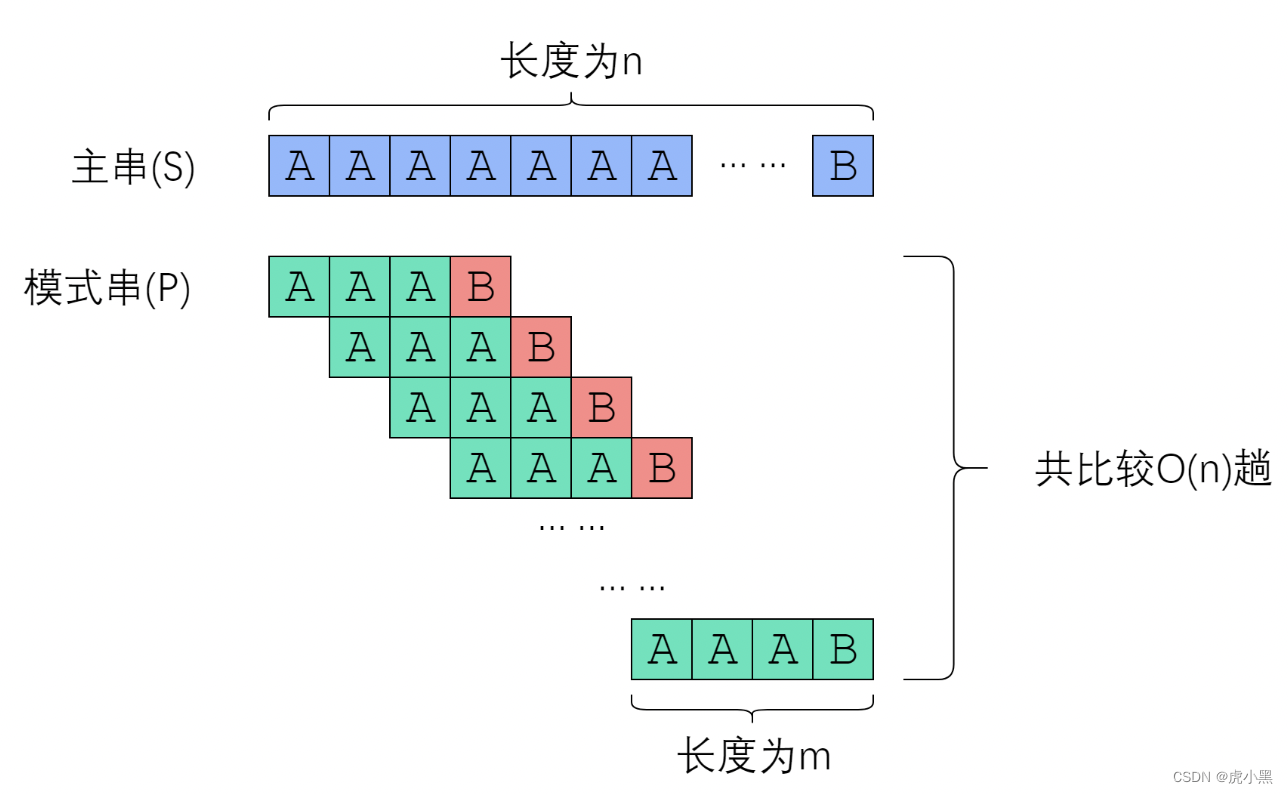
暴力匹配的代码可以如下编写
bool force(std::string &s, std::string &p) {
if (p.size() > s.size()) return false;
for (int i = 0, len = s.size() - p.size() + 1; i < len; ++i) {
bool suc = true;
for (int j = 0; j < p.size(); ++j) {
if (s[i + j] != p[j]) {
suc = false;
break;
}
}
if (suc) return suc;
}
return false;
}
可见暴力接发的时间复杂度是 O ( m ∗ n ) O(m*n) O(m∗n)
KMP
在暴力匹配中,如果从
S
[
i
]
S[i]
S[i]开始的那一趟比较失败了,算法会直接开始尝试从
S
[
i
+
1
]
S[i+1]
S[i+1]开始比较。这种行为,属于没有从之前的错误中学到东西。我们应当注意到,一次失败的匹配,会给我们提供宝贵的信息。
如果在主串
S
S
S中从
i
i
i到
i
+
l
e
n
(
P
)
i+len(P)
i+len(P)与模式串
P
P
P的匹配是在第
r
r
r个位置失败的,那么从
S
[
i
]
S[i]
S[i]开始的
(
r
−
1
)
(r-1)
(r−1)个连续字符,一定与
P
P
P的前
(
r
−
1
)
(r-1)
(r−1)个字符一模一样
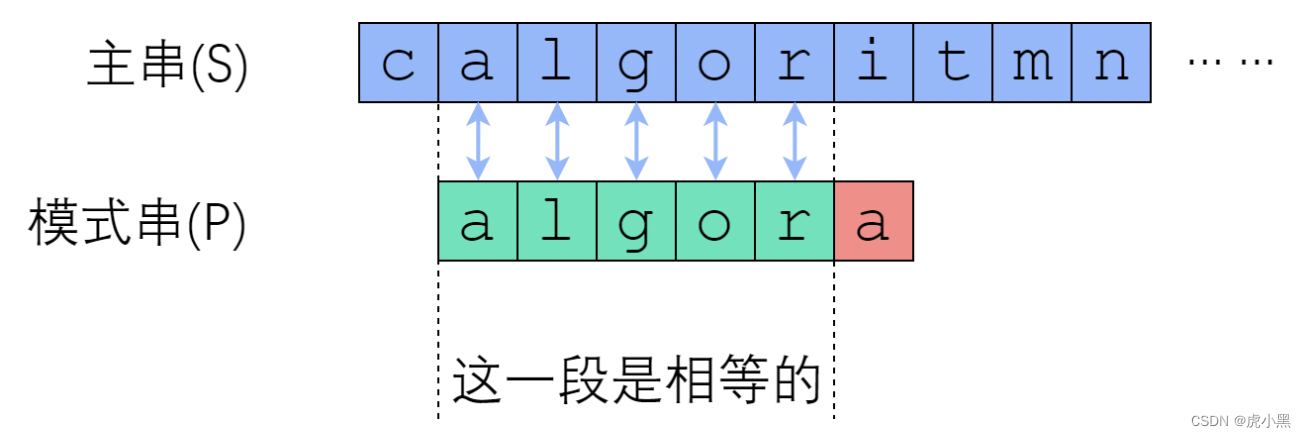
有些趟字符串比较是有可能会成功的,有些则毫无可能。因此我们应该跳过那些毫无可能的趟。我们来看下面一个例子
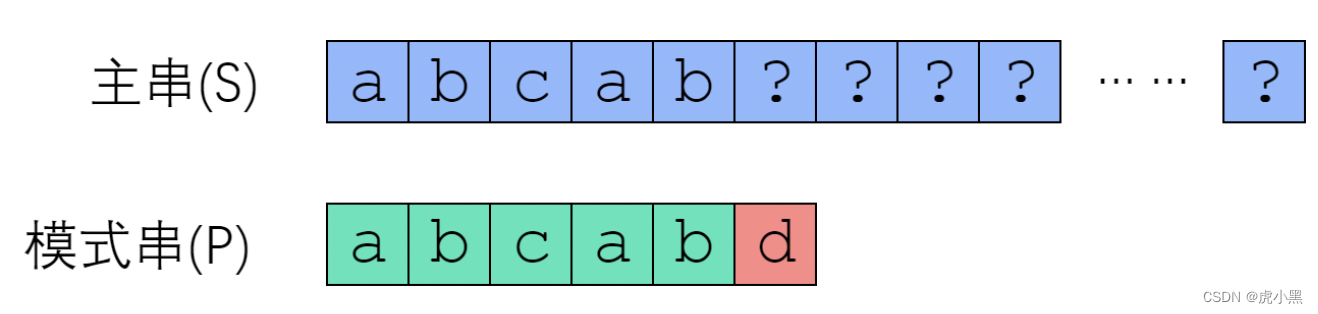
模式串
a
b
c
a
b
d
abcabd
abcabd和主串从
S
[
0
]
S[0]
S[0]开始匹配在
P
[
5
]
P[5]
P[5]处失配。那么说明
S
[
0
]
S[0]
S[0]到
S
[
4
]
S[4]
S[4]等于
P
[
0
]
P[0]
P[0]到
P
[
4
]
P[4]
P[4]。 现在我们来考虑,从
S
[
1
]
S[1]
S[1]、
S
[
2
]
S[2]
S[2]、
S
[
3
]
S[3]
S[3]开始的匹配尝试,有没有可能成功?从
S
[
1
]
S[1]
S[1]开始肯定没办法成功,因为
S
[
1
]
=
P
[
1
]
=
b
S[1] = P[1] = b
S[1]=P[1]=b,和
P
[
0
]
P[0]
P[0]并不相等。从
S
[
2
]
S[2]
S[2]开始也是没戏的,因为
S
[
2
]
=
P
[
2
]
=
c
S[2] = P[2] = c
S[2]=P[2]=c,并不等于
P
[
0
]
P[0]
P[0]. 但是从
S
[
3
]
S[3]
S[3]开始是有可能成功的
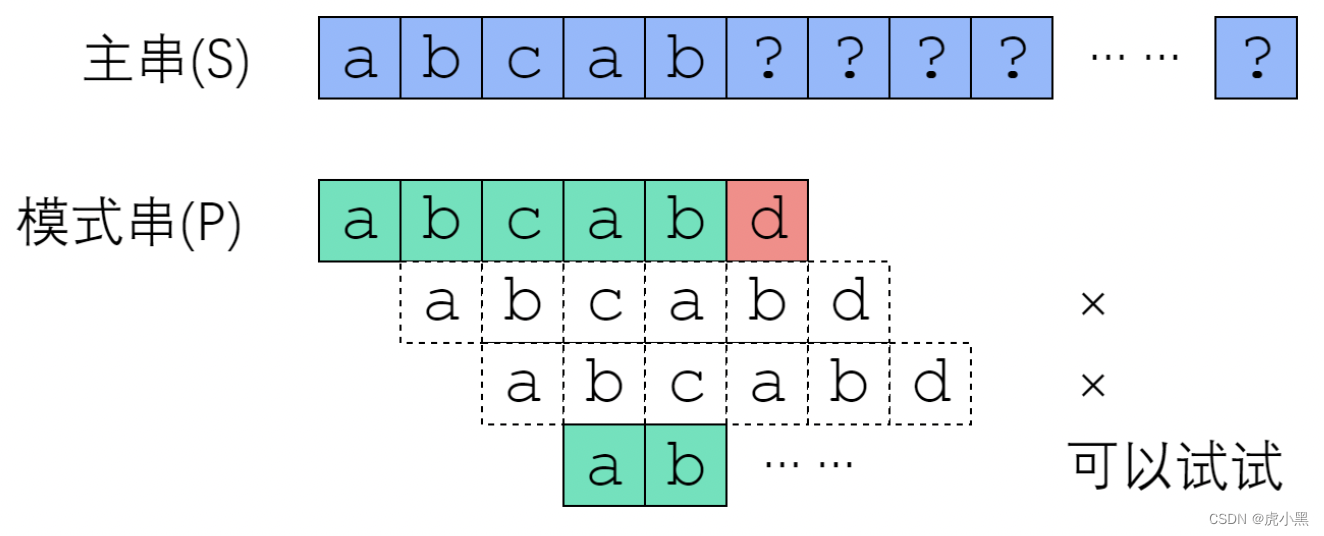
如果我们在发生失配时,我们知道不在回溯主串,而是移动子串。那么我们就能节省很多趟。
next数组
n
e
x
t
next
next数组是对于模式串而言的。
P
P
P的
n
e
x
t
next
next数组定义为:
n
e
x
t
[
i
]
next[i]
next[i] 表示
P
[
0
]
P[0]
P[0]到
P
[
i
]
P[i]
P[i]这一个子串,使得前
k
k
k个字符恰等于后
k
k
k个字符的最大的
k
k
k。特别地,
k
k
k不能取
i
+
1
i+1
i+1(因为这个子串一共才
i
+
1
i+1
i+1个字符,自己肯定与自己相等,就没有意义了)
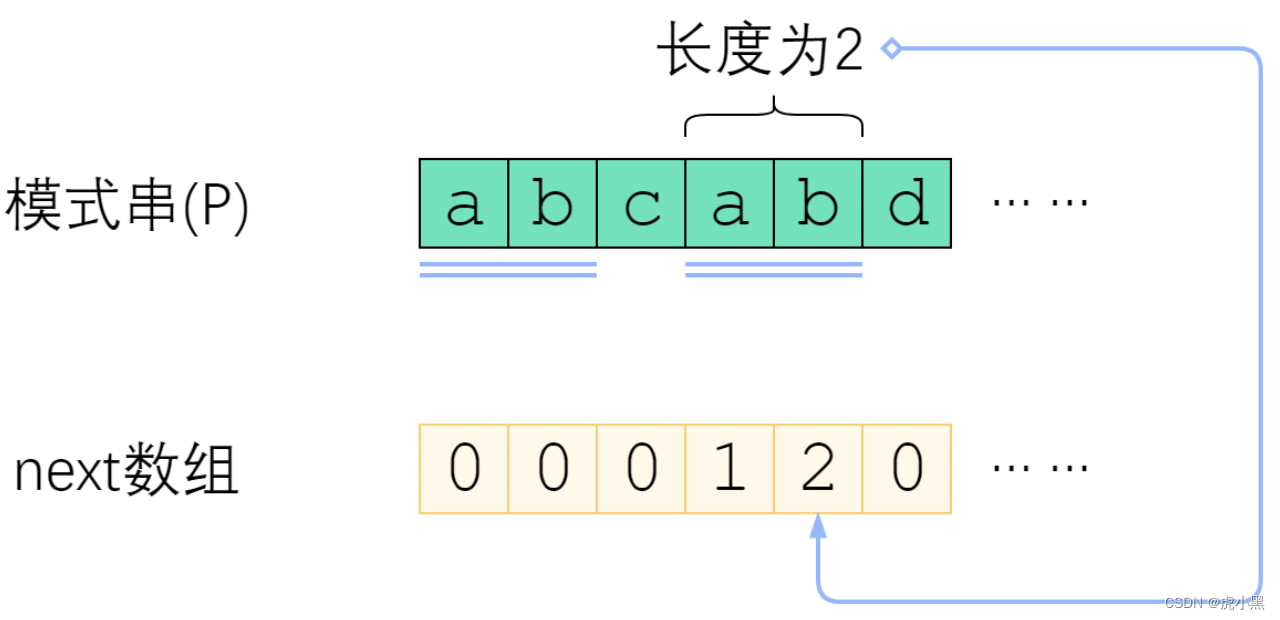
如果把模式串视为一把标尺,在主串上移动,那么暴力就是每次失配之后只右移一位;改进算法则是每次失配之后,移很多位,跳过那些不可能匹配成功的位置。但是该如何确定要移多少位呢
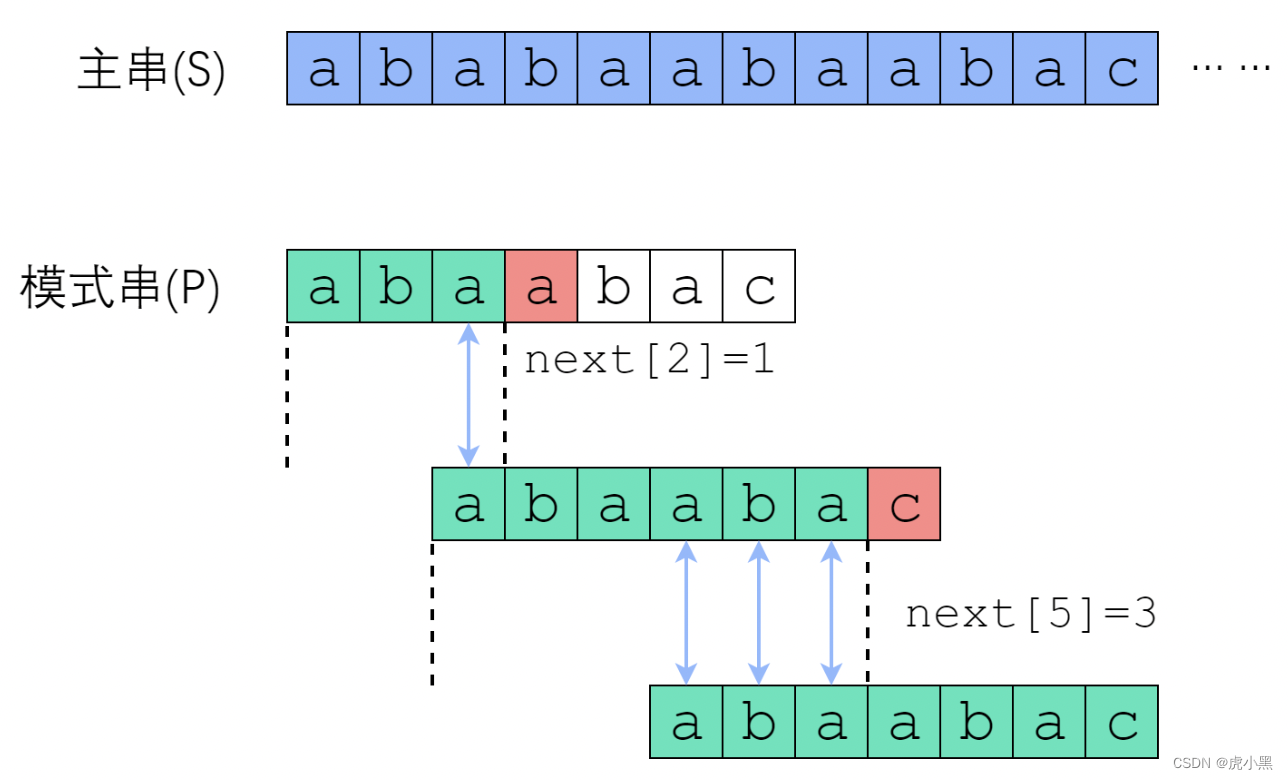
在
S
[
0
]
S[0]
S[0]尝试匹配,失配于
S
[
3
]
≠
P
[
3
]
S[3] \ne P[3]
S[3]=P[3]之后,我们直接把模式串往右移了两位,让
S
[
3
]
S[3]
S[3]对准
P
[
1
]
P[1]
P[1]。接着继续匹配,失配于
S
[
8
]
≠
P
[
6
]
S[8] \ne P[6]
S[8]=P[6], 接下来我们把
P
P
P往右平移了三位,把
S
[
8
]
S[8]
S[8]对准
P
[
3
]
P[3]
P[3]。此后继续匹配直到成功,如果已知这样一个next数组,那么匹配算法就可以如下编写
bool kmp(std::string &s, std::string &p) {
std::vector<int> next = build_next(p);
int i = 0, j = 0;
while (i < s.size()) {
if (s[i] == p[j]) {
++i;
++j;
} else if (j > 0) {
j = next[j - 1];
} else {
++i;
}
if (p.size() == j) return true;
}
return false;
}
不难分析出整个匹配算法的时间复杂度 O ( n + m ) O(n+m) O(n+m)
快速求解next函数
快速构建 n e x t next next数组,是 K M P KMP KMP算法的精髓所在,核心思想是自己与自己做匹配
std::vector<int> build_next(std::string &p) {
std::vector<int> next;
next.push_back(0); // next[0]必然是0
int i = 0;
int j = 1;
while (j < p.size()) {
if (p[i] == p[j]) { // 如果next[i] = next[j] 说明p[0]~p[i]等于p[j-i]~p[j]
++i;
++j;
next.push_back(i);
} else if (i > 0) {
i = next[i - 1];
} else {
next.push_back(0);
++j;
}
}
return next;
}















 370
370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











