







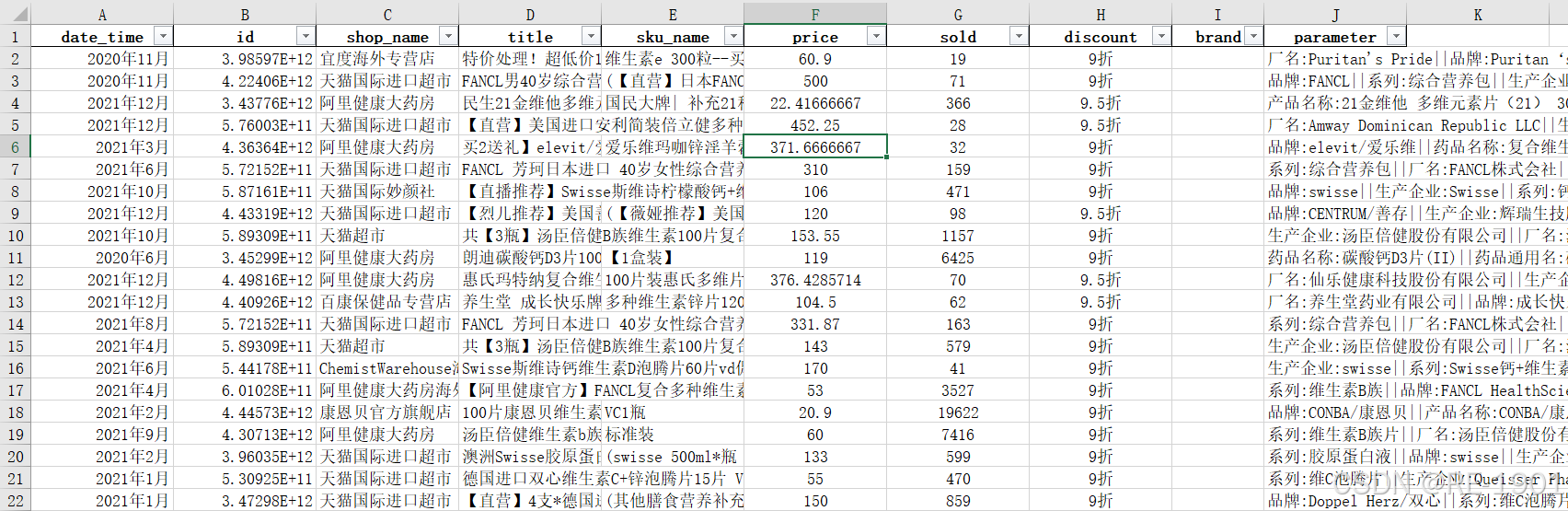
目录
一、前言
在当前这个数据驱动的时代,数据分析已经成为了各个行业决策过程中至关重要的一环。本文是“2022年全国大学生数据分析大赛”的一个比赛题目。虽然时间已经过去一段时间,但这篇文章仍具有学习和分享的价值,可以给那些刚踏入数据分析领域的人提供一个学习和思考的机会项目。
希望这篇文章能对您的学习和工作有所帮助,同时也期待与大家一起交流和探讨!若有错误或不足,希望批评指出和包涵,谢谢!
二、题目和数据
问题背景
随着国家政策的逐步开放,越来越多的药品可以在网络上购买, 医药电商平台蒸蒸日上,受新冠疫情的影响,线下药店购买困难,更 让医药电商进入了更多消费者的视野,各大药企也纷纷加大力度布局 医药电商领域。但电商模式与线下零售有所不同,如何更好的经营医 药电商成为药企急需解决的问题。本题采集了天猫维生素类的药品, 请针对维生素药品进行数据的清洗、分析与挖掘,并回答下列问题。
解决任务
1.对店铺进行分析,一共包含多少家店铺,各店铺的销售额占比如何?给出销售额占比最高的店铺,并分析该店铺的销售情况。
2.对所有药品进行分析,一共包含多少个药品,各药品的销售额占比如何?给出销售额占比最高的10个药品,并绘制这10个药品每月销售额曲线图。
3.对所有药品品牌进行分析,一共包含多少个品牌,各品牌的销售额占比如何?给出销售额占比最高的10个品牌,并分析这10个品牌销售较好的原因?
4.预测天猫维生素类药品未来三个月的销售总额并绘制拟合曲线,评估模型性能和误差。
三、问题分析和解决
# 导入相关的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
plt.rcParams['font.sans-serif']='SimHei' # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 设置公式符号
warnings.filterwarnings('ignore') # 设置忽略警告
# 读取文件
data = pd.read_excel('./医药电商销售分析.xlsx')
df = data.copy()
data# 数据探索(可自行运行,本文不显示输出结果)
print(data.shape) # 数据的行列数
print(data.describe()) # 数据的描述性统计
print(data.info()) # 数据的探索
print(data.index) # 数据的列标
print(data.columns) # 数据的行标# 数据清洗(重复值,缺失值,异常值)
print(data.duplicated().sum()) # 重复值查找 # 输出为0
print(data.isnull().sum()) # 缺失值查找
#此题无需进行异常值查找缺失值输出结果:
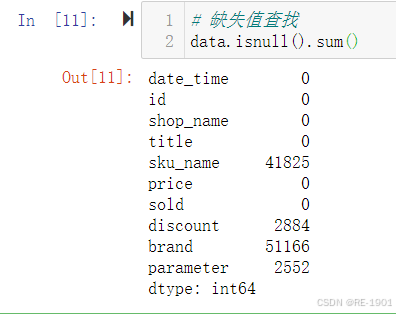
结果分析:
1、发现sku_name、discount、brand、parameter四列指标有缺失值
2、得知discount是折扣,缺失值那些是不打折扣的,即打10折,需要填充
3、brand是品牌,parameter是商品参数(包含生产企业和商品品牌等信息),sku_name指标暂不清楚 (处理根据问题分析)
3.1 问题一 (店铺)
问题:对店铺进行分析,一共包含多少家店铺,各店铺的销售额占比如何?给出销售额占比最高的店铺,并分析该店铺的销售情况。
3.1.1 预处理分析
销售额 = 价格 * 销售量 * 折扣
分析步骤:
1.将discount缺失填充10折
2.将discount列的“折”去掉
3.计算销售额sales
# 缺失值处理
##1.将discount缺失填充10折
df.discount = df.discount.fillna('10折') # discount的缺失值进行填充“10折”
df.discount.value_counts() # 填充后的discount分布情况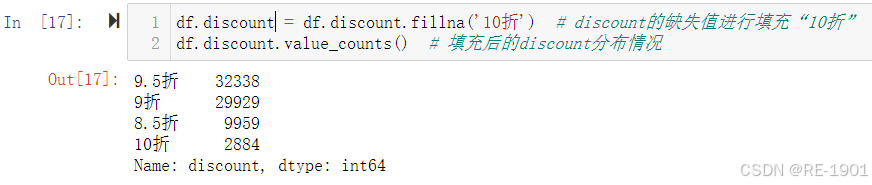
填充后的销售额缺失值数为0

## 2.将discount列的“折”去掉
# 将“折”去除后转化为浮点型,通过运算得到数值在0-1之间
df.discount = df.discount.apply(lambda x: float(x.replace("折",""))/10)
df.discount.value_counts() # discount列的分布,观察是否都去除折字
## 3.计算销售额sales
df['sales'] = df['price'] * df['sold'] * df['discount']
3.1.2 问题解决 - 店铺
店铺的数量
shop_num = len(df['shop_name'].unique())
shop_num #店铺的数量
各店铺销售额占比
分析步骤:
1.对相同店铺名字的销售额进行聚合2.计算出销售额的占比
3.对各店铺销售额占比进行排序
## 1.根据shop_name对sales进行groupby聚和,通过reset_index对索引进行更新
shop_sales = df.groupby('shop_name')['sales'].sum().reset_index()
## 2.计算出销售额占比
shop_sales['sales_account'] = shop_sales['sales'] / sum(shop_sales.sales)
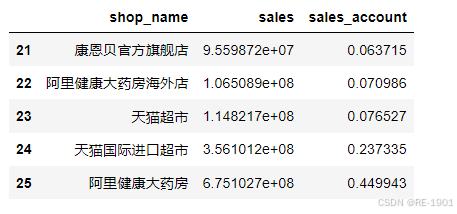
## 3.对销售额占比进行排序
shop_sales = shop_sales.sort_values(by=['sales_account'],ascending=True).reset_index(drop=True) #True是升序,由小到大排列
shop_sales.tail() #选取最后5个数据
店铺销售额可视化分析
1.各店铺销售额占比可视化(条形图)
2.最高销售额店铺的可视化(折线图)
1.各店铺销售额占比可视化
由于店铺太多,通过画图把全部的店铺都进行绘画会感觉不太好看,通过分析,可以将占比很少的部分归为一类“其他”(选取销售额占比前7的商铺,其余商铺则归纳于“其他店铺”)
df_sales = shop_sales.copy()
df_sales = df_sales.sort_values(by='sales_account',ascending=False).reset_index(drop=True) #进行降序排序,索引重置
df_sales['shop_name'] = df_sales['shop_name'].apply(lambda x: x if x in df_sales['shop_name'].values[0:7] else "其他店铺")
#对shop_name进行apply遍历,通过lambda自定义函数进行列表生成式选取销售额占比前7的商铺,其余商铺则归纳于“其他店铺”
在将其余商铺则归纳于“其他店铺”,那要重新再一次进行聚合和排序的操作
df_sales = df_sales.groupby('shop_name')['sales_account'].sum().reset_index() #聚合不用drop参数
df_sales = df_sales.sort_values(by=['sales_account'],ascending=True).reset_index(drop=True) #有小到大,排序需要drop参数
df_sales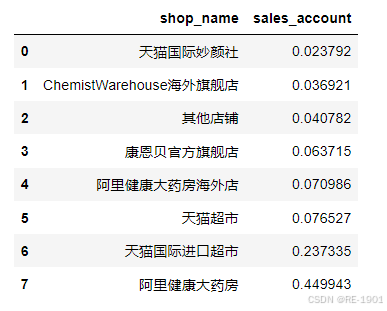
条形图
#窗口大小
fig, ax = plt.subplots()
#设置参数
x = df_sales['sales_account'].values # 值
x_labels = df_sales['shop_name'].values # 标签
num = len(df_sales['shop_name'])
y = np.arange(num)
#图形绘画
p1 = plt.barh(y # y轴的个数
, height=0.5 # 水平条的宽度
, width=x # 水平条的长度
,tick_label = x_labels #标签
,color ='orange' # 颜色
,label = '占比率'
)
#优化设置
plt.title('各商铺的销售额占比图')
plt.legend(loc="center right",fontsize=15)
plt.xticks([]) #去除x刻度
#数值显示
for a, b in zip(y, x):
plt.text(b, a + 0.1,round(b,4), ha='left', va='top', fontsize=12,color='b')
#边框设置
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_color('none')
ax.spines['left'].set_color('green')
#图形展示
plt.show()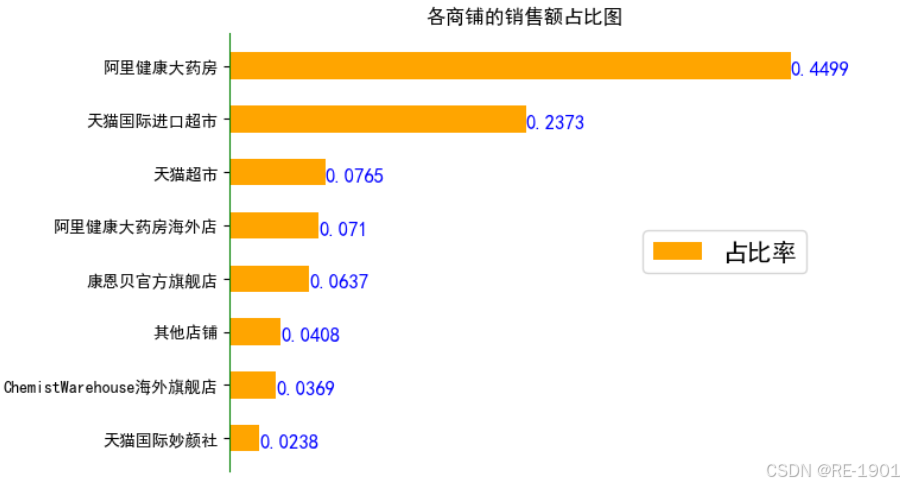
2.最高销售额店铺的可视化
①查找出最高的销售额店铺 ②提取该店铺的数据 ③可视化
shop_sales.tail(1)['shop_name'] #销售额最高店铺
max_shop = df[df['shop_name'] == '阿里健康大药房'] # 提取销售额最高店铺的数据
## 根据时间分析
max_shop_time = max_shop.groupby('date_time')['sales'].sum().reset_index() #对时间根据销售额聚合
max_shop_time.head()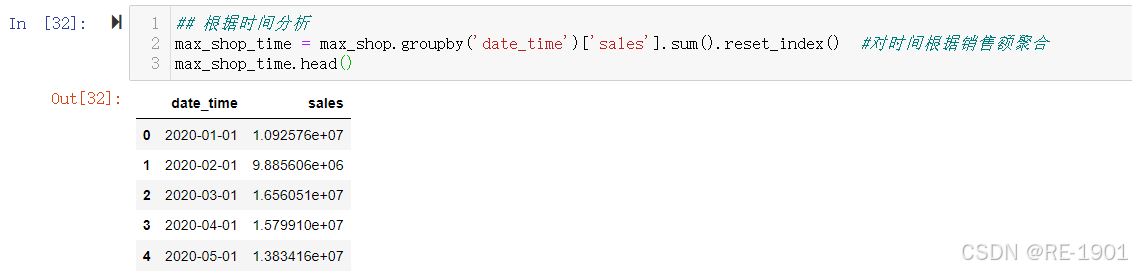
折线图分析
fig, ax = plt.subplots()
x = max_shop_time.date_time.values
y = max_shop_time.sales.values
plt.plot(x,y,'*--',color='r',alpha=0.5)
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.ylabel('销售量')
plt.xticks(rotation=30) #x轴刻度的方向倾斜度
plt.title('阿里健康大药房-月销售量折线图')
plt.show()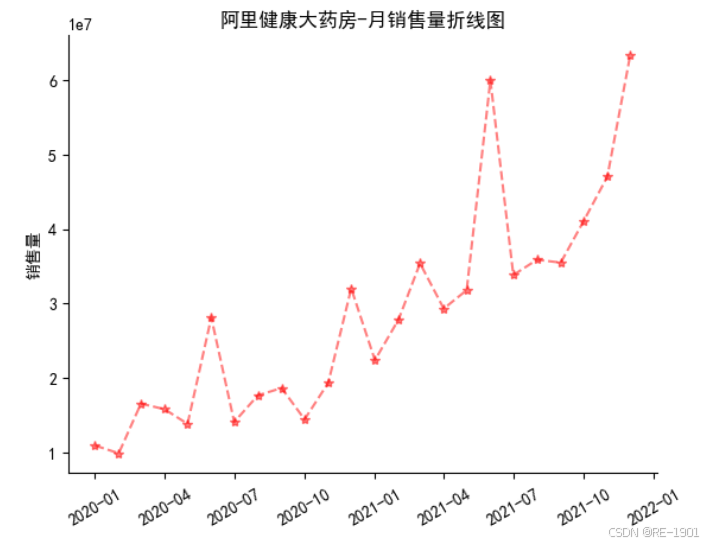
本文只选取了时间的角度去分析,还可以从其他角度分析!
3.2 问题二 (药品)
对所有药品进行分析,一共包含多少个药品,各药品的销售额占比如何?给出销售额占比最高的10个药品,并绘制这10个药品每月销售额曲线图。
查看目前的表格内容和数据

3.2.1 预处理分析
药品 (发现存在“一个id对应多个title”和“多个id对应一个title”这种情况)
df[df.id==3985971101463].head(2) #发现一个id对应多个title
df[df.title=='买2送礼】elevit/爱乐维复合维生素片140粒维生素缺乏症贫血官方'].head(2) #发现多个id对应一个title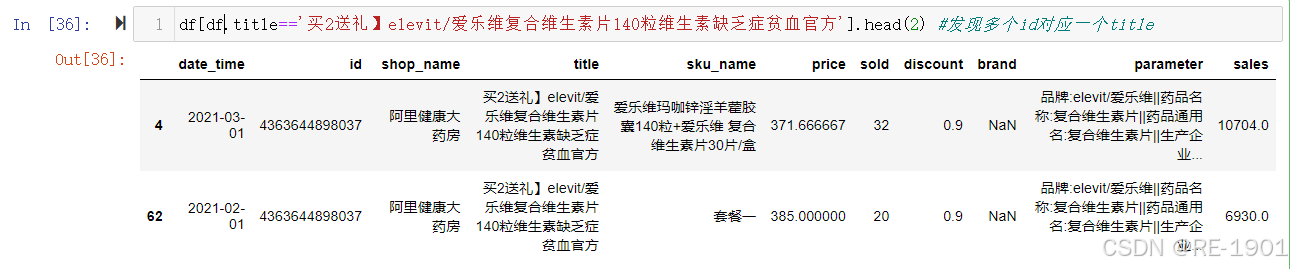
发现问题:通过上面两发现,无法从id和title入手选取药品的数量,因为存在“一个id对应多个title”和“多个id对应一个title”这种情况
解决方法:只能从parameter列入手;因为在parameter列有“药品名称”“药品通用名”“产品名称”,可根据这些判断药品,若都无则“***”
#定义函数
def function(s):
try:
s = s.split('||')
s = [i.split(':') for i in s]
s1 = [i[1] for i in s if '产品名称' in i][0]
s2 = [i[1] for i in s if '药品名称' in i][0]
s3 = [i[1] for i in s if '药品通用名' in i][0]
if len(s3)>0:
return s3
elif len(s2)>0:
return s2
elif len(s1)>0:
return s1
else:
return '***' # ***表示还未找到药品名称
except Exception:
return '***'
df['medicines'] = df.parameter.apply(function) #对parameter列进行遍历,通过函数进行实现
df.head(3)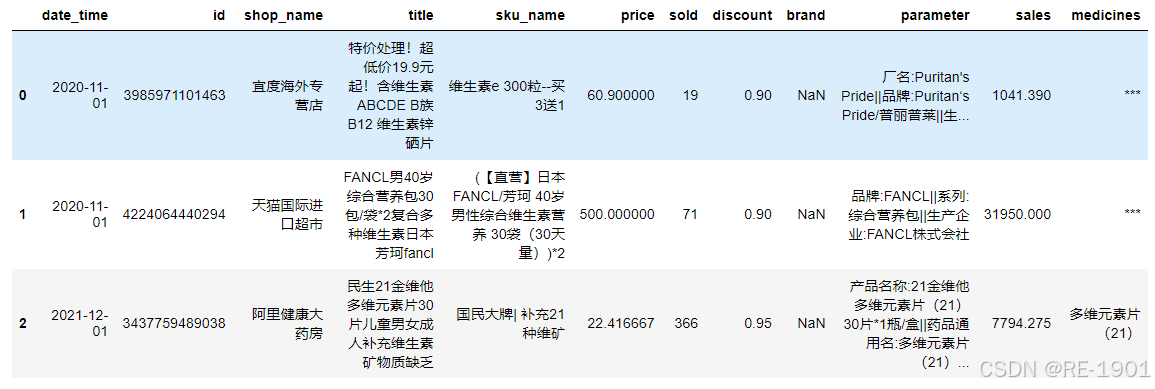
3.2.2 问题解决 - 药品
药品的数量
df_medicines = df[df['medicines'] != "***"] # 选取parameter_medicines列不等于“***”的值
len(df_medicines['medicines'].drop_duplicates()) # 药品的数量
各药品的销售额占比
#根据药品对销售额聚合,降序排序,索引重置
medicines_sales = df_medicines.groupby('medicines')['sales'].sum().reset_index().sort_values(by='sales',ascending = False).reset_index(drop=True)
medicines_sales['medicines_account'] = medicines_sales['sales']/sum(medicines_sales['sales'])
medicines_sales #药品销售额占比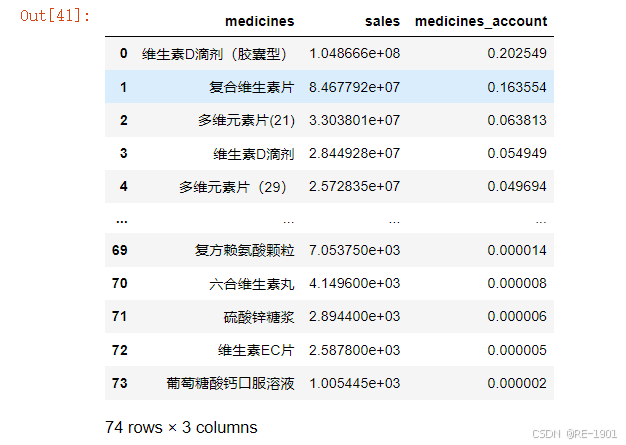
药品销售额可视化分析
1.各药品销售额占比可视化(饼图)
2.前十药品销售额的可视化(折线图)
1.各药品销售额占比可视化(饼图)
与店铺问题一的条形图一样想法,将排名靠后的占比归纳为“其他药品”
term = medicines_sales.copy()
term.medicines = term.medicines.apply(lambda x: x if x in term['medicines'].values[0:15] else "其余药品" )
term = term.groupby('medicines')['medicines_account'].sum().reset_index().sort_values(by='medicines_account',ascending=False).reset_index(drop = True)
term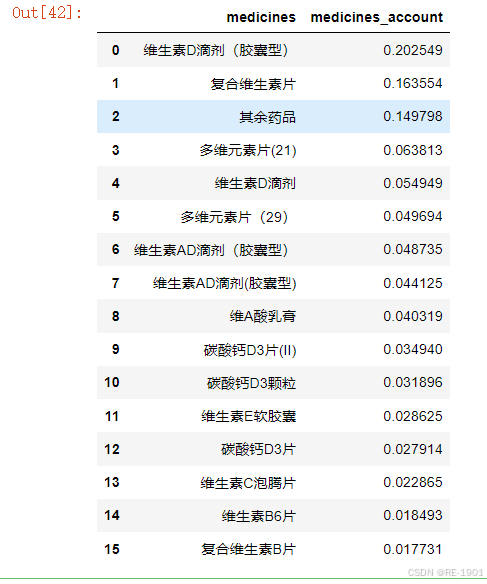
饼图
plt.figure(figsize=(5,6),dpi=150)
plt.pie(term['medicines_account'].values # x值
,explode = [0.05 for i in range(len(term['medicines_account'].values))] # 间隔为0.1
,autopct = '%0.2f%%' # 保留两位小数,百分比
,labels = term['medicines'].values # 标签
,textprops={"fontsize":8}) # 字体的大小
plt.title('药品销售额占比')
plt.show()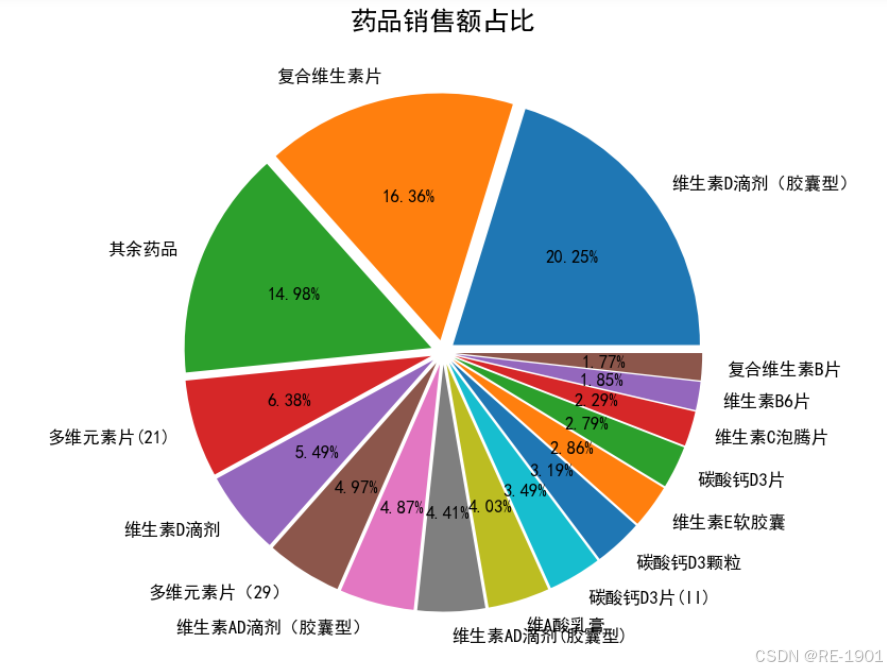
2.前十药品销售额的可视化(折线图)
medicines_top = medicines_sales.head(10) #占比前10
medicines_top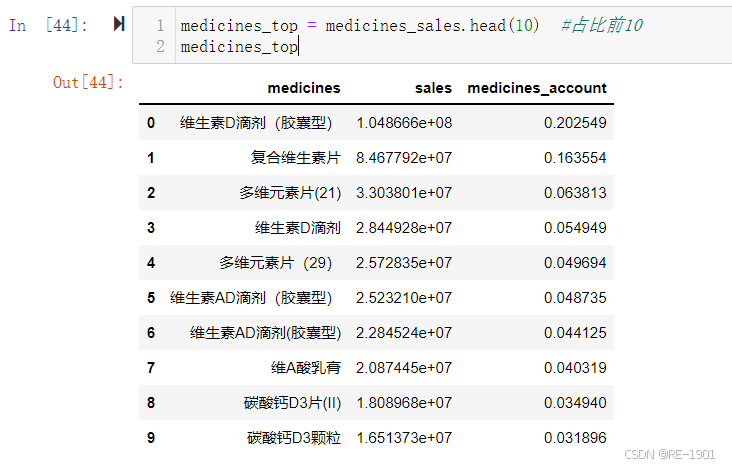
# 图一
fig = plt.figure(dpi=140)
ax = fig.subplots()
for i in medicines_top["medicines"].values:
top_medicines = df[df['medicines'] == i]
top_medicines = top_medicines.groupby('date_time')['sales'].sum().reset_index()
plt.plot(top_medicines.date_time.values # x值
,top_medicines.sales.values # y值
,label = i # 标签
)
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
plt.legend()
plt.show()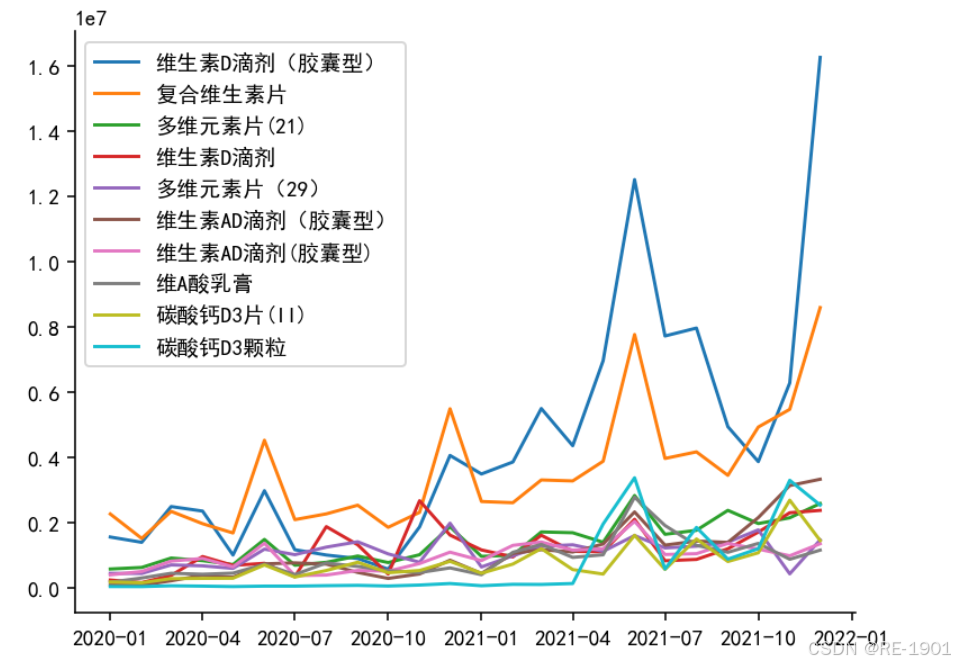
color_name = 'Set3'
plt.get_cmap(color_name)
# 图二
##窗口画板
fig = plt.figure(figsize=(18,20),dpi=200)
for i,j in enumerate(medicines_top["medicines"]): # enumerate语法,该循环的index读取的是索引数字(0,1,2,...);values读取的值
# 子图设置
plt.subplot(5,2,i+1)
##参数设置
top_medicines = df[df['medicines'] == j]
top_medicines = top_medicines.groupby('date_time')['sales'].sum().reset_index()
#颜色设置
color_choose = (i+2)
color = plt.get_cmap(color_name)(color_choose) #绘图用的颜色
#图形绘画
plt.plot(top_medicines.date_time.values # x值
,top_medicines.sales.values # y值
,label = '销售额变化' # 标签
,c = color # 颜色
,alpha = 1
)
#优化设置
plt.title(f'{j}的每月销售额变化')
plt.legend()
plt.show()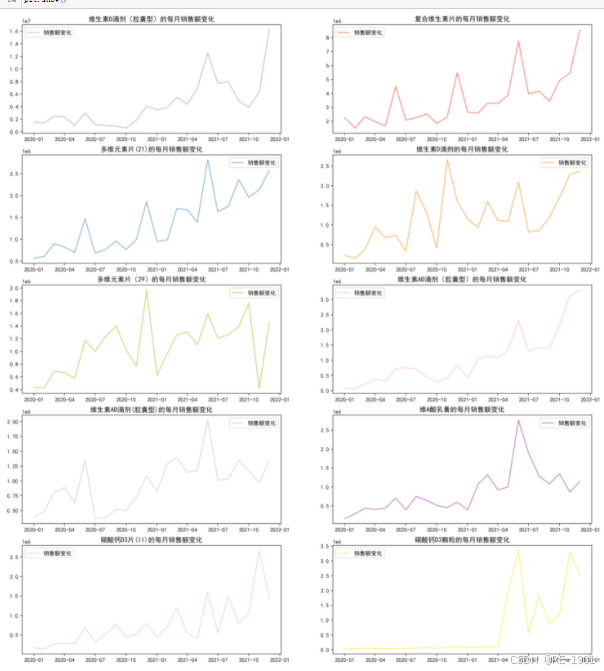
3.3 问题三 (品牌)
对所有药品品牌进行分析,一共包含多少个品牌,各品牌的销售额占比如何?给出销售额占比最高的10个品牌,并分析这10个品牌销售较好的原因?
3.3.1 预处理分析
品牌
# brand列的缺失值数据
df.brand.isnull().sum() # 51166
# parameter列的缺失值数据
df.parameter.isnull().sum() # 2552想法:品牌列的缺失值数据较多,parameter列缺失值较少,发现parameter列有含品牌的数据,可将parameter列的品牌数据填充到brand缺失值部分
 发现parameter列都有品牌数据,而且发现可用“||”作为分割符
发现parameter列都有品牌数据,而且发现可用“||”作为分割符
分析步骤:
1.将parameter列进行分割
2.将初步分割后的“品牌”部分放在每行的第一位位置(最前面)
3.将属于品牌的值的给提取出来
4.将从parameter得出的品牌值填充到df数据的brand列里
5.从title提取品牌到brand列里
6.对“品牌中英文夹杂”的品牌进行修改
##1.将parameter列进行分割
df_split = []
for i in list(df.parameter.values):
a = str(i).split('||')
df_split.append(a)
# 查看前几行分割的结果
for i in range(3):
print(df_split[i])
## 发现每行都是列表格式,列表里有不同的值,可以想到将“品牌”的部分放到列表的最前面,然后对品牌进行提取
##2.将初步分割后的“品牌”部分放在每行的第一位位置(最前面)
df_startswith = []
for i in df_split:
i.sort(key = lambda x : x.startswith('品牌'),reverse=True)
df_startswith.append(i)
#df_startswith
##函数解释:
#startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。
#list.sort(cmp=None, key=None, reverse=False):cmp 是可选参数进行排序;reverse = True 降序,reverse = False 升序(默认)
#key : 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
##代码解释:
#对初步分割好后的数据观察遍历,通过对每个列表里的值进行sort函数排序,参数key是为了按字符串开头是“品牌”的进行排序
#最后得到的是每个列表的第一个位置都是含有“品牌”的值
# 查看前几行的排序结果
for i in range(3):
print(df_startswith[i])
##3.将属于品牌的值的给提取出来
df_replace = []
for i in df_startswith:
a = i[0].replace('品牌:','')
df_replace.append(a)
#df_replace
##代码解释
#对排序好后的结果提取第一个值,即品牌的值,将“品牌:”以空值替掉,最后得到品牌的值
# 查看前几行的品牌
for i in range(3):
print(df_replace[i])
##4.将从parameter得出的品牌值填充到df数据的brand列里
df.brand[0]=='nan' #发现brand第一个值是缺失值,但不是nan
df.brand = df.brand.fillna('nan') #将brand列的缺失值填充为nan
parameter_brand = pd.DataFrame(df_replace,columns=['parameter_brand']) # 将df_replace转化为series格式
df = pd.concat([df,parameter_brand],axis=1) #数据合并,axis=1是列合并
# df.head(2)
# 填充
for i in range(len(df.brand)):
if df.parameter_brand[i] =='nan':
df.brand[i] = df.brand[i]
else:
df.brand[i] = df.parameter_brand[i]
len(df[df.brand == 'nan']) #查看brand列有无nan值 # 输出1653# 对品牌还是nan值中,发现title可能有点价值,想到品牌会不会也可以从title得到
##5.从title提取品牌到brand列里
df_nan = df[df.brand == 'nan']
title_brand=[]
for i in list(df_nan['title']):
for j in df_replace:
if j in i:
title_brand.append(j)
break
elif j[j.find('/')+1:] in i :
title_brand.append(j)
break
else:
title_brand.append(np.nan)
df_nan = df_nan.reset_index() #df_nan重置索引
# df_nan.head(3)
title_brand = pd.DataFrame(title_brand,columns=['title_brand']) # 将title_brand转化为series格式
title_brand.title_brand = title_brand.title_brand.fillna('nan') # 将title_brand的缺失值填充为nan
df_nan['brand'] = title_brand['title_brand'] # 将title_brand的值填充到df_nan的brand里
# df_nan.head(3)
len(df_nan[df_nan.brand=='nan']) #查看还有多少nan值 # 输出439
df_nan = df_nan[df_nan.brand !='nan'] #提取不等于nan的值,将nan的值剔除掉
df1 = df_nan.set_index('index') #从title里填充的品牌
df2 = df[df.brand != 'nan']
df2 = df2.reset_index().set_index('index')
df3 = pd.concat([df2,df1]) #将两个不同的列得到的品牌填充进行合并
df3 = df3.reset_index(drop=True)
print(len(df3))
df3.head(3)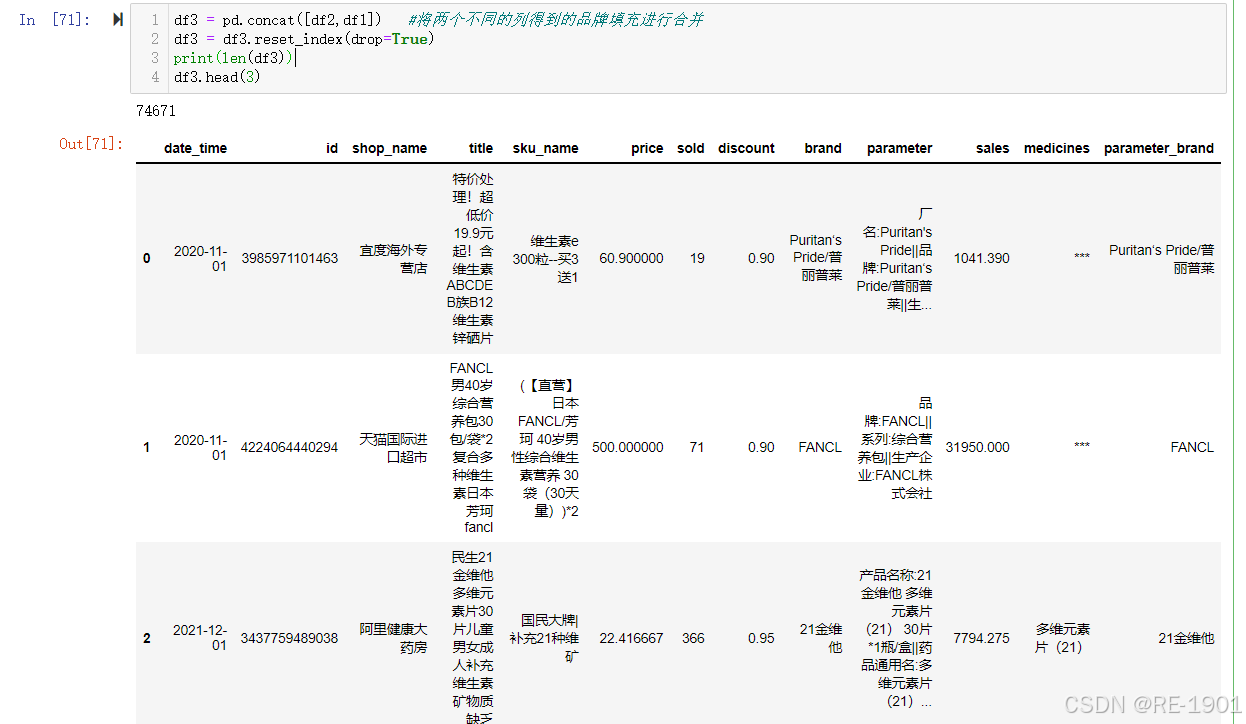
df.brand.value_counts() #发现存在中英夹杂的品牌
# 6.对“品牌中英文夹杂”的品牌进行修改
dic_brand = {
"Doctor's Best":"迪佰特",
"KAL":"凯雷澳",
"Nature Made":"天维美",
"OPPULAND":"欧普兰",
"Orthomol":"奥适宝",
"Ostelin":"奥斯特林",
"POLA":"宝丽",
# 中文补英文
"汤臣倍健":"BY-HEALTH",
"爱乐维":"elevit",
"禾博士":"Dr.Herbs"
}
def change_brand(s):
for i in dic_brand.keys():
if i in s.split('/'):
return f'{i}/{dic_brand[i]}'
return s
df3.brand = df3.brand.apply(change_brand)
df3.head(2)
3.3.2 问题解决 - 品牌
品牌的数量
len(df3.brand.unique()) #品牌的数量
各品牌的销售额占比
brand_sales = df3.groupby('brand')['sales'].sum().reset_index().sort_values(by='sales',ascending=False).reset_index(drop =True) # 降序
brand_sales['brand_account'] = brand_sales['sales']/sum(brand_sales['sales']) # 销售额占比
brand_sales.head(10) # 前10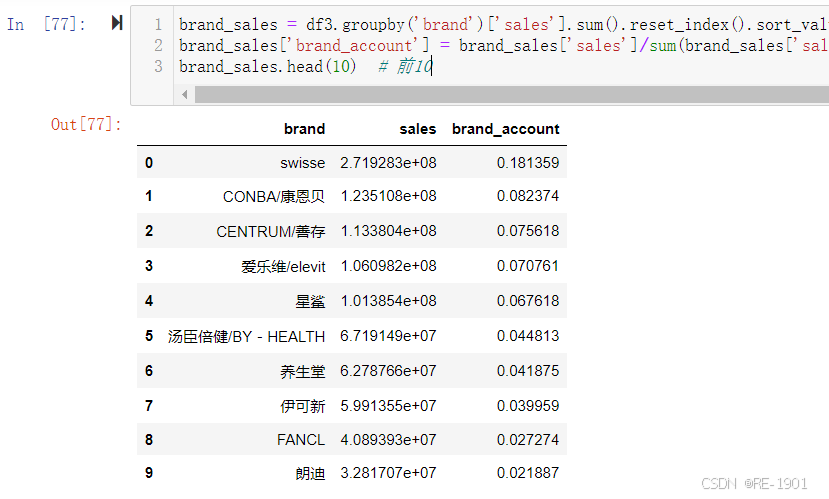
term = brand_sales.copy()
term.brand = term.brand.apply(lambda x: x if x in term['brand'].values[0:10] else "其余药品" )
term = term.groupby('brand')['brand_account'].sum().reset_index().sort_values(by='brand_account',ascending=True).reset_index(drop = True)
term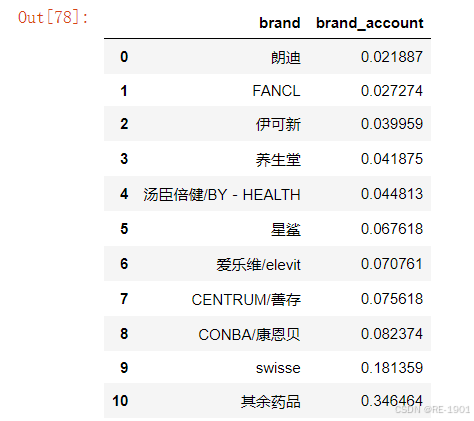
品牌销售额可视化分析
#窗口大小
fig, ax = plt.subplots()
#设置参数
x = term['brand_account'].values # 值
x_labels = term['brand'].values # 标签
num = len(term['brand'])
y = np.arange(num)
#图形绘画
p1 = plt.barh(y # y轴的个数
, height=0.5 # 水平条的宽度
, width=x # 水平条的长度
,tick_label = x_labels #标签
,color ='gray' # 颜色
,label = '占比率'
)
#优化设置
plt.title('各品牌的销售额占比分析')
plt.legend(loc="center right",fontsize=14)
plt.xticks([]) #去除x刻度
#数值显示
for a, b in zip(y, x):
plt.text(b, a + 0.15,round(b,4), ha='left', va='top', fontsize=12,color='orange')
#边框设置
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_color('none')
ax.spines['left'].set_color('orange')
#图形展示
plt.show()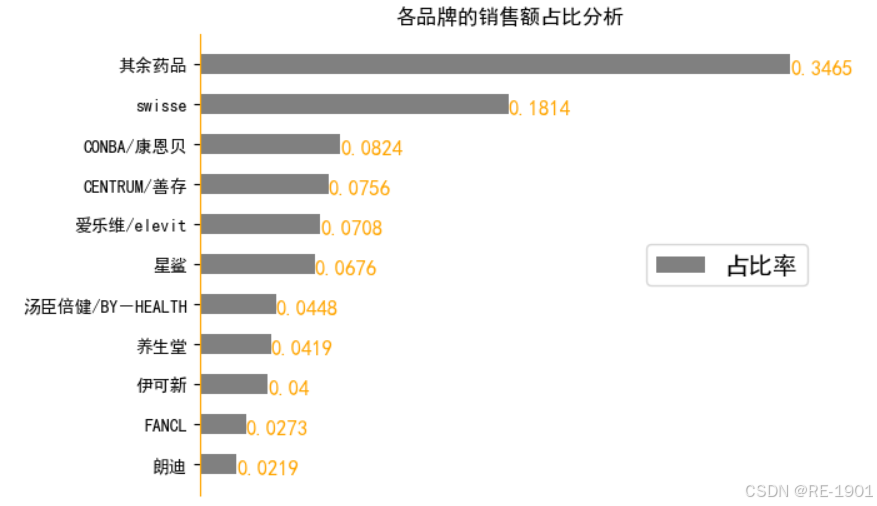
本文仅分析了一个原因,主要靠各位发散思维,有很多角度都可以思考的。
3.4 问题四 (ARIMA)
预测天猫维生素类药品未来三个月的销售总额并绘制拟合曲线,评估模型性能和误差。
由于都是天猫类商品,所以只需要'date_time',"sales"两列指标即可,本文采用了时间序列模型进行分析。
df4 = df[['date_time',"sales"]]
import datetime as dt
df4.date_time = df4.date_time.dt.date
df4 = df4.groupby('date_time')['sales'].sum().reset_index()
df4 = df4.set_index('date_time')
df4
3.4.1 预处理
#时序图
fig = plt.figure(figsize=(9,5),dpi=150)
ax = fig.subplots()
plt.plot(df4
,c = 'orange'
,alpha = 0.8
,label = '折线'
,linestyle = '--')
plt.scatter(df4.index
,df4.values
,marker='*' # 点型
,s=30 # 大小
,color='red' # 颜色
,edgecolor='red' # 边缘颜色
,facecolor='blue' # 填充色
,alpha=0.8
,label='散点')
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
plt.legend(fontsize=13,loc=4)
plt.title('销售额--时序图')
plt.show()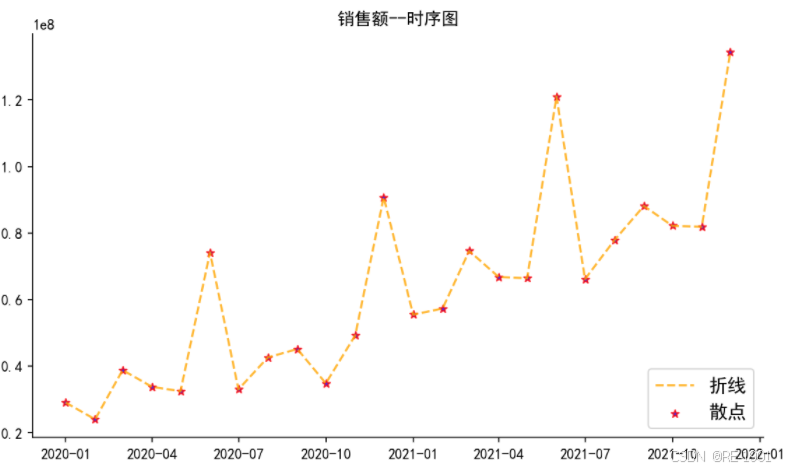
#平稳性检验--ADF检验
from statsmodels.tsa.stattools import adfuller
def adfull(ser):
adf_test = adfuller(ser)
adf_output = pd.Series(adf_test[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in adf_test[4].items():
adf_output['Critical Value (%s)'%key] = value
return adf_output
adfull(df4)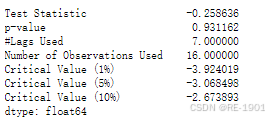
##发现p值大于0.05,说明序列不平稳,需要进行差分
df4_diff = df4.diff(1).dropna() #一阶差分后,除去异常值
plt.plot(df4_diff)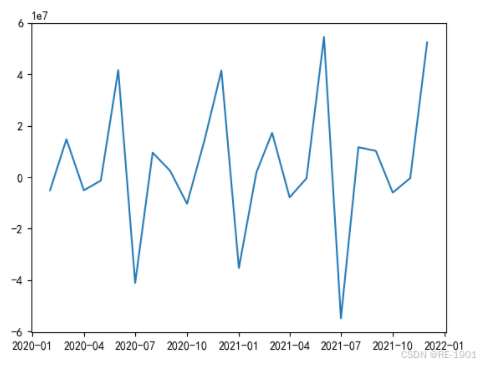
adfull(df4_diff) #一阶差分后平稳了 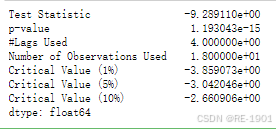
#白噪声序列检验--LB检验
from statsmodels.stats.diagnostic import acorr_ljungbox as lb_text
p = lb_text(df4_diff,lags=1).iloc[0,1]
if p <0.05:
print(f"p值={p},拒绝原假设,因此该序列为非白噪声序列")
else:
print(f"p值={p},不拒绝原假设,因此该序列为白噪声序列")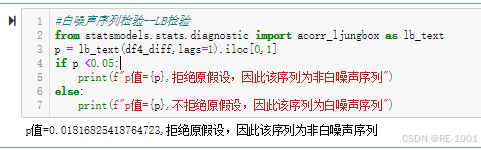
3.4.2 模型定阶
#ACF图、PACF图
from statsmodels.graphics.tsaplots import plot_acf,plot_pacf
def acf_pacf(ser,lag): #lag是横坐标的刻度数,不能过行数的一半
fig = plt.figure(figsize=(14,8))
pict1 = fig.add_subplot(211)
plot_acf(ser,ax=pict1,lags=lag)
pict2 = fig.add_subplot(212)
plot_pacf(ser,ax=pict2,lags=lag)
plt.subplots_adjust(hspace=0.5)
plt.show()
acf_pacf(df4_diff,8)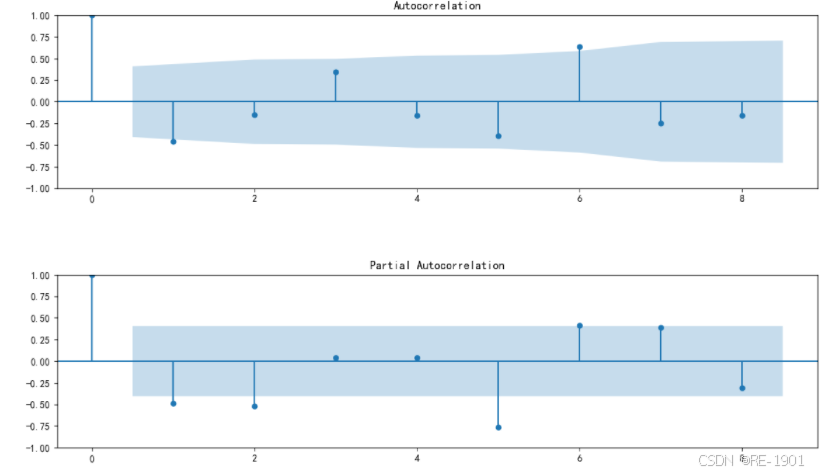 所以确定阶数(数值最小): p = 4 ; q = 4,最后确定:ARIMA(4,1,4)
所以确定阶数(数值最小): p = 4 ; q = 4,最后确定:ARIMA(4,1,4)
3.4.3 构建评估
y_train = df4_diff.values
x = df4_diff.index
#导入库
from statsmodels.tsa.arima.model import ARIMA
#模型构建及训练
model_ARIMA=ARIMA(y_train,order=(4,1,4)).fit()
#模型评估
y_test = model_ARIMA.predict(steps=len(y_train))
fig = plt.figure(figsize=(10,5),dpi=250)
ax = fig.subplots()
plt.plot(x,y_train,c='r', label='真实值', linewidth=0.8)
plt.plot(x,y_test, c='b', label='预测值', linewidth=0.8)
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
plt.title('真实值和预测值对比评估',fontsize=10,fontweight='light')
plt.xticks(rotation=0)
plt.legend(loc='best',fontsize=10)
plt.show()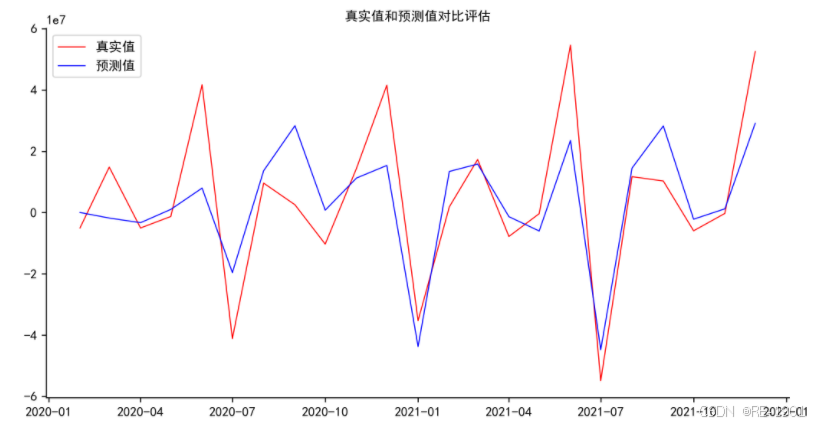
#误差图
a=pd.DataFrame(y_train)
b=pd.DataFrame(y_test)
c=pd.concat([a,b],axis=1)
h=c.iloc[:,0]-c.iloc[:,1]
plt.plot(x,h)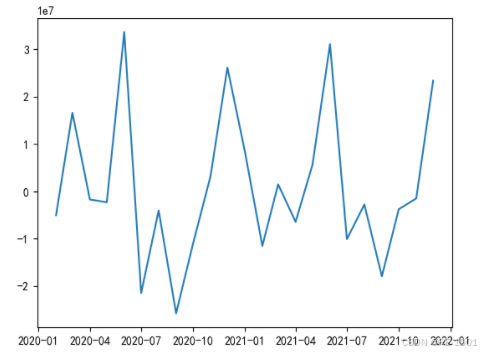
model_ARIMA.summary()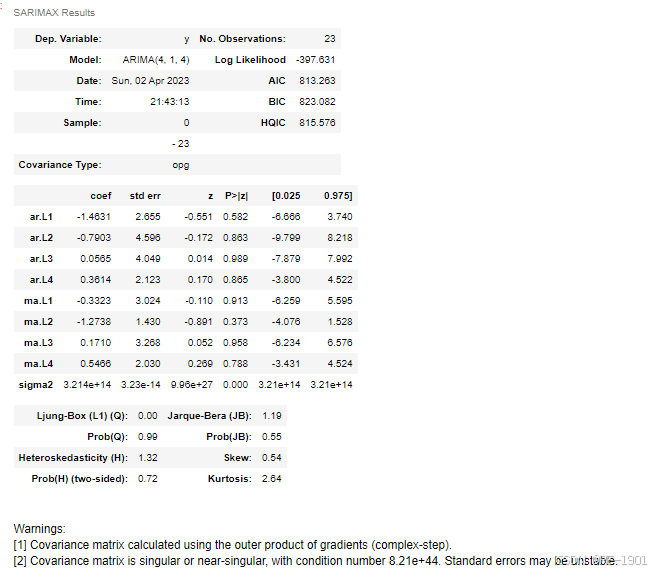
# #################################拟合优度R^2的计算######################################
def __sst(y_no_fitting):
"""
计算SST(total sum of squares) 总平方和
:param y_no_predicted: List[int] or array[int] 待拟合的y
:return: 总平方和SST
"""
y_mean = sum(y_no_fitting) / len(y_no_fitting)
s_list =[(y - y_mean)**2 for y in y_no_fitting]
sst = sum(s_list)
return sst
def __ssr(y_fitting, y_no_fitting):
"""
计算SSR(regression sum of squares) 回归平方和
:param y_fitting: List[int] or array[int] 拟合好的y值
:param y_no_fitting: List[int] or array[int] 待拟合y值
:return: 回归平方和SSR
"""
y_mean = sum(y_no_fitting) / len(y_no_fitting)
s_list =[(y - y_mean)**2 for y in y_fitting]
ssr = sum(s_list)
return ssr
def __sse(y_fitting, y_no_fitting):
"""
计算SSE(error sum of squares) 残差平方和
:param y_fitting: List[int] or array[int] 拟合好的y值
:param y_no_fitting: List[int] or array[int] 待拟合y值
:return: 残差平方和SSE
"""
s_list = [(y_fitting[i] - y_no_fitting[i])**2 for i in range(len(y_fitting))]
sse = sum(s_list)
return sse
def goodness_of_fit(y_fitting, y_no_fitting):
"""
计算拟合优度R^2
:param y_fitting: List[int] or array[int] 拟合好的y值
:param y_no_fitting: List[int] or array[int] 待拟合y值
:return: 拟合优度R^2
"""
SSR = __ssr(y_fitting, y_no_fitting)
SST = __sst(y_no_fitting)
rr = SSR /SST
return rr
rr = goodness_of_fit(y_test, y_train)
print("拟合优度为:", rr)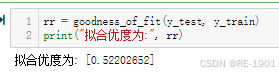
3.4.4 模型预测
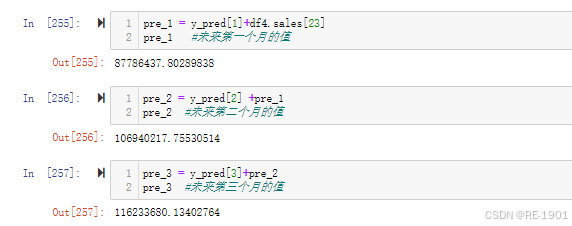
y_pred=model_ARIMA.forecast(steps=3)
y_pred # array([-46562454.60299844, 19153779.95240676, 9293462.3787225 ])
y_pred = [a[0][22],-46562454.60299844, 19153779.95240676, 9293462.3787225 ]
d = pd.DataFrame(y_pred,index=[23,24,25,26])
plt.plot(a,c='b')
plt.plot(d,c='r')
#差分还原
y_pred # [52464497.48061043, -46562454.60299844, 19153779.95240676, 9293462.3787225]
四、资源获取
本文的题目、数据和代码全部在博客的资源了,若有需要可进行下载!
五、结束语
本文的分析至此基本完成,题目的难度适中。作为数据分析领域的初学者,我可能在内容上存在一些不足或错误之处。如果有任何资深人士发现这些问题,请不吝指出并给予指导,我会及时修改,以帮助大家采用更准确的方法进行学习和实践。
若对这篇文章能对您的学习和工作有所帮助,请动动你的宝贵的小手指,点赞+收藏+关注!后续还会更新我自己写的笔记哦~




















 782
782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









