







参考了han同学的答案,西瓜数据集也可在han同学的github上下载。
3.5 编辑实现线性判别分析,并给出西瓜数据集 3.0α 上的结果.
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 下面这两行是为了让matplotlib画图时的汉字正常显示
import matplotlib
matplotlib.rc("font",family='YouYuan')
class LDA(object):
# 绘图,求出均值向量,根据公式3.34和3.39求出类内散度矩阵和类间散度矩阵
def fit(self, X_, y_, plot_=False):
# 取出正反例各自数据,计算均值向量
neg = y_ == 0
pos = y_ == 1
X0 = X_[neg]
X1 = X_[pos]
# 均值向量,(1, 2)
u0 = X0.mean(0, keepdims=True)
u1 = X1.mean(0, keepdims=True)
# 类内散度矩阵,公式3.33,(2, 2)
sw = np.dot((X0 - u0).T, (X0 - u0)) + np.dot((X1 - u1).T, (X1 - u1))
# 类间散度矩阵,公式3.37,(1, 2)
w = np.dot(np.linalg.inv(sw), (u0 - u1).T).reshape(1, -1)
# 绘图
if plot_:
fig, ax = plt.subplots()
ax.spines['right'].set_color('none')
ax.spines['top'].set_color('none')
ax.spines['left'].set_position(('data', 0))
ax.spines['bottom'].set_position(('data', 0))
# 画样本点
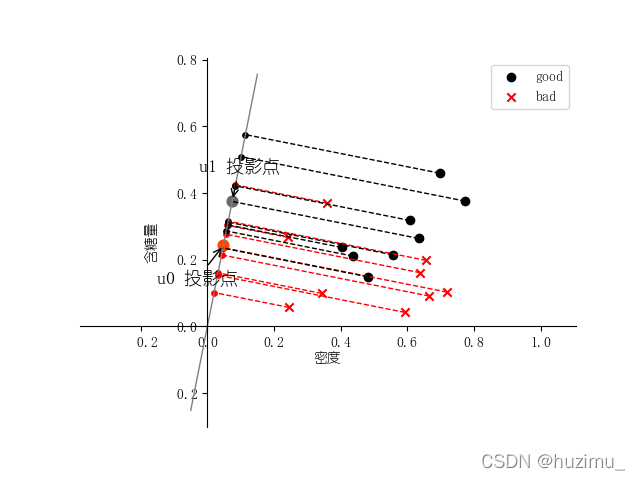
plt.scatter(X1[:, 0], X1[:, 1], c='k', marker='o', label='good')
plt.scatter(X0[:, 0], X0[:, 1], c='r', marker='x', label='bad')
plt.xlabel('密度')
plt.ylabel('含糖量')
plt.legend(loc='upper right')
# 画线
x_temp = np.linspace(-0.05, 0.15)
y_temp = x_temp * w[0, 1] / w[0, 0]
plt.plot(x_temp, y_temp, '#808080', linewidth=1)
wu = w / np.linalg.norm(w)
# 画正负样本点的投影,真的没看懂哈哈哈
X0_project = np.dot(X0, np.dot(wu.T, wu))
plt.scatter(X0_project[:, 0], X0_project[:, 1], c='r', s=15)
for i in range(X0.shape[0]):
plt.plot([X0[i, 0], X0_project[i, 0]], [X0[i, 1], X0_project[i, 1]], '--r', linewidth=1)
X1_project = np.dot(X1, np.dot(wu.T, wu))
plt.scatter(X1_project[:, 0], X1_project[:, 1], c='k', s=15)
for i in range(X1.shape[0]):
plt.plot([X1[i, 0], X1_project[i, 0]], [X1[i, 1], X1_project[i, 1]], '--r', linewidth=1)
# 均值向量的投影点
ax.annotate(r'u0 投影点',
xy=(u0_project[:, 0], u0_project[:, 1]),
xytext=(u0_project[:, 0] - 0.2, u0_project[:, 1] - 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
ax.annotate(r'u1 投影点',
xy=(u1_project[:, 0], u1_project[:, 1]),
xytext=(u1_project[:, 0] - 0.1, u1_project[:, 1] + 0.1),
size=13,
va="center", ha="left",
arrowprops=dict(arrowstyle="->",
color="k",
)
)
plt.axis("equal") # 两坐标轴的单位刻度长度保存一致
plt.show()
self.w = w
self.u0 = u0
self.u1 = u1
return self
def predict(self, X):
# 各样本在的投影
project = np.dot(X, self.w.T)
# 均值投影
wu0 = np.dot(self.w, self.u0.T)
wu1 = np.dot(self.w, self.u1.T)
return (np.abs(project - wu1) < np.abs(project - wu0)).astype(int)
if __name__=='__main__':
data_path = r'C:\***\ch3--线性模型\3.3\watermelon3_0_Ch.csv'
data = pd.read_csv(data_path).values
# print(data)
X = data[:, 7:9].astype(float)
y = data[:, 9]
y[y == '是'] = 1
y[y == '否'] = 0
y = y.astype(int)
lda = LDA()
lda.fit(X, y, plot_=True)
# 根据LDA的进行预测
print(lda.predict(X)[:, 0])
# 样本标记
print(y)














 2202
2202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









