







Forget-Me-Not: Learning to Forget in Text-to-Image Diffusion Models
论文链接
代码链接
这篇文章提出了Forget-Me-Not (FMN),用来消除文生图扩散模型中的特定内容。FMN的流程图如下:

可以看到,FMN的损失函数是最小化要消除的概念对应的attention map的
L
2
L_2
L2范数。这里需要补充一些关于diffusion model的知识。
首先,以Stable Diffusion为代表的模型使用U-Net对图片的低维嵌入进行建模。文本条件在被CLIP的text encoder编码为文本嵌入后,通过U-Net中的cross-attention layers输入到U-Net中。cross-attention层的具体映射过程是一个QKV (Query-Key-
Value)结构,如上图的中间所示。其中,Q代表图片的视觉信息,K和V都是文本嵌入经过线性层后计算得到的(
k
i
=
W
k
c
i
a
n
d
v
i
=
W
v
c
i
k_i = W_kc_i~and~v_i = W_vc_i
ki=Wkci and vi=Wvci)。而FMN损失函数中的attention map的计算过程如下:
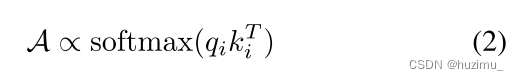
然而,attention map还不是cross attention层的输出,其输出通过以下公式计算:

上面两个公式,也就是图3中间方框中的内容,可以用下面的公式概括,
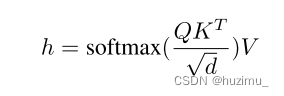
从FMN的源码中可以看到对应的部分如下:
class AttnController:
def __init__(self) -> None:
self.attn_probs = []
self.logs = []
def __call__(self, attn_prob, m_name) -> Any:
bs, _ = self.concept_positions.shape
head_num = attn_prob.shape[0] // bs
target_attns = attn_prob.masked_select(self.concept_positions[:,None,:].repeat(head_num, 1, 1)).reshape(-1, self.concept_positions[0].sum())
self.attn_probs.append(target_attns)
self.logs.append(m_name)
def set_concept_positions(self, concept_positions):
self.concept_positions = concept_positions
def loss(self):
return torch.cat(self.attn_probs).norm()
def zero_attn_probs(self):
self.attn_probs = []
self.logs = []
self.concept_positions = None















 1678
1678











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









