









本文转载自:
http://blog.csdn.net/u010167269/article/details/52389676
Preface
重新把注意力放到了 自然场景文本检测与识别 上了。已经从这块方向离开了一年多了。再回来,已经物是人非。都不像以前那么玩了,论文赶紧看起来。
上次阅读完 Reading Text in the Wild with Convolutional Neural Networks 之后,文中提到了作者自己生成了 Synthetic Data(人工合成自然场景文本数据)。我想这数据是如何生成的呢?恰好看见 VGG 实验室这篇 CVPR2016 的 Paper:Synthetic Data for Text Localisation in Natural Images。
这篇 Paper 讲的正是如何生成这些数据;并且提出了 Fully-Convolutional Regression Network ( FCRN ),在 ICDAR 2013 上的 F-measure 达到了 84.2% ;同时,本文比较了 FCRN 与 YOLO 及其他 end-to-end object detection。
作者已经公布了这篇文章的源码:https://github.com/ankush-me/SynthText,VGG 组果然业内良心。
Introduction
现在较为 state-of-art 的文字检测识别系统,结合了两个简单但非常有用的 idea:
- 将原先先对单个字母进行检测识别,再组合成单词的 pipeline,改变为 将对单个字母、单个字母的检测识别过程,改变为分类过程,即用一个分类器直接对文字区域进行分类,类别即为文字的整个单词;
- 因为这样的分类器,分的类别巨大,因此需要很多很多的训练样本。因此,可以人工生成训练样本(Synthetic Data)。即将一个单词直接“粘”在自然场景图像上(以一定的方式、规则)。这样就可以产生很多很多的 training data。
上面的这两点 idea,在上一篇 Reading Text in the Wild with Convolutional Neural Networks 中都有体现。
其实不光是上一篇,还有 ICLR 2014 的 Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks 这篇,就将单字母的识别过程转变为 classifiy 问题。
在 NIPS 2014 的 Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition 这篇;以及 ICPR 2012 的 End-to-End Text Recognition with Convolutional Neural Networks 这篇,就用到了 Synthetic Data。
虽然 Reading Text in the Wild with Convolutional Neural Networks 这篇将文字的识别过程转变成 classify的过程。但 recognition 之前 text region proposals 生成的 pipeline,却十分得繁琐、不优雅。从我之前的这篇博文也可以看到,在 detection 的 pipeline 中,结合了 HoG、EdgeBoxes、Aggregate Channel Features,在通过这些特征检测生成 text region proposals 之后,才在 recognition 中用到了 CNN 分类。
可以看到,上面的过程有两个缺点:
- 有个 bottleneck,即文字区域的 detection 性能将决定最后 recognition 的质量,以及整体系统检测识别的质量。如文字区域的 recall 通过结合 EdgeBoxes、ACF features 达到了 98% ,然而,整个系统的 F−score 却只有 69% ,因为有许多错误的、缺失的 word region proposals;
- 整个的 pipeline 十分的繁琐、慢,同时一点也不优雅。从我上篇博客的笔记就可以看出,用了好多的特征,又用了 random forest 分类器,很复杂。
本文同样出自 VGG,也是对上一篇 Reading Text in the Wild with Convolutional Neural Networks 中 word detection 的 complementary。本文做了两点贡献:
-
提出了一种新的方法,使用现成的 deep learning、segmentation 技术将 word 排列进自然场景图片中,能将 word 很自然的融入进自然场景图片中。这样,自动生成 synthetic data,本文称这种数据集为SynthText in the Wild,如 Figure 2,它可以用于训练自然场景文字的 word detector。而 Reading Text in the Wild with Convolutional Neural Networks 这篇最后自动生成的文字,不是很自然的融进图片中,只能用作最后的 recognition 的训练数据。
-
本文的第二个贡献点在于提出了一种 word detection CNN网络,叫做 fully-convolutional regression network ( FCRN )。类似又不同于于 Jonathan Long 提出的 Fully Convolutional Networks,本文最后prediction 的结果不仅仅是每个像素的类别(文字、非文字) ,而是 框出了文字区域的 bounding box的 parameters。这个 idea 借鉴于 You only look once: Unified, real-time object detection,但本文在其中使用了 convolutional regressor,大幅提升了性能。

Object Detection with CNNs
本文的 text detection 过程基于两个工作:
- Jonathan Long 等人的 Fully Convolutional Networks
- Joseph Redmon 等人的 You only look once: Unified, real-time object detection
CNN 特征用于物体的类别检测要追溯于 Girshick 等人的 Region-CNN(R-CNN),其方法结合了 region proposals 与 CNN 特征,YOLO 也是将 CNN 特征用于物体类别检测工作的其中一支。
总的来说,R-CNN 架构有三个阶段:
(1)生成 object proposals
(2)提取每个 proposal 的 CNN feature map
(3)使用 class specific SVMs 过滤 proposals
这篇 Reading Text in the Wild with Convolutional Neural Networks 使用了类似的 pipeline:EdgeBox + ACF features 得到 region proposals,再用 HoG 特征训练 Random Forests 进行 filtering,最后再 Bounding Box Regression 得到最后较为准确的文字 region region proposals
在 R-CNN 中,提取,每个 proposal 的 feature map 是计算瓶颈(proposal的region有几千个,多数都是互相重叠,重叠部分会被多次重复提取feature)。在 Girshick 随后发布的 Fast R-CNN 中,将 proposal 的 region 映射到 CNN 的最后一层 conv layer 的 feature map 上,这样一张图片只需要提取一次 feature,大大提高了速度,也由于流程的整合以及其他原因,在 VOC 2007 上的 mAP 也提高到了 68% ,文章中说速度加速了 100× 有余;同时,将上面 3 个阶段的第 2 、第 3 个阶段合并为一个多任务学习问题(Multi-task learning problem)。
但这类方法,在生成 region proposals 阶段又成为了新的 bottleneck。Lenc 等人在 BMVC 2015 的 R-CNN minus R 中取消了 region proposals 的生成阶段。Ren 等人在 2016 NIPS 的 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 中,直接从一组固定的 proposals 开始,但随后用Region Proposal Network 进行调增修缮。
Synthetic Data
人工合成数据有个好处,它可以准确知道文字的 label 信息,以及位置,不需要人工去标注。Wang 等人 ICPR 2012 的 End-to-End Text Recognition with Convolutional Neural Networks ,以及 Jaderberg 等人 NIPS Workshop on Deep Learning 2012 的 Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition ,就用了 Synthetic Image 去训练 CNN word recognition 网络。
文中还提及了其他用 Synthetic Data 来完成工作的文章。这里就不一一列举。
Augmenting Signle Images
这部分提及了,很多将 object 嵌入到其他场景种,达到 photo-realistic 的效果;并且,从单张图像推断 3D 结构的工作。
Synthetic Text in the Wild
训练一个 CNN 模型,需要大量的标注数据,如 AlexNet,因为有 ImageNet 这样级别的数据才能完成训练。
而诸如 ICDAR 这类数据集,其训练数据量很小,统计如下:
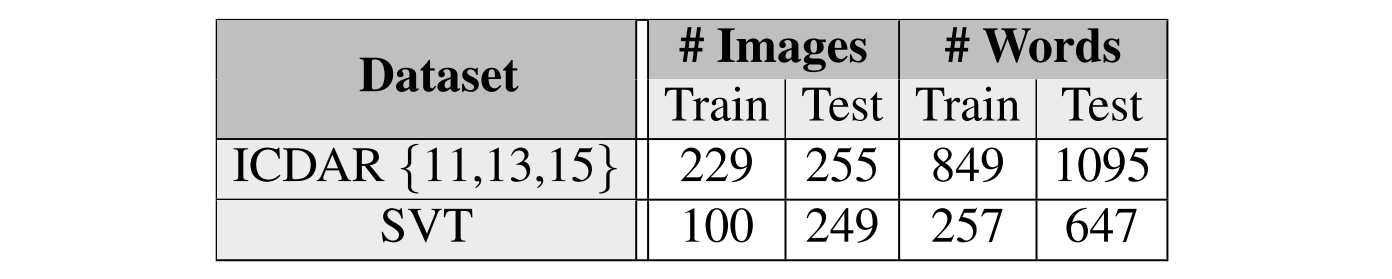
这样小的样本集,不仅不能训练 CNN,也不合适用来代表文字在自然场景下的所有变化情况:字体、颜色、大小、位置。因此,如果能够自然的人工合成标注数据,那么我们便可以得到大量的自然场景文本标注数据。这部分,本文介绍的是如何自然的合成人工自然场景文本数据。
本文提出的人工合成数据引擎有以下优点:
- Realistic,文字能够自然的融合到自然场景图片中
- automated
- fast,不需要监督就能快速生成大量的样本数据
生成的 pipeline 如下:
- 基于 local colour and texture cues,将图像分割成连续的区域(gPb-UCM segments)。同时,根据 CVPR 2015 的这篇 Deep convolutional neural fields for depth estimation from a single image 提出的 CNN 模型,获取像素级别的深度图像;-

Text and Image Sources
Synthetic Data 的生成,要先获取文本(word) 、背景图像。
文本从 Newsgroup 20 dataset 中得到,用 3 种方式采样获取:
- words,以 空格字符 分隔;
- lines,以 换行字符 定义;
- paragraph
背景图像的获取是通过 Google Image Search ,不同的 objects/scenes、不同的 indoor/outdoor、不同的 natural/artificial。
为了保证图像中的所有文字都有标注,因此,所获取的背景图像中,不能包含有文字。因此在检索图像时,要避免可能会检索出文字的关键词,如 street-sign,menu 等等。如果检索出带有文字的图像,人工删除之。
Segmentation and Geometry Estimation
在真实的自然场景图像中,文字是几乎不会跨越两种不同的区域的。因此,本文先对刚刚搜索到的自然背景图像,根据 local colour and texture 进行分割,分割成连续的区域,再将文字嵌入其中某一块区域。
在分割时,采用的是 Contour detection and hierarchical image segmentation 中的 gPb-UCM 算法(阈值: 0.11),采用 Multiscale combinatorial grouping 的实现。
自然场景中的文字一般都是在背景图像的表面上的。为了得到相同的效果,文字要根据 local surface normal去“放置”文本,具体为:本文先通过 Deep convolutional neural fields for depth estimation from a single image 提出的 CNN 模型,获取像素级别的深度图像。再用 RANSAC 去拟合出垂直于法向量的平面。然后就可以将文本安置在平面上,这样文本就较为自然的融入背景图像中了。
文本将以如下的步骤安置在分割的区域之中的:
(1)首先,使用估计出的平面法线(estimated plane normal),将图像区域轮廓弯曲成 fronto-parallel view,形成一个 fronto-parallel region
(2)然后,用一个矩形去拟合这个 fronto-parallel region
(3)最后,文本与上面矩形的较大边(width)对齐
当把多文本放入同一个 region 中时,要检查文本与文本之间之后有重叠,即一个文本不能重叠放置在之前的文本上;要注意,也不是所有的分割的 region 都适合嵌入文本:这样的 region 不能太小、region 的长宽比不能太过于悬殊,都要去除掉,此外,纹理太多的 region 也不适合嵌入文字,这里的纹理的多少,是由 RGB 图像的三阶导数的 strength 来衡量的。
我们在这里的处理过程中,用了 Deep convolutional neural fields for depth estimation from a single image的 CNN 模型来估计一张自然图像其对应的深度图像。但这里很容易饭的一个错误就是直接用 RGBD 数据来做,都省掉了 CNN 估计深度的过程。文本在这里用 CNN 来估计一个深度图像,而不是直接用 RGBD 的准确的深度数据,是因为以下几点:
-
用了 CNN 模型来估计深度图像,就可以处理所有的 RGBD 图像了,而不仅仅是 RGBD 数据库里的 RGB 图像。
-
现在公开可获取的 RGBD 数据集,如 NYUD v2、B3DO (Berkeley 3D Object Dataset)、Sintel、Make3D 在本文的任务中有一些缺陷:
(1)数据量太少(NYUD v2 数据集中只有 1500 张图像,Make3D 中只有 400 帧,B3DO 以及 Sintel 中也之有少量的视频)
(2)分辨率较低,有运动模糊
(3)NYUD v2、B3DO 只有室内自然场景数据
(4)Sintel 的视频数据中,场景变化也非常有限
Text Rendering and Image Composition
一旦需要被嵌入的文本的位置、方向定下来之后,就需要将文本赋予一种颜色。怎么赋予颜色,本文是从 IIIT5K Word Dataset 中裁剪下来的文字图像中学习得到的。
每一张裁剪的文字图像中的像素,用 K-means 将其分为两个集合,形成一个颜色对,一个集合是文字的颜色,一个集合是背景的颜色。
每当要去渲染要嵌入的文字的颜色时,与当前背景颜色最接近的文本颜色,即是我们需要渲染的颜色。思想很简单,最后用在 Lab colour space 中用 L2-norm 来度量颜色的相似度。
在渲染中,大约 20% 的文本需要加边框,边框的颜色选择,要么与前景的颜色相同,只不过颜色值增加了,或者减小了;要么选择前景背景颜色的均值。
为了保证人造数据的 illumination gradient,我们在文本上使用 Poisson 图像处理 ,代码文本使用了 Raskar 的实现:Fast Poisson Image Editing Code。
A Fast Text Detection Network
这部分介绍了本文所采用的文字区域检测的 CNN 模型结构。
用 x 代表一张图像,最常见的基于 CNN 的检测方法,就是先提出一些图像 region,这些 region 可能包含有待检测的目标,用一个 CNN 模型 c=ϕ(cropR(x))∈{0,1} ,来评判 region 是不是待检测的目标。
这种方法,即是大名鼎鼎的 R-CNN 所采用的策略。但因为每张图像都要评判数以千计的 region,R-CNN 的速度很慢,因为 R-CNN 中需要重复计算大量 region proposals 的 score,所以针对这些重复计算,作者提出了 Fast R-CNN 以及后续的 Faster R-CNN,这是后话。
一个更快的检测方法,构建一个固定域的 predictors (c,p)=ϕuv(x) ,其中每一个专门用于预测一个 object 周围特定图像位置 (u,v) 的: c∈R ,以及 p=(x−u,y−v,w,h) 。这里的 pose parameter 有两个: (x,y) 、 (w,h) 。 (x,y) 代表了 bounding box 的 location, (w,h) 代表了 bounding box 的大小。每一个 predictor ϕuv 都在 (x,y)∈Bρ(u,v) 内 predict objects。
上面的构造听起来很抽象,但以 Implicit Shape Model ( ISM ),以及 Hough voting 的实现为例,就很平常了。
本文受到 Jonathan Long et al. Fully Convolutional Networks,Joseph Redmon et al. You only look once: Unified, real-time object detection 工作的启发,本文提出了一个极端的 Hough voting 。在 ISM、Hough voting 中,独立个体的预测结果通过 image scheme、voting scheme 被汇总起来。YOLO 与之类似,不过没有直接的用个体的 prediction 结果。
YOLO 与 Hough voting 有很大的不同:Hough voting predictors
ϕuv(x)
具有局部平移不变性,而 YOLO 不具有,有两点原因:
(1) YOLO 中的每一个 predictor 可以从全局图像中采集信息,而不仅仅是以
(u,v)
为中心的 patch;
(2)每个
(u,v)
点上,YOLO 的 predictor 函数不相同。即当位置
(u,v)≠(u′,v′)
不同时,predictor 函数
ϕuv≠ϕu′,v′
不相同。
YOLO 方法在 PASCAL 或者 ImageNet 上检测物体时,可以从获取背景信息。但是本文发现,对于文本这样又小、多变的情况,并不适用。本文在这里提出了一种介乎于 YOLO、Hough voting 之间的方法。
YOLO 中,每一个 detector ϕuv(x) 仍直接 predict 物体的存在与否,但是不需要经过耗时的 voting 累加过程了。但是在 Hough voting 中,detectors 是局部平移不变的,共享参数。
我们把这种局部的,平移不变的 predictors 作为 CNN 网里最后一层的输出,于是便得到了 fully-convolutional regression network ( FCRN )。
Architecture
FCRN 的头几层 layer,计算 text-specific image features。之后上面的网络层,就是 dense regression network。
Single-scale features
本文的 CNN 结构受启发于 VGG-16,里面包含了又小、又多的 filters。但是,在本文的结构中,发现即使没那么多的 filters,结果也一样好,同时也更有效率。网络结构如下:
| layers | params |
|---|---|
| Convolution - ReLU | num_filters: 64 , kernel size: 5×5 , stride: 1 , padding: 2 |
| Max Pooling | kernel size: 2×2 |
| Convolution - ReLU | num_filters: 128 , kernel size: 5×5 , stride: 1 , padding: 2 |
| Max Pooling | kernel size: 2×2 |
| Convolution - ReLU | num_filters: 128 , kernel size: 3×3 , stride: 1 , padding: 1 |
| Convolution - ReLU | num_filters: 128 , kernel size: 3×3 , stride: 1 , padding: 1 |
| Max Pooling | kernel size: 2×2 |
| Convolution - ReLU | num_filters: 256 , kernel size: 3×3 , stride: 1 , padding: 1 |
| Convolution - ReLU | num_filters: 256 , kernel size: 3×3 , stride: 1 , padding: 1 |
| Max Pooling | kernel size: 2×2 |
| Convolution - ReLU | num_filters: 512 , kernel size: 3×3 , stride: 1 , padding: 1 |
| Convolution - ReLU | num_filters: 512 , kernel size: 3×3 , stride: 1 , padding: 1 |
| Convolution - ReLU | num_filters: 512 , kernel size: 5×5 , stride: 1 , padding: 2 |
最后得到输入图像的 feature map。
Class and bounding box prediction
从上面的结构可以看出,由于有 4 个 Max Pooling 层,其最后的 feature map 中,每一个 feature 包含了 16×16 pixels 范围内的特征。每 16×16 像素范围 feature,有 512 个 feature channel: ϕfuv(x) 。
当有了上面的 features:
ϕfuv(x)
之后,现在可以构建 dense text predictors:
ϕux(x)=ϕruv∘ϕf(x)
,这些text predictors 被施以
7
个
5×5
大小的 linear filters:
ϕruv
,每一个要 regressing
7
个数:
(1)物体存在的 confidence:
c
(2)pose parameters:
p=(x−u,y−v,w,h,cosθ,sinθ)
,其中
θ
是 bounding box rotation
因此,对于输入的一张图像: H×W ,我们得到一系列栅格化的 predictors, HΔ×WΔ ,其中的 Δ 即是前面 max pooling 的个数: Δ=24=16 ,图像中栅格化的每一个 predictor 都负责检测 文本中心(word center)是否在当前的栅格内。
YOLO 的操作相似,但其实施的分辨率只有这里的一半。
实际中,本文输入图像的大小为
224×224
,划分出来、栅格化的 predictor 个数为:
14×14
。
Multi-scale detection
因为刚刚 CNN 的 receptive field 太小了,当图像中的文本区域太大时,就会失效。因此,本文对输入图像做多尺度的检测。缩放尺度为 {1,1/2,1/4,1/8} 。
最后将多尺度下的检测的 bounding box 用 Non-maximal suppression(非极大值抑制)进行取舍融合。
即最后的检测结果为,去掉 overlap 大于一个阈值的 score 较小的那个,即所谓的 Non-Maximal Suppression(非极大值抑制)。
Training loss
训练 CNN 网络的 loss 函数,本文如同 YOLO 中所使用的,采用每一个 HΔ×WΔ×7 输出的 squared loss term。
如果某一个栅格 predictor 中没有 ground-truth 文本,这个 loss会忽略掉除了
c
(text/non-text) 以外的所有 params。
Comparison with YOLO
本文的 CNN 结构 FCRN 要比 YOLO 小 30× 倍有余,因为 YOLO 中 90% 参数都在最后的两层全连接层。
同时,由于 YOLO 的全局性(global nature,前面讲过它要采集全局的信息),YOLO 对于不尺度下的 image,都要重新训练,更加加大了 YOLO 模型的大小。实际中,本文的模型只有
44M
的大小,而 YOLO
2G
的大小,使得 YOLO 也更加难以训练,训练也更加的慢(
2×
倍慢于本文的 FCRN)。
Evalutation
评测部分分为以下几个部分:
- 介绍了几个用于评测本文模型的数据集
- 将本文的模型用于 text localisation 任务
- 探讨了在人工生成数据的 pipeline 中,重要的几个环节,以及实验的详细细节
- 将之前的 text localisation 结果用于 end-to-end text spotting,本文的方法在 text localisation 以及 end-to-end text spotting 任务中,都有较大的提升
- 讨论本文的 text localisation 模型在速度上的提升
Datasets
本文是在以下几个 benchmark 个评测 text detection 模型的效果的:ICDAR 2011, ICDAR 2013,以及 Street View Text 数据集。数据集的统计信息如表1:
SynthText in the Wild
这是本文自己生成的人工自然场景文本数据集,包含有 800,000 张训练图像,每一张图像大约有 10 个 word instance,以及标注好的 bounding box。
ICDAR Datasets
因为 ICDAR 2015 与 ICDAR 2013 数据集几乎类似,所以,只用了 ICDAR 2011、2013 的。
Street View Text
简写为 SVT 数据集,SVT 数据集是从 Google 街景图像上抠出来的,同时标注了 bounding boxes。SVT 因为其中包含了较小的文字,以及文字的分辨率较低,所以其任务难度大于 ICDAR 数据集。同时,也不是所有的 text instance 都被标注了。所以在实际中,准确率是被低估了。
Text Localisation Experiments
从两点评估上面的 detection network:
- 比较了单张与多尺度( {1,1/2,1/4,1/8} )图像的 detection 性能
- 当使用更高质量的 proposal 时,提高了 text detection 的结果
Training
FCRN 在本文生成的 SynthText in the Wild 数据集上训练。每一张图像被 resize 到
512×512
的大小。
除了最后一个卷积层,其余的卷积层之后,均使用了 Batch-Normalization 技术。
使用了带 momentum( momentum=0.9 )的 SGD(随机梯度下降)来优化求解。
每次的 batch 为 16 ,weight-decay 设置为 5−4 。
learning-rate 开始设置为 10−4 ,当 loss 陷入停滞期时,减小到 10−5 。
同时由于只有很小的一部分 grid-cells 会带有 text(大约 1%−2% ),因此,本文开始时将非文本的概率误差项的权重,乘以 0.01 ;这个权重会随着训练的进行逐渐增加到 1 。
因为类别的不均衡性,如果没有这样的权重调整机制,所有的可能的得分会渐渐塌缩为
0
。
Inference
从 FCRN 模型中,得到 class probabilities,以及 bounding box 的 prediction。
这些 bounding box 会经过一个阈值 t (最小能接受的 class probabilities),如果大于这个阈值,才会保留。
随后,还要经过 Non-maximal suppression,去除掉重叠太大的 score(此处即 class probability)较小的 bounding box。
本文会给出 t 值取两种值的情况,当 t=0.3 ,bounding box 的 precision 更高,当 t=0.0 时,也就是所有的 bounding box 都接受,可以取得更高的 recall。
这其实是一个 trade-off 的过程。
Evaluation protocol
本文实验中,评价检测效果,用两种 protocol:
(1)ICDAR 中常拿来评价 localisation 结果的 DetEval
(2)PASCAL VOC 中 交除并(IoU),当
IoU≥0.5
,是 positive detection。
Single & multi-scale detection
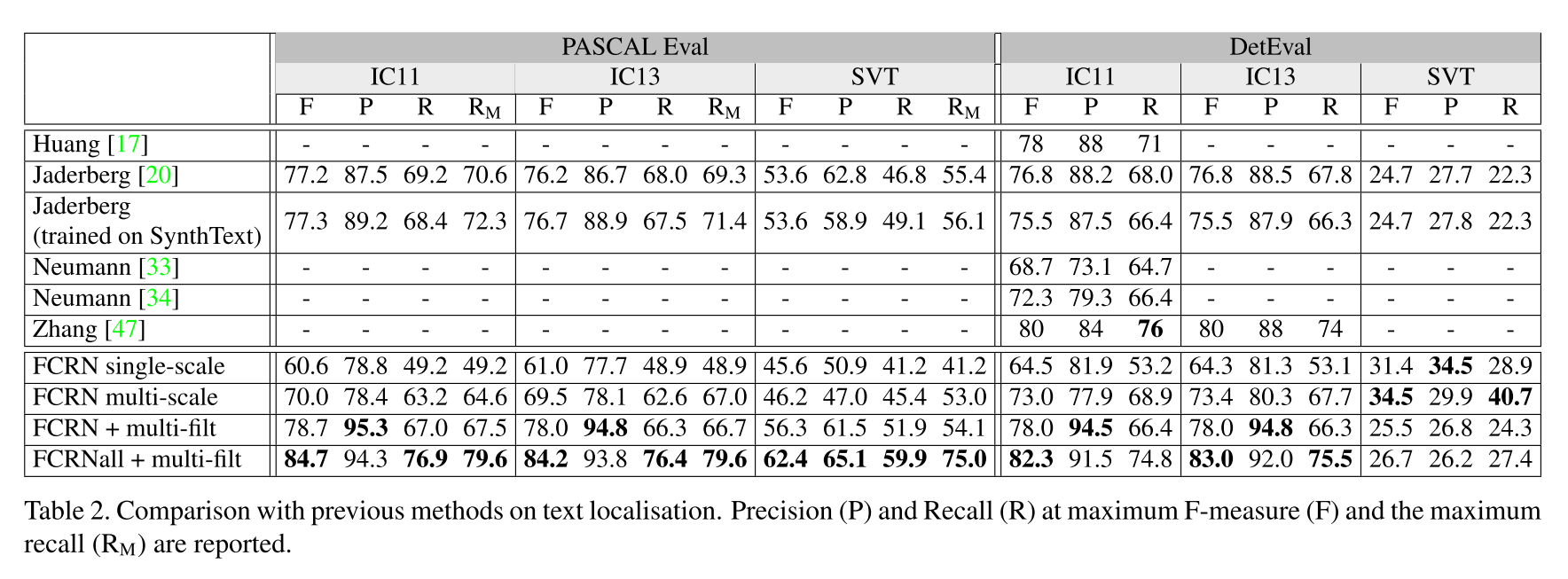
如上面的表2,FCRN 的单尺度、多尺度的检测性能。
尽管 FCRN 单尺度下的 recall 差了 12% ,但其检测精度 F-measure 已经可以与 Neumann 等人的 CVPR 2012: Real-time scene text localization and recognition、ICCV 2013: Scene text localization and recog- nition with oriented stroke detection 相比较了。
FCRN 多尺度的检测,其检测的 recall 比单尺度下的 recall 多了
12%
,同时也超越了 Neumann 等人方法。
Post-processing proposals
为了进一步的提高 FCRN 的检测性能,本文使用 Max Jaderberg 等人在 Reading Text in the Wild with Convolutional Neural Networks 中使用的 post-processing 方法:
- 用一个 random forest classifier 来过滤 text/non-text;
- 使用一个 bounding box regression 的 CNN 结构来进一步提高 bounding box 的准确度;
- 再经过一个 NMS
本文测试这个后处理,用两种模式:
(1)low-recall:NMS 中的阈值
t=0.3
,多尺度检测(Multi-scale FCRN),这种产生的 proposals 少于
30
个。
(2)high-recall :所有的 FCRN 检测得到的 proposals 都接受,这样就有
1000
多个 proposals。
这两种模式的实验结果,用 FCRN+multi-filt、FCRNall+multi-filt 来表示,如表2中的结果。注意到 low-recall在 text detection 上的结果比 state-of-art 的结果都要好,而 high-recall 的在所有数据集上,将 F-measure 提高了 6% 。
下图5 画出了在 ICDAR 2013 上的文本检测的 Precision-Recall 曲线(图中底部的灰色曲线,max-recall =
85.9%
):
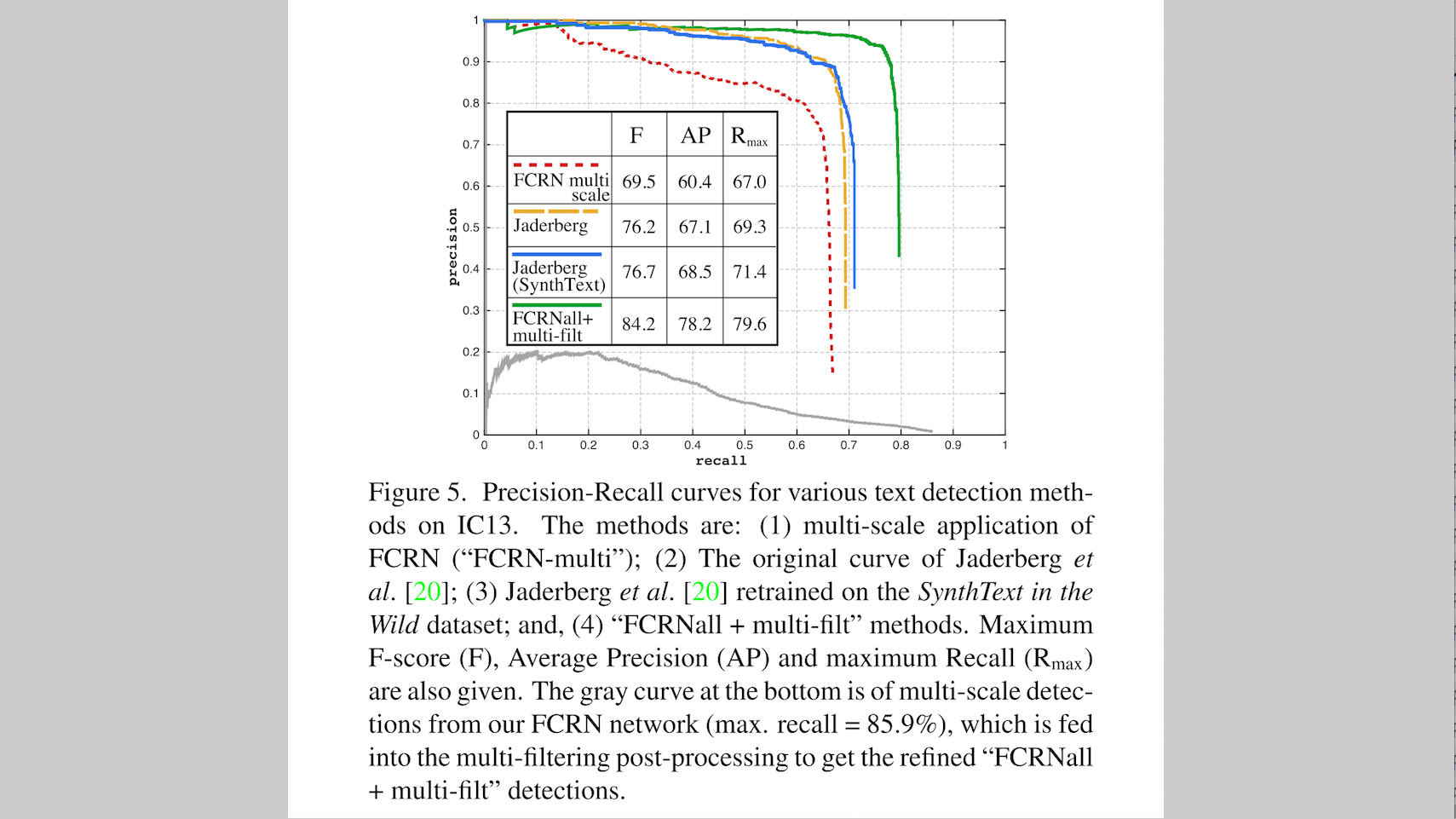
实际上,不同的方法的曲线:
(1)FCRN + multi-scale
(2) Max Jaderberg 中原始的 Precision-Recall 曲线
(3) Max Jaderberg 模型在 SynthText 数据集上重新训练得到的曲线
(4)FCRNall + multi-filt
同时,图中还给出了 Maximum F-score (F) 、 Average Precision (AP) 、 maximum Recall (Rmax)
可以看出,相比较于 Max Jaderberg 的原始的统计数据,最后一个 FCRNall + multi-filt 的方法在 maximum recall(+
10.3%
)、Average Precision (+
11.1%
),提升都很大很大。
Synthetic Dataset Evaluation
这里本文还探究了 Synthetic Data 生成的过程中,不同的生成阶段,对于 localisation 精度的影响。本文随着生成条件的复杂性逐渐增加,生成了三种 Synthetic Data,这里的“复杂性”是指 text 嵌入的位置与一些 constraints,具体如下:
(1)text 随机的嵌入到背景图像中;
(2)将 text 嵌入到局部颜色、纹理的边界内部;
(3)对嵌入的 text 进行 distorted,扭曲,使之符合嵌入的背景区域图像的 depth,即上面所说,需要将 text 进行 warping,嵌到与法向量垂直的面上。
除了上面三种不同的生成条件,其余的条件都是一样的,文字的内容(字典)、背景图像、颜色分布。
下图 Figure 6 展示了 FCRNall-multi-filt 方法在 SVT 数据集上的 text localisation 测试结果。
相比较于(1)随机的将 text 放置到背景图像中,(2)的将 text 嵌入到局部颜色、纹理边界内的生成方法,将Maximum F-score (F + 2.1% )、Average Precision(AP + 3.85% )、maximum Recall( Rmax + 6.8% )
像比较于(2),(3)中将文字进行 distorted 再嵌进背景图像,提升的倒不是很多。从图中可以看出,Maximum F-score(F) 提升了
0.55%
、Average Precision(AP) 提升了
0.75%
、maximum Recall(
Rmax
) 则没有一点提升。
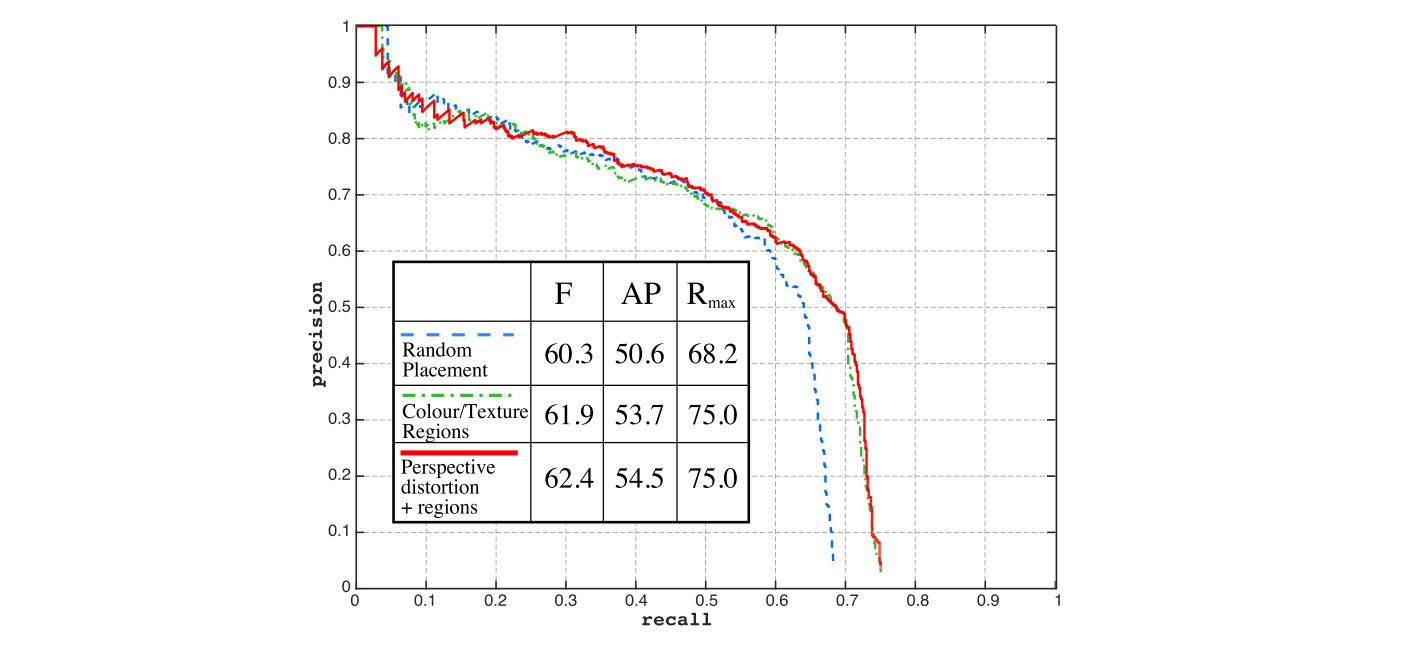
这种原因可能是因为在 SVT 数据集中的的文本区域是 fronto-parallel orientation(平行平面方向的)。
同样的,SVT 数据集中随着生成数据的条件增加,其 text localisation 的表现随之提升。在 ICDAR 数据集中也是相同的,但因为 ICDAR 数据集的难度要远小于 SVT 的数据集,也就是说 ICDAR 的背景图像没有 SVT 数据集的复杂,受益于文本嵌入条件要小,也因此在 ICDAR 中的提升也小于 SVT。
End-to-End Text Spotting Text
text spotting 受限制于 text detection 的精度,目前 state-of-art 的 word recognition 精度超过了 98% ,可参见文章 Synthetic Data and Artificial Neural Networks for Natural Scene Text Recognition。本文在这里使用前面对于 text localisation 的提升的结果,在 recognition 部分,达到 state-of-art 的效果。
这里同样需要约定一个评测标准,这里的 evaluation protocol 是与 Wang 等人的 ICCV 2011: End-to-end scene text recognition 一致:
words 中小于三个字母的忽略;words 中含有非数字、字母的,忽略;positive detection 的
IoU≥0.5
。
下面 Tabel 3 展示了 end-to-end text spotting 的结果,这里使用的方法为 FCRN + multi-filt,以及 FCRNall + multi-filt。
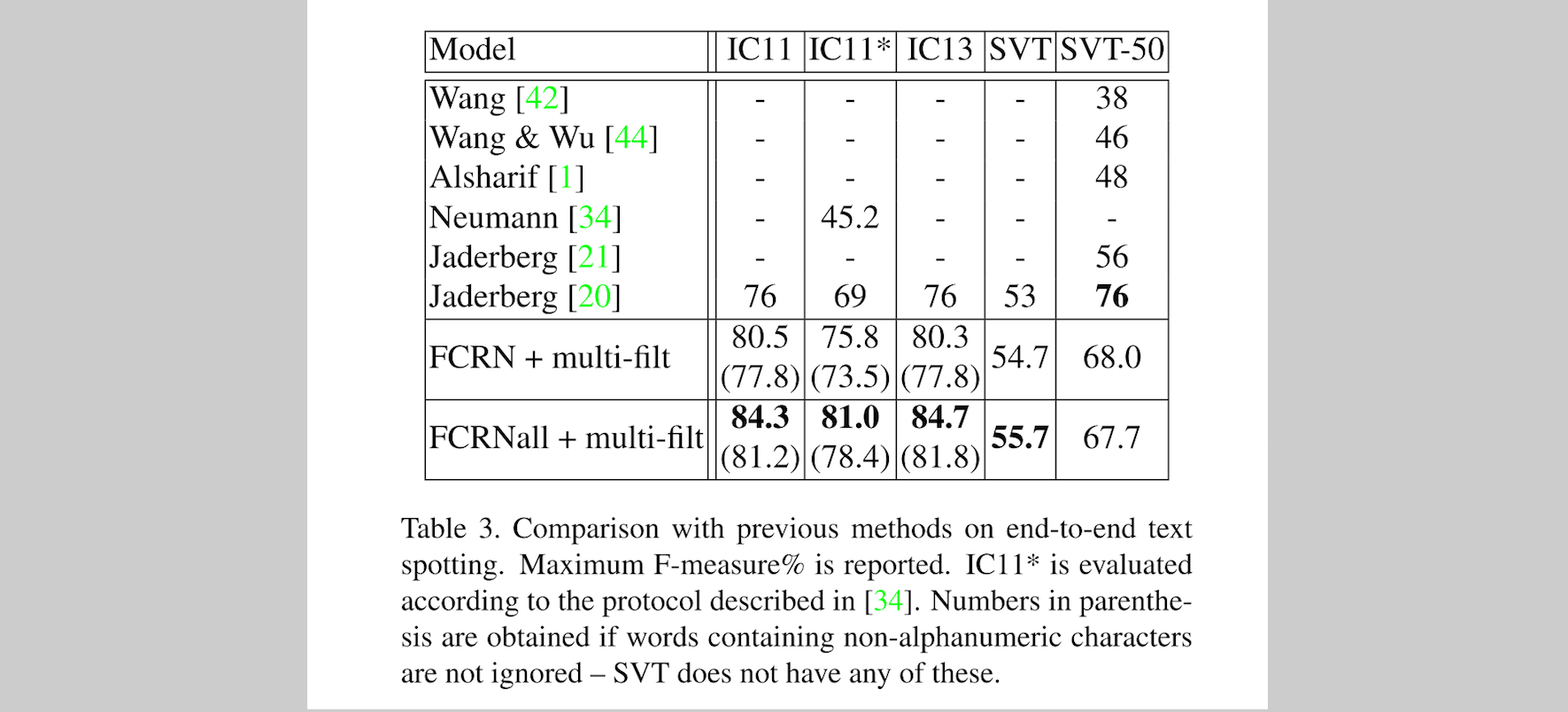
Timings
FCRN 在当只有单尺度,即没有尺度缩放时,每秒可以处理 20 张 512×512 大小的图像(一个 GPU)。
FCRN 当处理有尺度缩放的图像时,每秒可以处理 15 张 512×512 大小的图像(一个 GPU)。
当使用 Reading Text in the Wild with Convolutional Neural Networks 中的高质量的 proposals 时,它需要 3 秒,才能完成一张图像的处理。
因此,本文的方法在 region proposals 中,比 Reading Text in the Wild 提升了
45
倍。
此外,本文的 FCRN + multi-filt 方法,由于只使用高得分的 detections,将需要的 proposals 降低了
10
倍有余, 文献 Reading Text in the Wild with Convolutional Neural Networks 中的 proposals 大约有
200
来个(其实有
2000
个,但经过了一个 random forest 过滤,只剩下
200
个)。
因为本文的 FCRN 中的高得分的 detections,不超过 30 个。
下面 Table 4 是本文的方法与 Reading Text in the Wild with Convolutional Neural Networks 速度的比较。根据变量的不同,速度提升有
3
倍到
23
倍。
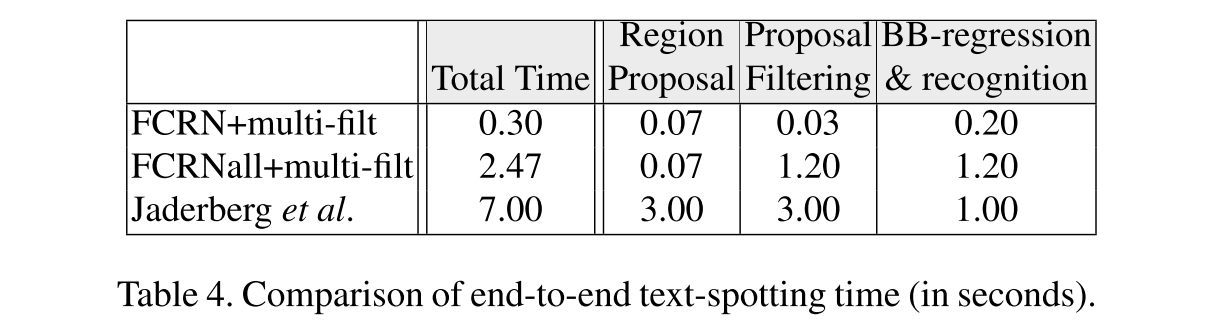

















 2966
2966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









