







 SynthText是一个由858,750张合成图像组成的数据集,用于训练和评估文本检测算法。它包含单词和字符级别的边界框信息,以及对应的文本字符串。数据集旨在帮助开发视觉系统识别真实世界中的文字,具有多种字体、颜色和扭曲效果。
SynthText是一个由858,750张合成图像组成的数据集,用于训练和评估文本检测算法。它包含单词和字符级别的边界框信息,以及对应的文本字符串。数据集旨在帮助开发视觉系统识别真实世界中的文字,具有多种字体、颜色和扭曲效果。
目录
1. 数据整体官方描述
SynthText in the Wild Dataset
-----------------------------
Ankush Gupta, Andrea Vedaldi, and Andrew Zisserman
Visual Geometry Group, University of Oxford, 2016
Data format:
------------
SynthText.zip (size = 42074172 bytes (41GB)) contains 858,750 synthetic
scene-image files (.jpg) split into 200 directories, with
7,266,866 word-instances, and 28,971,487 characters.
Ground-truth annotations are contained in the file "gt.mat" (Matlab format).
The file "gt.mat" contains the following cell-arrays, each of size 1x858750:
1. imnames : names of the image files
2. wordBB : word-level bounding-boxes for each image, represented by
tensors of size 2x4xNWORDS_i, where:
- the first dimension is 2 for x and y respectively,
- the second dimension corresponds to the 4 points
(clockwise, starting from top-left), and
- the third dimension of size NWORDS_i, corresponds to
the number of words in the i_th image.
3. charBB : character-level bounding-boxes,
each represented by a tensor of size 2x4xNCHARS_i
(format is same as wordBB's above)
4. txt : text-strings contained in each image (char array).
Words which belong to the same "instance", i.e.,
those rendered in the same region with the same font, color,
distortion etc., are grouped together; the instance
boundaries are demarcated by the line-feed character (ASCII: 10)
A "word" is any contiguous substring of non-whitespace
characters.
A "character" is defined as any non-whitespace character.
For any questions or comments, contact Ankush Gupta at:
removethisifyouarehuman-ankush@robots.ox.ac.uk2. 数据特点
数据集下文件如下。
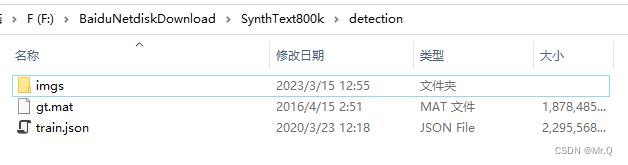
(1)数据集总共有41g,858750张合成图片,jpg格式,这么图片分成200个场景图片(即图片背景不同,其实有202个场景),单词有7,266,866个,字符有28,971,487个;
(2)标注文件时mat格式,读取后保存内容如下。

2.1 imnames
保存图片文件相对路径
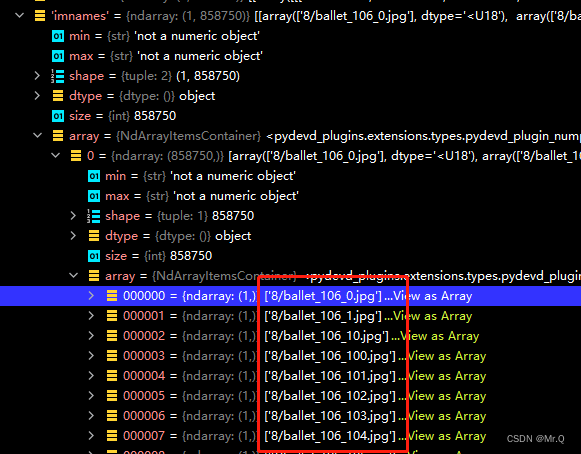
2.2 wordBB:单词级别
每张图片对应其中一个标注tensor,该tensor的size是(2, 4, n_word_i):2是xy坐标;4是表示4个点,左上角开始,顺时针方向;n_word_i是第i张图片中的word个数。
“单词”是指任何非空白的连续字符串。
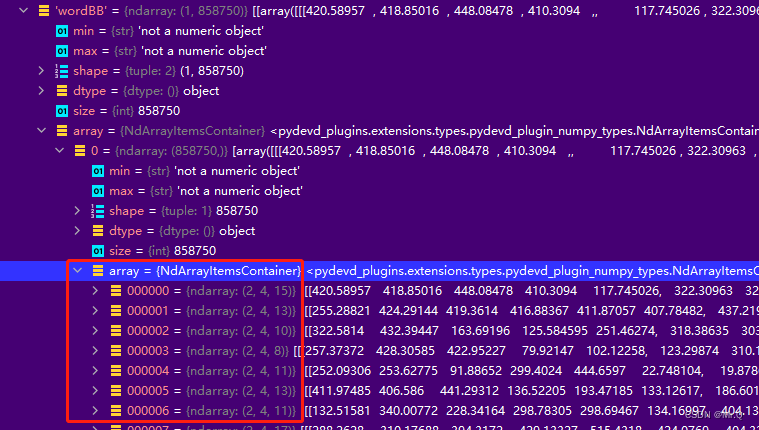
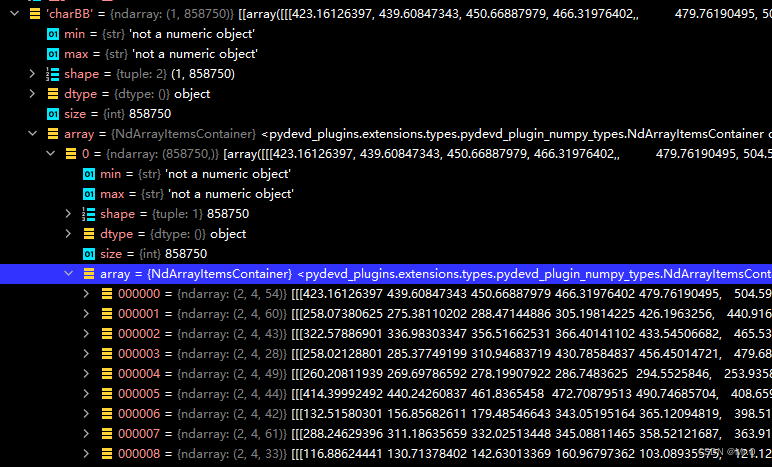
2.3 charBB:字符级别的bbox
size也是(2, 4, n_char_i). 意义同wordBB.
字符是指任何非空白字符。
char_bbox 转labelme格式的json标注文件:
def syntext2json_char_level():
data_dir = r"F:\BaiduNetdiskDownload\SynthText800k\detection"
gt_path = os.path.join(data_dir, "gt.mat")
img_paths = os.path.join(data_dir, "imgs")
gt_mat = loadmat(gt_path)
# word_bboxes = gt_mat['wordBB'][0]
img_names = gt_mat['imnames'][0]
char_bboxes = gt_mat['charBB'][0]
for i in tqdm(range(img_names.size)):
coco_output = {
"version": "3.16.7",
"flags": {},
# "fillColor": [255, 0, 0, 128],
# "lineColor": [0, 255, 0, 128],
"imagePath": {},
"shapes": [],
"imageData": {}}
img_name = img_names[i][0]
img_full_path = os.path.join(img_paths, img_name)
coco_output["imagePath"] = os.path.basename(img_full_path)
coco_output["imageData"] = None
json_full_path = img_full_path.replace(".jpg", ".json")
# print(json_full_path)
cur_img = cv2.imread(img_full_path)
if cur_img is None:
continue
cur_bboxes = char_bboxes[i] # (2,4,n)
if len(cur_bboxes.shape) != 3:
cur_bboxes = np.expand_dims(cur_bboxes, 2)
# rectify_bboxes = np.zeros((cur_bboxes.shape[2], 4, 2))
for j in range(cur_bboxes.shape[2]): # (2,4,15) 多个cnt,多个字符
bbox = cur_bboxes[:, :, j] # (2,4)
pt_list = [[int(bbox[0][m]), int(bbox[1][m])] for m in range(4)] # 记录当前字符
x, y, w, h = cv2.boundingRect(np.array(pt_list))
rect = [[x, y], [x + w, y + h]]
# cv2.rectangle(cur_img, pt_list[0], pt_list[2], (0, 0, 255), 3)
# cv2.namedWindow("img", cv2.WINDOW_NORMAL), cv2.imshow("img", cur_img), cv2.waitKey()
shape_info = {'points': rect,
'group_id': None,
# "fill_color": None,
# "line_color": None,
"label": "loc",
"shape_type": "rectangle",
"flags": {}
}
coco_output["shapes"].append(shape_info)
coco_output["imageHeight"] = cur_img.shape[0]
coco_output["imageWidth"] = cur_img.shape[1]
with open(json_full_path, 'w') as output_json_file:
json.dump(coco_output, output_json_file, indent=4)
output_json_file.close()
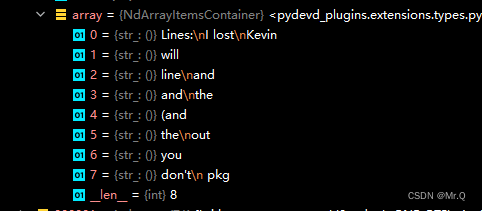
2.4 txt:文本级别
每个图像中包含的文本字符串(字符数组)。
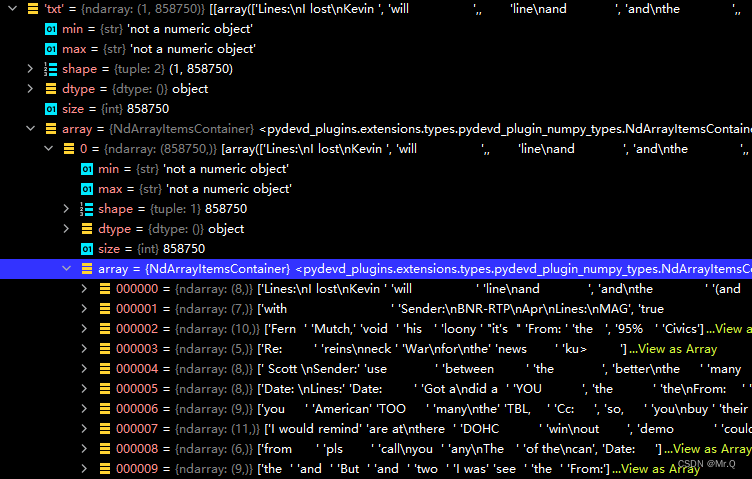
以图片ballet_106_0.jpg为例. 其标注有8个文本,同一个区域、且字体、颜色、扭曲等特征相同的单词被视为一个文本。




















 3126
3126

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











