






实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
- 单向、双向
- 带头、不带头
- 循环、非循环
但在实际应用中最常用的就两种:
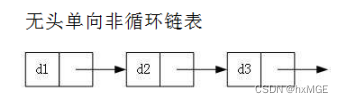
1.无头单向非循环链表
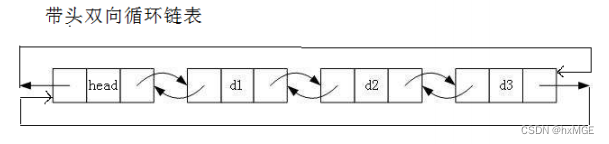
2.带头双向循环链表
- 无头单向非循环链表:结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
- 带头双向循环链表:结构最复杂,一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了
头文件等创建
第一种在前一篇已经介绍过了,这里就来介绍第二种
1.建立头文件
#ifndef DOUBLELIST_H
#define DOUBLELIST_H
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int Data;
typedef struct DoubleLits
{
Data val;
struct DoubleLits* prev;
struct DoubleLits* next;
}DSL;
#endif DOUBLELIST_H
2.相关的接口函数
(1)初始化
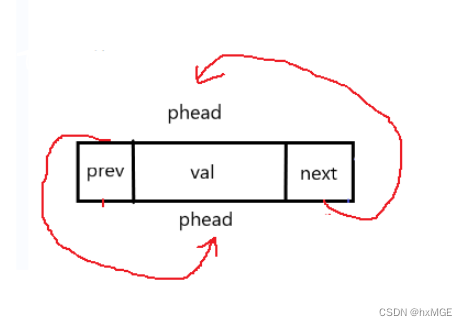
DSL* List_init(void)
{
DSL* temp = (DSL*)malloc(sizeof(DSL));
if(temp == NULL)
{
perror("malloc");
exit(-1) ;
}
temp->next = temp;
temp->prev = temp;
return temp;
}
(2)申请动态内存
DSL* newdstruct(int x)
{
DSL* newList = (DSL*)malloc(sizeof(DSL));
if(newList == NULL)
{
perror("malloc");
exit(-1);
}
newList->val = x;
newList->next = NULL;
newList->prev = NULL;
return newList;
}
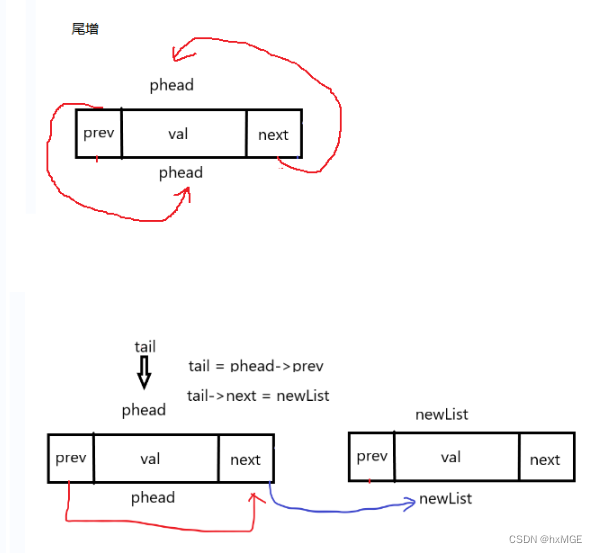
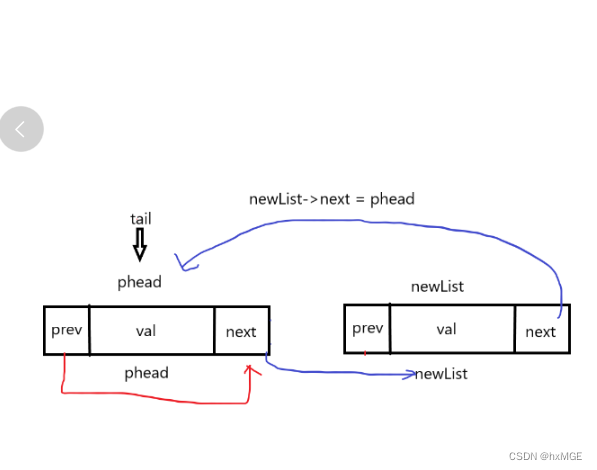
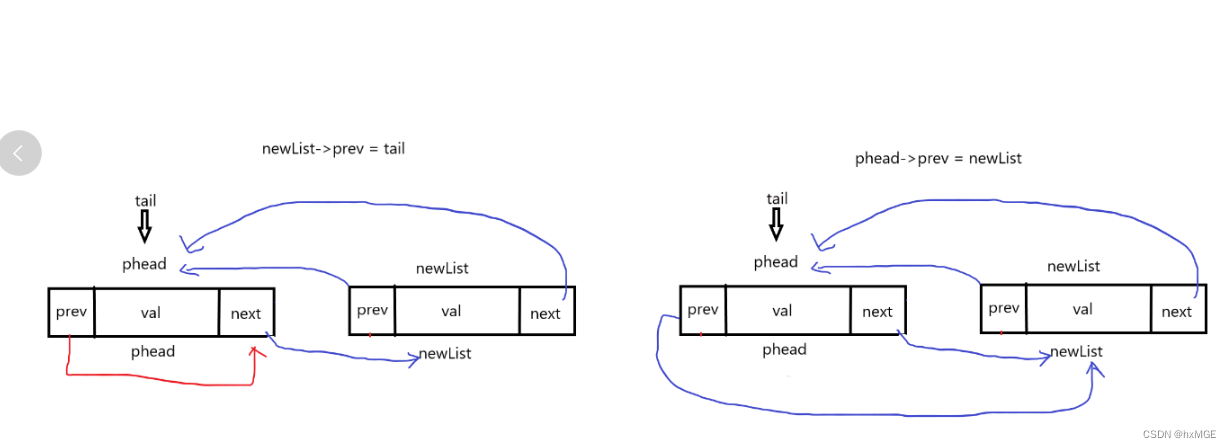
(3)尾增
void ListPushBack(DSL* phead,int x)
{
assert(phead); //最少有一个哨兵位
DSL* newList = newdstruct(x);
DSL* tail = phead->prev;
newList->next = phead;
newList->prev = tail;
tail->next = newList;
phead->prev = newList;
}
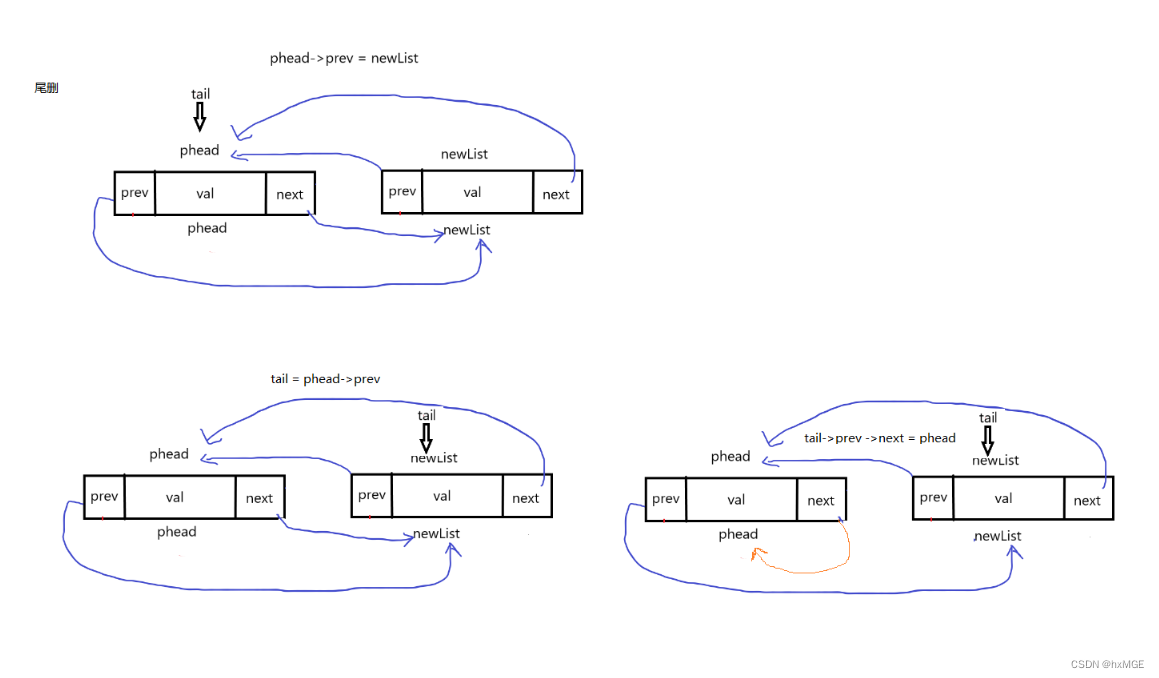
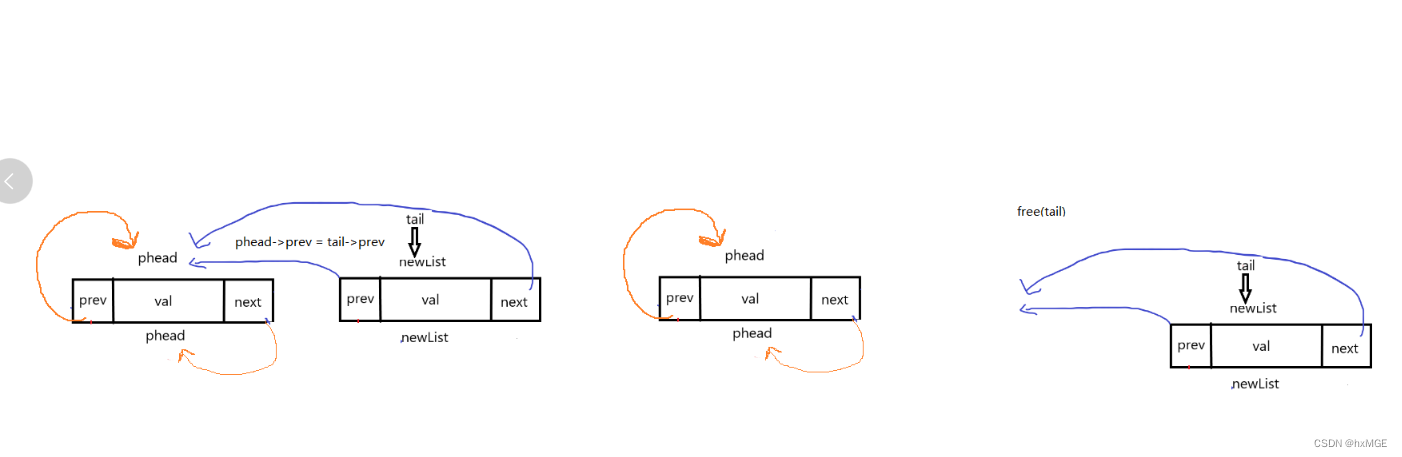
(4)尾删
void ListPopBack(DSL* phead)
{
assert(phead);
assert(phead->next != phead);
DSL* tail = phead->prev;
phead->prev = tail->prev;
tail->prev->next = phead;
free(tail);
//tail = NULL;
}
(5)头增
void ListPushFront(DSL* phead,int x)
{
assert(phead);
DSL* newList = newdstruct(x);
DSL* front = phead->next;
newList->next = front;
newList->prev = phead;
front->prev = newList;
phead->next = newList;
}

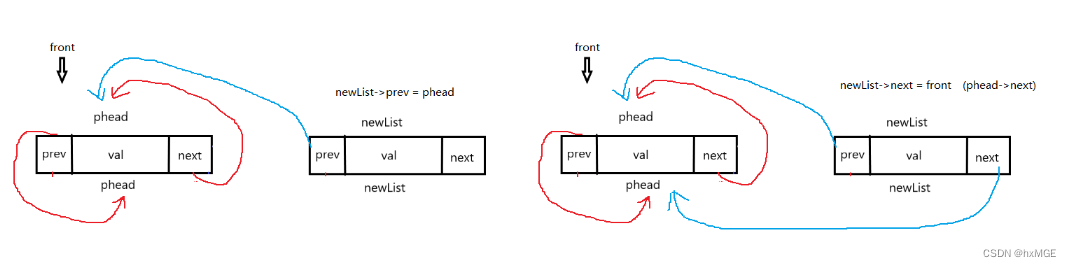

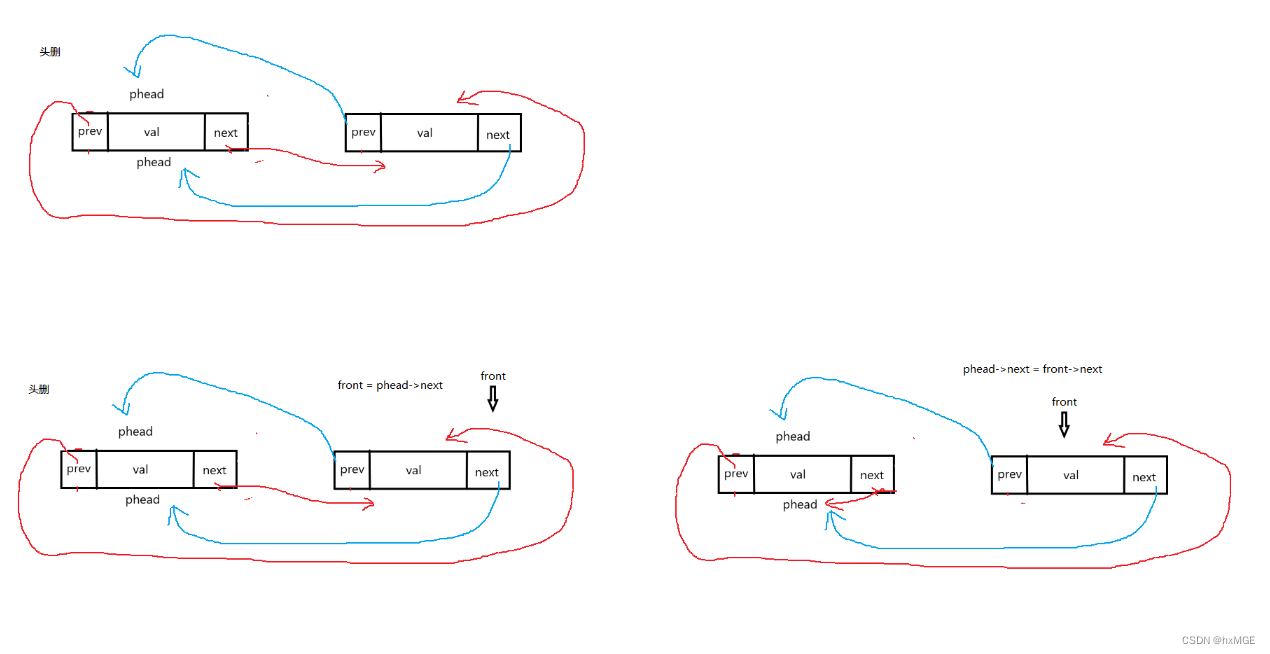
(6)头删
void ListPopFront(DSL* phead)
{
assert(phead);
assert(phead->next != phead);
DSL* front = phead->next;
DSL* tail = front->next;
phead->next = tail;
tail->prev = phead;
free(front);
//front = NULL;
}

(7)打印
void List_print(DSL* ps)
{
assert(phead);
DSL* cur = phead->next;
while(cur != phead)
{
printf("%d-> ",cur->val);
cur = cur->next;
}
printf("NULL\n");
}
(8)查找
DSL* ListFind(DSL* phead,int x)
{
assert(phead);
DSL* cur = phead->next;
while(cur != phead)
{
if(cur->val == x)
return cur;
cur = cur->next;
}
return NULL;
}
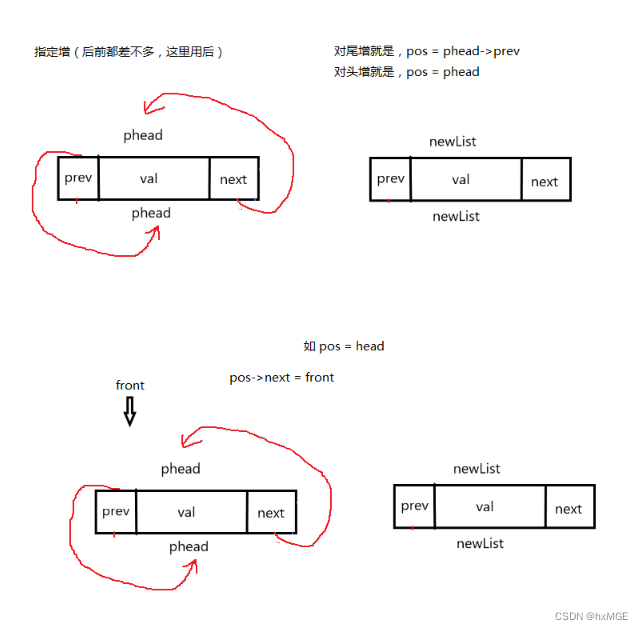
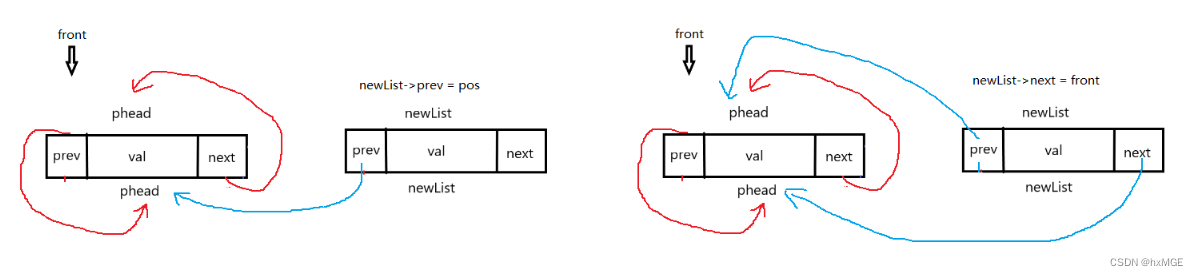
(9)指定增(尾)
void ListInsert(DSL* pos,int x)
{
assert(pos);
assert(pos->next != pos);
DSL* newList = newdstruct(x);
DSL* tail = pos->next;
newList->prev = pos;
newList->next = tail;
pos->next = newList;
tail->prev = newList;
}
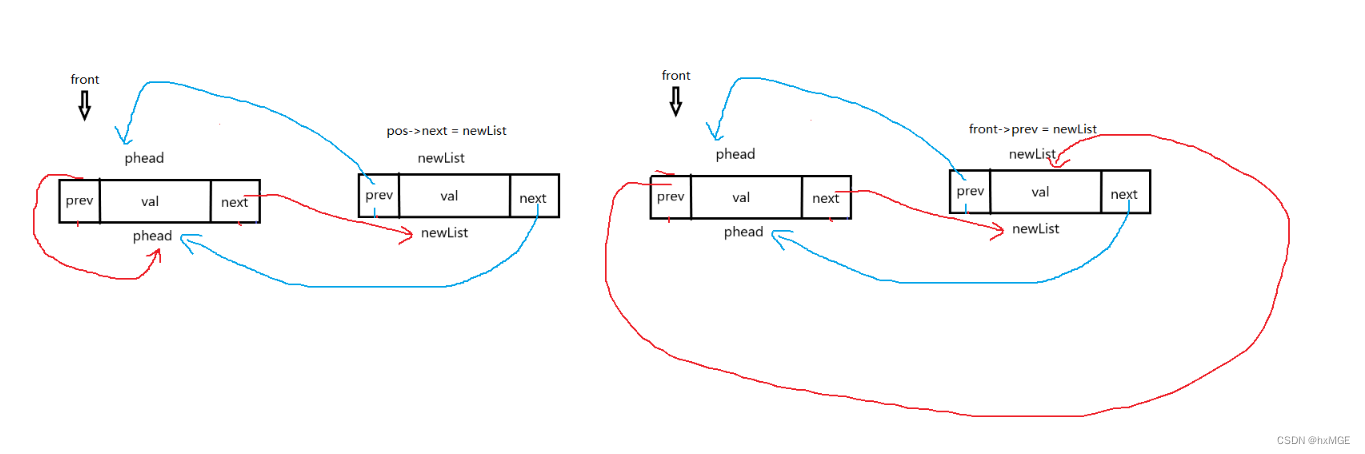
(10)指定删
void ListErase(DSL* pos)
{
assert(pos);
assert(pos->next != pos);
DSL* posPrev = pos->prev;
DSL* posNext = pos->next;
posNext->prev = posPrev;
posPrev->next = posNext;
free(pos);
//pos = NULL
}
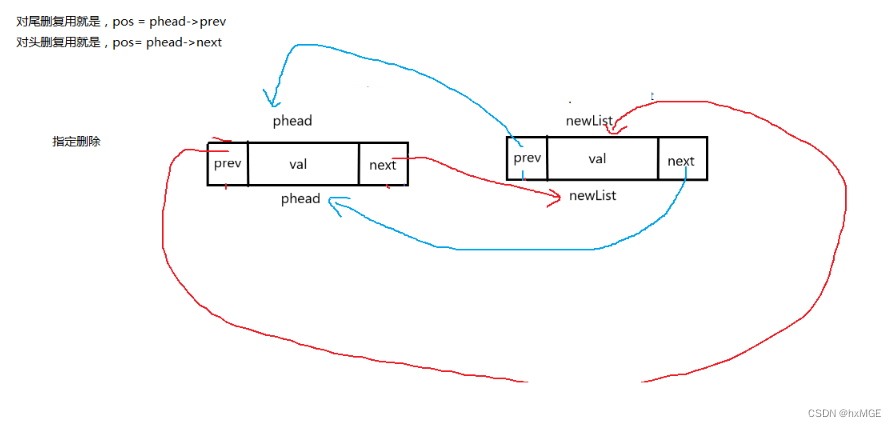
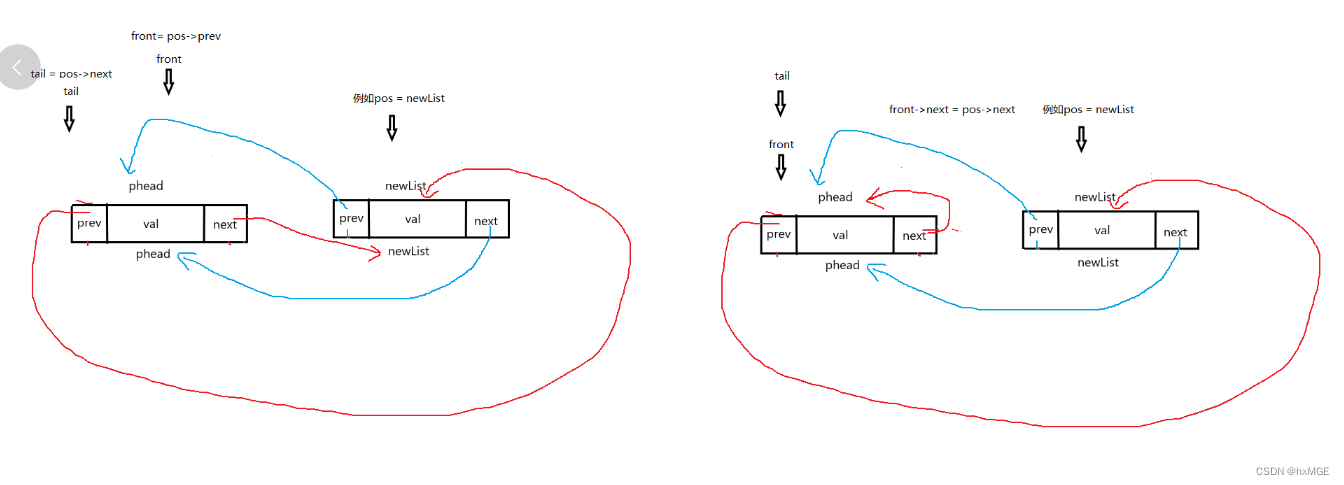
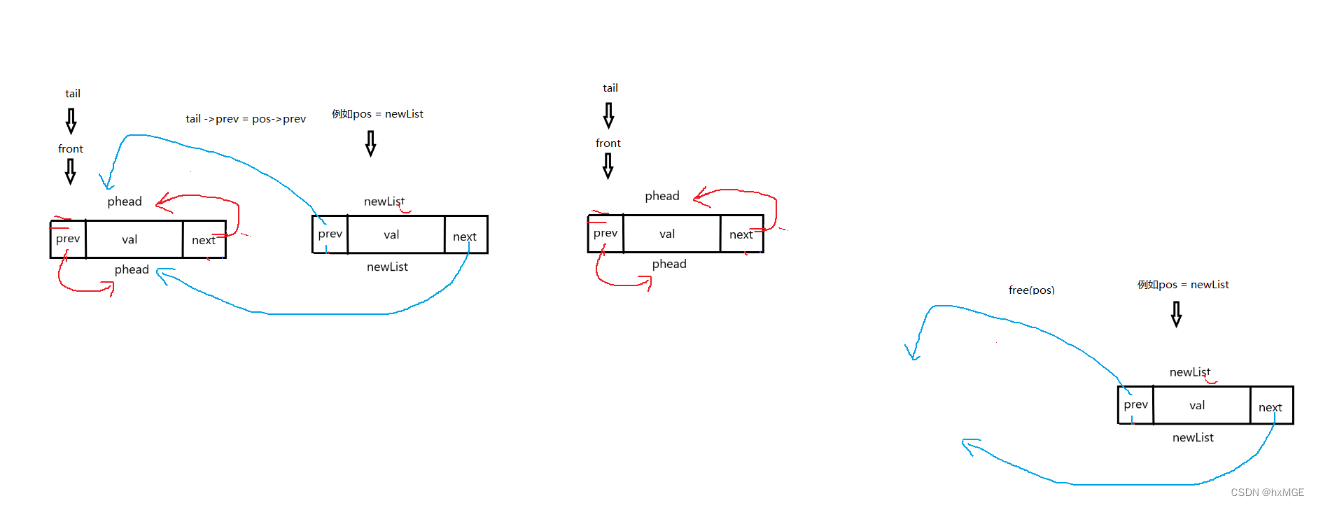
(11)释放
void Distroy(DSL* phead)
{
assert(phead);
DSL* cur = phead->next;
DSL* del = NULL;
while(cur != phead)
{
del = cur;
cur = cur->next;
free(del);
}
free(phead);
要在外面置空,这里只是形参,是实参的临时拷贝
}
编写完后的头文件
#ifndef DOUBLELIST_H
#define DOUBLELIST_H
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int Data;
typedef struct DoubleLits
{
Data val;
struct DoubleLits* prev;
struct DoubleLits* next;
}DSL;
//初始化
DSL* List_init(DSL* ps);
//打印
void List_print(DSL* ps);
//尾增
void ListPushBack(DSL* phead,int x);
//尾删
void ListPopBack(DSL* phead);
//头增
void ListPushFront(DSL* phead,int x);
//头删
void ListPopFront(DSL* phead);
//查找
DSL* ListFind(DSL* phead,int x);
//指定增
void ListInsert(DSL* pos,int x);
//指定删
void ListErase(DSL* pos);
//释放
void Distroy(DSL* phead);
#endif DOUBLELIST_H
小结:
1.双向循环带哨兵位的双链表就不用传递二级指针了,因为会先申请一个哨兵位只是没存任何数据,但是释放时可以用二级指针,用于给实参置NULL,也可以使用一级指针,在外部调用下手动置NULL
2.虽然双向链表结构看起来复杂,但操作反而简单了,指定删和指定增函数就可以完成所有增删的功能无论是前置删除还是后置删除,但是注意不能把哨兵位删除
一些函数的复用
1.查找+指定删
DSL* pos = NULL;
DSL* data = NULL;
data = List_init(void);
ListPushBack(data,2);
while(pos = ListFind(data,2))
{
ListErase(pos);
}
2.指定增复用 (头增 尾增)
ListInsert(DSL* pos,int x)
void ListPushFront(DSL* phead,int x)
{
ListInsert(phead,1);
}
void ListPushBack(DSL* phead,int x)
{
ListInsert(phead->prev,2);
}
3.指定删复用 (头删 尾删)
ListErase(DSL* pos)
void ListPopBack(DSL* phead)
{
assert(phead);
assert(phead->next != phead);
ListErase(phead->prev);
}
void ListPopFront(DSL* phead)
{
assert(phead);
assert(phead->next != phead);
ListErase(phead->next);
}
链表与顺序表的总结
顺序表
优点:
1.支持随机访问(下标访问),对需要随机访问结构支持的算法可以很好的适用
2.CPU缓存命中率更高(顺序表连续的优势)
缺点:
1.头部中部插入删除时间效率低O(N)
2.为了避免连续增容,一般按倍数去增,用不完可能存在空间浪费
链表
优点:
1.任意位置插入删除效率高O(1)
2.按需申请释放空间
缺点:
1.不支持访问,意味着一些排序、查找(如二分查找)在这种结构不适用
2.链表存储一个值,同时需要存储指针来链接















 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









