






查看Pytorch版本
print(torch.__version__)查看cuda版本
print(torch.version.cuda)查看cudnn版本
print(torch.backends.cudnn.version())查看GPU型号
print(torch.cuda.get_device_name(0))
Pytorch是否可以使用计算机的GPU
torch.cuda.is_available()
True就是可以被使用

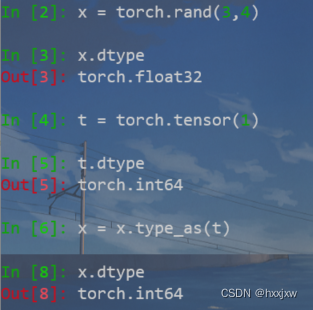
tensor 数据类型转换
torch.long() #将tensor转换为long类型 torch.half() #将tensor转换为半精度浮点类型 torch.int() #将该tensor转换为int类型 torch.double() #将该tensor转换为double类型 torch.float() #将该tensor转换为float类型 torch.char() #将该tensor转换为char类型 torch.byte() #将该tensor转换为byte类型 torch.short() #将该tensor转换为short类型将tensor转换为另一个tensor的type数据类型
x = x.type_as(t1)
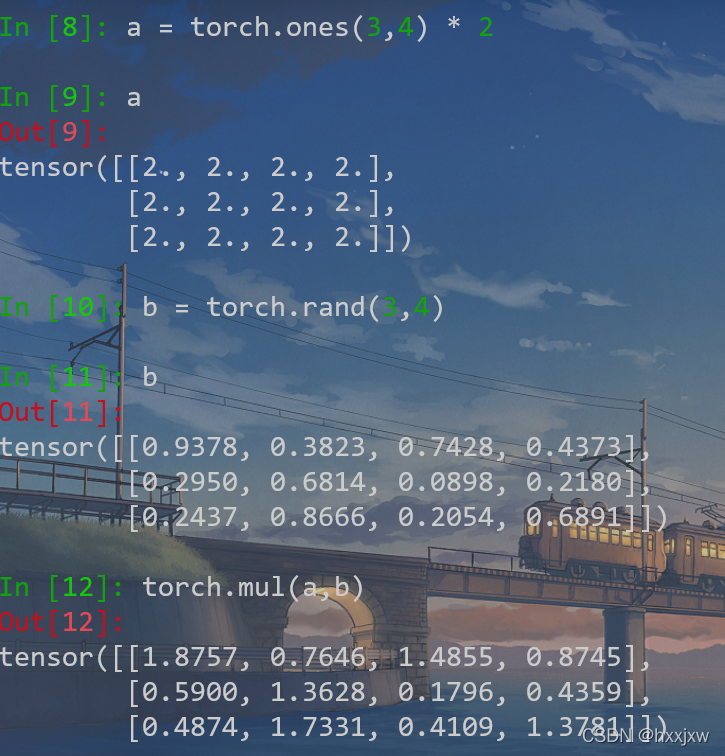
Pytorch加减乘除
- a + b = torch.add(a, b) / 直接a+b
- a - b = torch.sub(a, b)
- a * b = torch.mul(a, b)
- a / b = torch.div(a, b)
torch.mul(a, b)是矩阵a和b对应元素相乘,写作*
也可以用于tensor乘以常量
可以做broadcast



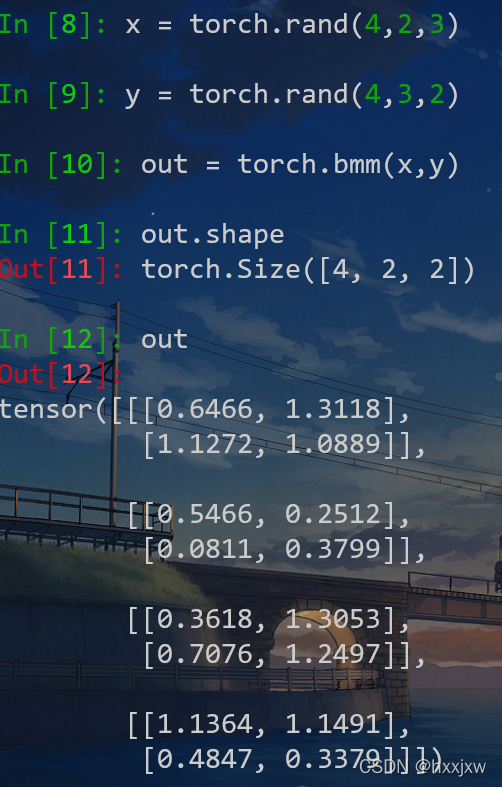
Pytorch矩阵相乘(torch.mm, torch.matmul, torch.bmm)
矩阵相乘是,比如a的维度是(1, 2),b的维度是(2, 3),a*b返回的就是(1, 3)的矩阵
torch.mm(a, b) #只能处理2维(2D),其他维度要用matmul
torch.matmul(a, b)
a @ b = torch.matmul(a, b)
torch.bmm()
矩阵对应元素相乘(带有batch的)。bmm就是有batch的mm,不能广播
计算两个tensor的矩阵乘法,torch.bmm(a,b),tensor a 的size为(b,h,w),tensor b的size为(b,w,h),注意两个tensor的维度必须为3.
torch.bmm()与torch.matmul()
都是矩阵相乘,但是bmm的tensor必须是3D的,matmul没有强制规定
当操作的是3D tensor时,bmm与matmul等同
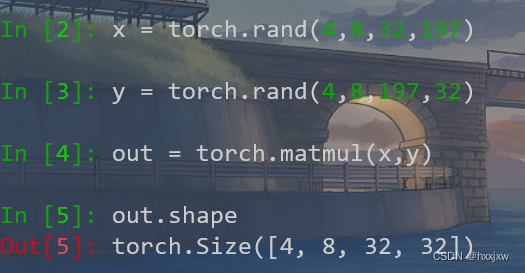
torch.matmul()是适用性最广的,能处理batch、广播的矩阵,推荐使用它
torch.matmul可以进行4维的tensor相乘, 甚至是5维
即只要前面几维值相同的,都可以忽略
总结:
二维矩阵乘法用
torch.mm,batch二维矩阵(即三维)用torch.bmm,batch、广播用torch.matmul
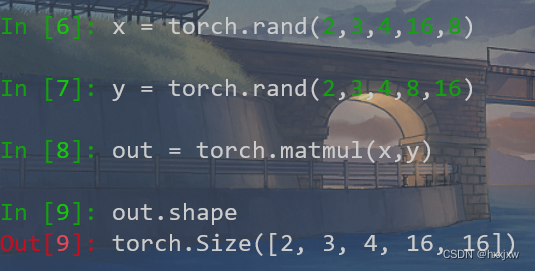
torch.sparse 稀疏矩阵
稀疏矩阵: 矩阵中非零元素的个数远远小于矩阵元素的总数,并且非零元素的分布没有规律,则称该矩阵为稀疏矩阵(sparse matrix)
如果矩阵是稀疏矩阵,没法直接用torch.mm相乘
torch.sparse.mm(a,b)用法上类似torch.mm(a,b),但a是稀疏矩阵,b是普通矩阵或稀疏矩阵
这是一个空的稀疏矩阵
稀疏矩阵的定义,要求指出稀疏矩阵中非零元素的位置和值
import torch indices = torch.LongTensor([[0,0], [1,1], [2,2]])#稀疏矩阵中非零元素的坐标 indices = indices.t() #一定要转置,因为后面sparse.FloatTensor的第一个参数就是该变量,要求是一个含有两个元素的列表,每个元素也是一个列表。第一个子列表是非零元素所在的行,第二个子列表是非零元素所在的列。 print(indices) values = torch.FloatTensor([3,4,5]) #即表示在[0,0],[1,1],[2,2]的位置的值分别是3,4,5 mat = torch.sparse.FloatTensor(indices,values,[4,4]) print(mat) print(mat.to_dense())
to_dense就是显示稠密矩阵的形状
to_sparse由正常矩阵转为稠密矩阵
获得稀疏矩阵的indices
x = mat.coalesce().indices() print(x)至于为啥要coalesce我也不晓得,反正就记住呗
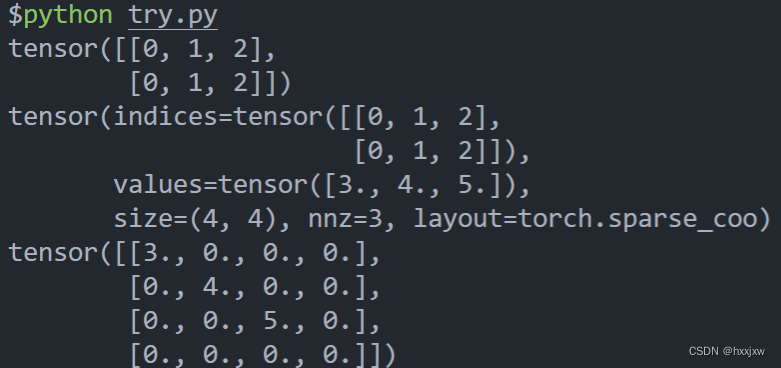
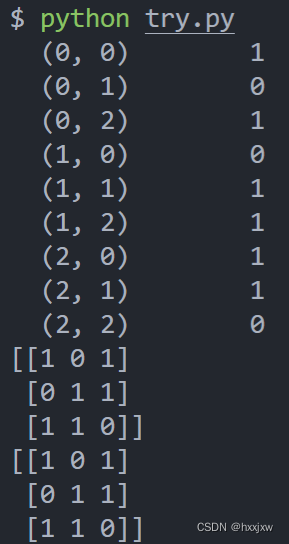
稀疏矩阵切片
稀疏矩阵切片不能使用coo_matrix(三元组),可以将矩阵转化为csr_matrix,转化方式很简单


torch.spmm()/torch.sparse.mm() 稀疏矩阵相乘
稀疏矩阵: 矩阵中非零元素的个数远远小于矩阵元素的总数,并且非零元素的分布没有规律,则称该矩阵为稀疏矩阵(sparse matrix)
如果矩阵是稀疏矩阵,没法直接用torch.mm相乘
torch.sparse.mm(a,b)用法上类似torch.mm(a,b),但a是稀疏矩阵,b是普通矩阵或稀疏矩阵
python3.7是torch.spmm()和torch.sparse.mm()都有

torch.randn() 和 torch.rand()
torch.randn()是标准正态分布
torch.rand()是均匀分布
torch.rand()生成的范围是(0,1) 。 torch.randn()可能会大于1,只要保证均值为0,方差为1
a = torch.randn(2,3)
生成一个2行3列的tensor
正态分布均值是0,方差是1
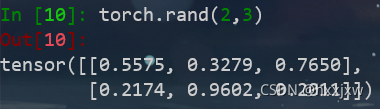
torch.rand()
返回区间 [ 0,1) 上均匀分布的随机数填充的张量。
参数是shape
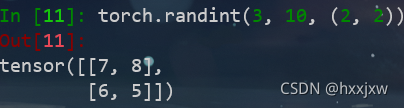
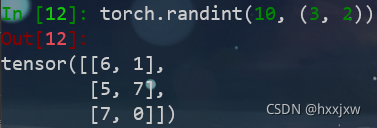
torch.randint()
torch.randint(a,b,size)返回在 [ a , b) 之间均匀生成的随机整数填充的张量。
a可以没有,默认是0
x.random_()
或者
产生的是整数


tensor.view()
reshape比view好, 建议用reshape
view()是pytorch的,相当于numpy的resize()
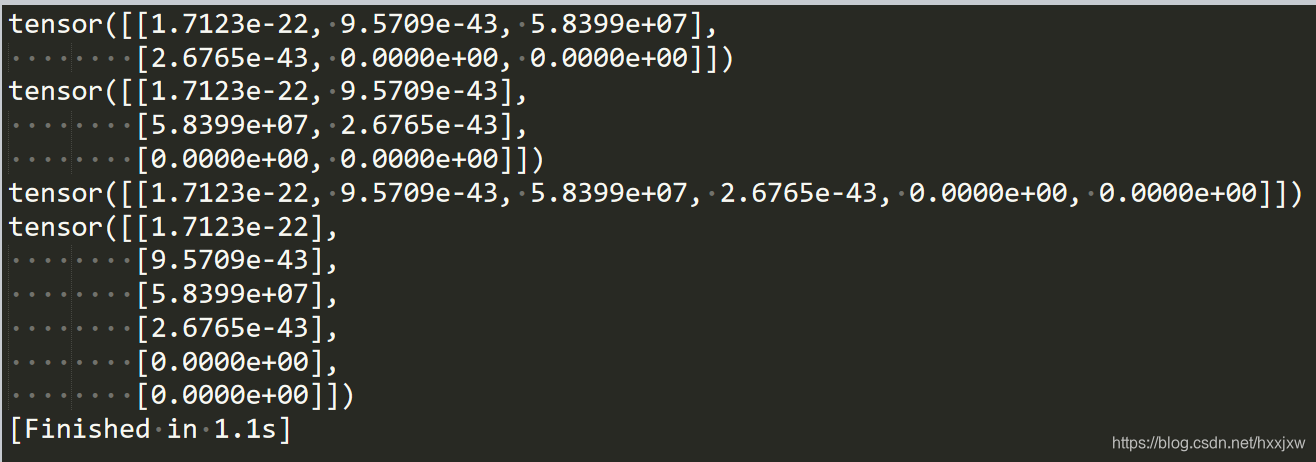
x = x.view(a,b)
表示将x resize成 a*b的维度
假设原来x的维度是[q,h],那么必须q*h = a*b
-1表示维数自动判断,比如原来x是4*5维度,x=x.view(10,-1), 那么此时-1就是2
import torch a = torch.Tensor(2,3) print(a) print(a.view(3,2)) print(a.view(1,6)) print(a.view(6,1))
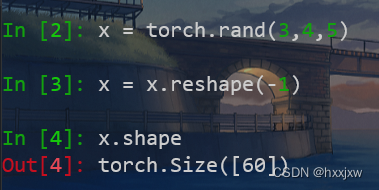
x = x.view(x.size(0), -1)
x.size(0)就是x的第一维,通常是batch_size
如x是[512,3,28,28], x.size(0)就是512
torch.reshape() / tensor.reshape()
修改的shape必须满足原来的tensor和reshape的tensor元素个数相等
tensor.shape
view能做的reshape都能做
相比torch.view,torch.reshape可以自动处理输入张量不连续的情况。
https://blog.csdn.net/weixin_52525925/article/details/114850295

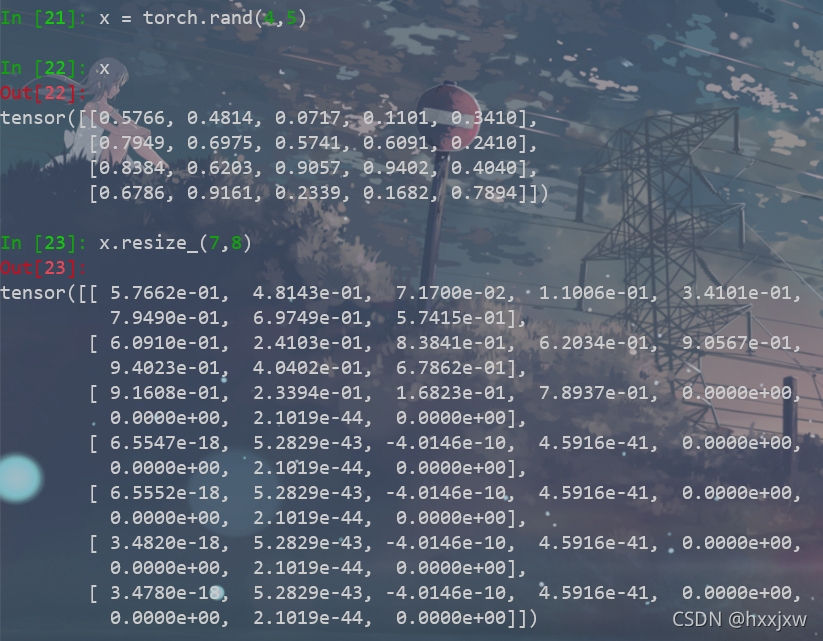
tensor.resize_()
记得最后的下划线
resize与view不同,它可以改变tensor的size
如果新尺寸超过了原尺寸,会自动分配新的内存空间;如果新尺寸小于原尺寸,则之前的数据依旧会保存

ToPILImage()
将tensor转换成图片
from torchvision.transforms import ToPILImage #data 是 [3, 32, 32] 的tensor show = ToPILImage() img = show(data) img.show()
下划线_ 函数
函数名后面带下划线_的函数会修改Tensor本身
例如x.add_(y) 会改变x,但x.add(y)会返回一个新的Tensor,而x不变
torch.nn.MSELoss()
Mean Square Error 损失函数,即均方损失函数
若遇到torch.nn.MSELoss(reduction='sum'),很多的 loss 函数都有 size_average 和 reduce 两个布尔类型的参数。因为一般损失函数都是直接计算 batch 的数据,因此返回的 loss 结果都是维度为 (batch_size, ) 的向量。
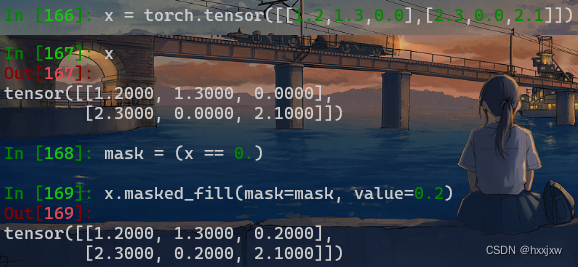
tensor.masked_fill() 将tensor中等于某个值的位置用另一个值填充
掩码操作
tensor.masked_fill(mask, value)masked_fill方法有两个参数,maske和value,mask是一个pytorch张量(Tensor),元素是布尔值,value是要填充的值,填充规则是mask中取值为True位置对应于self的相应位置用value填充。
这里就是,将logits按照mask进行填充,在mask为True的位置,给logits的这个位置填充上float('-inf')
将x中0.0的值填充为0.2

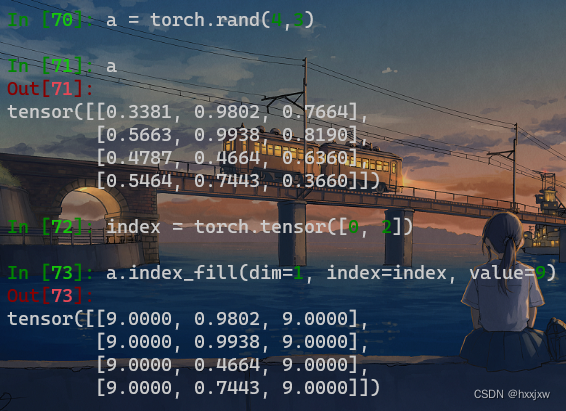
tensor.index_fill() 通过索引填充值
Tensor.index_fill_(dim, index, value)通过按index中给定的顺序 选择索引,用val值填充 自己(自张量)的元素。
dim(int)–索引所依据的维度
index(LongTensor)–要填充的自张量的索引
val(浮点数)–要填充的值
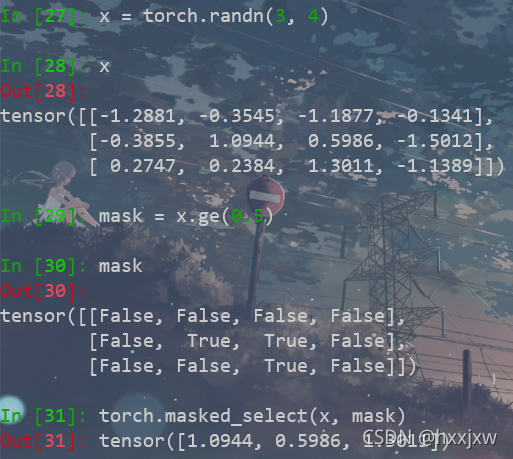
torch.masked_select() 通过mask选取tensor
torch.masked_select(input, mask, *, out=None)返回的是一维tensor
但是只能是逐元素的,不能作用与一行/一列
例如要选择x中大于0.5的元素
在训练阶段,损失函数通常需要进行mask操作,因为一个batch中句子的长度通常是不一样的,一个batch中不足长度的位置需要进行填充(pad)补0,最后生成句子计算loss时需要忽略那些原本是pad的位置的值,即只保留mask中值为1位置的值,忽略值为0位置的值

nn.Embedding
Pytorch之经典神经网络RNN(三) —— LSTM(simple data) (nn.Embedding)_hxxjxw的博客-CSDN博客
contiguous()
返回一个内存连续的有相同数据的tensor,如果原tensor内存连续,则返回原tensor;
contiguous一般与transpose,permute,view搭配使用:使用transpose或permute进行维度变换后,调用contiguous,然后方可使用view对维度进行变形(如:tensor_var.contiguous().view() )
x = torch.Tensor(2,3) y = x.permute(1,0) # permute:二维tensor的维度变换,此处功能相当于转置transpose y.view(-1) # 报错,view使用前需调用contiguous()函数 y = x.permute(1,0).contiguous() y.view(-1) # OK具体原因有两种说法:
1 transpose、permute等维度变换操作后,tensor在内存中不再是连续存储的,而view操作要求tensor的内存连续存储,所以需要contiguous来返回一个contiguous copy;
2 维度变换后的变量是之前变量的浅拷贝,指向同一区域,即view操作会连带原来的变量一同变形,这是不合法的,所以也会报错;---- 这个解释有部分道理,也即contiguous返回了tensor的深拷贝contiguous copy数据;
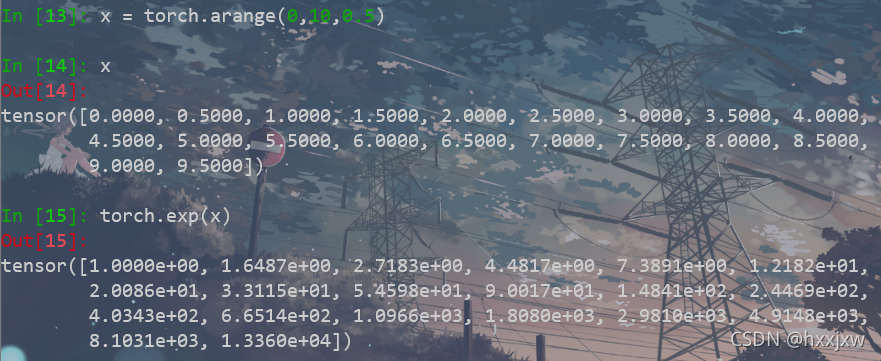
torch.arange() & torch.range()
torch.range(start=1, end=6)的结果是会包含end的,而torch.arange(start=1, end=6)的结果并不包含end。两者创建的
tensor的类型也不一样。>>> y=torch.range(1,6) >>> y tensor([1., 2., 3., 4., 5., 6.]) >>> y.dtype torch.float32 >>> z=torch.arange(1,6) >>> z tensor([1, 2, 3, 4, 5]) >>> z.dtype torch.int64
long()
tensor.long() 将tensor投射为long类型
tensor.repeat() 复制tensor
PyTorch 中常用于张量数据复制操作有 expand 和 repeat
repeat 返回的张量在内存中是连续的
x.repeat(2,3,4) 表示将tensor x在0维上复制2次,在1维上复制3次,在2维上复制4次
如果x是(m,n)两维的,也可以x.repeat(2,1,1) 可以扩充维度
>>> import torch >>> a = torch.randn(33, 55) >>> a.size() torch.Size([33, 55]) >>> >>> # 下面开始尝试 repeat 函数在不同参数情况下的效果 >>> a.repeat(1,1).size() # 在0维复制1次, 在1维复制1次 torch.Size([33, 55]) >>> >>> a.repeat(2,1).size() # 在0维复制2次, 在1维复制1次 torch.Size([66, 55]) >>> >>> a.repeat(1,2).size() # 在0维复制1次, 在1维复制2次 torch.Size([33, 110]) >>> >>> a.repeat(1,1,1).size() # 在0维复制1次, 在1维复制1次, 在2维复制1次 torch.Size([1, 33, 55]) >>> >>> a.repeat(2,1,1).size() # 在0维复制2次, 在1维复制1次, 在2维复制1次 torch.Size([2, 33, 55]) >>> >>> a.repeat(1,2,1).size() # 在0维复制1次, 在1维复制2次, 在2维复制1次 torch.Size([1, 66, 55]) >>> >>> a.repeat(1,1,2).size() # 在0维复制1次, 在1维复制1次, 在2维复制2次 torch.Size([1, 33, 110]) >>> >>> a.repeat(1,1,1,1).size() # 在0维复制1次, 在1维复制1次, 在2维复制1次, 在3维复制1次 torch.Size([1, 1, 33, 55])
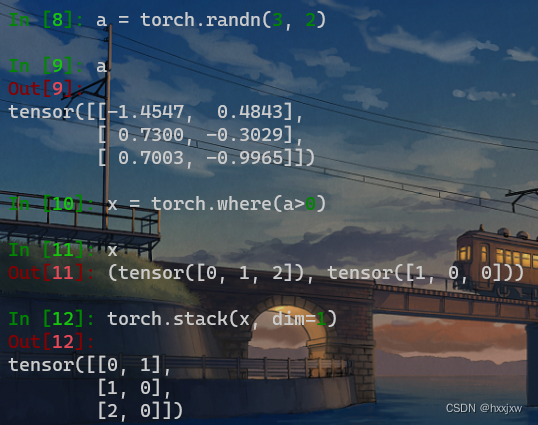
torch.where()
torch.where(condition, x, y)
根据条件,返回从x,y中选择元素所组成的张量。如果满足条件,则返回x中元素。若不满足,返回y中元素。
注意这和np.where()不同的地方在于,np可以x = np.where(x>0, 0, 1)
这里不行, 填充的不能是单个数值,可以
zeros = torch.zeros()
ones = torch.ones()
x = torch.where(x>0, zeros, ones)
也可以用来获取满足条件的元素的位置
得到的是x和y分着的,stack一下就好了
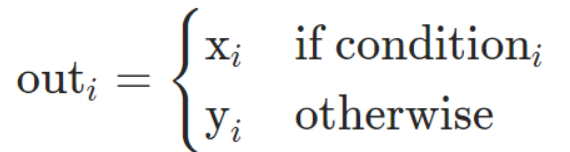

detach()
detach的作用是将variable参数从网络中隔离开,不参与参数更新。
切断反向传播
# y=A(x), z=B(y) 求B中参数的梯度,不求A中参数的梯度 y = A(x) z = B(y.detach()) z.backward()
torch.unsqueeze() 增加维度
x = torch.unsqueeze(x,0) 在x的第0维增加一个维度以前x是(c,h,w), 现在是(1,c,h,w)
torch.squeeze() 压缩维度
x = torch.squeeze(x)将x中所有为1的维度去掉
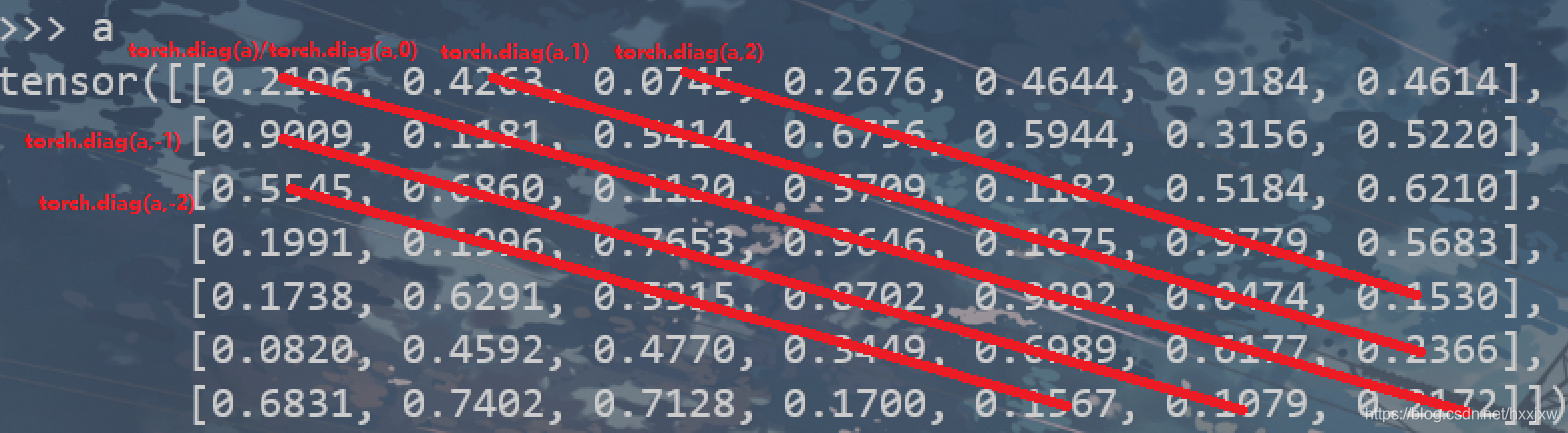
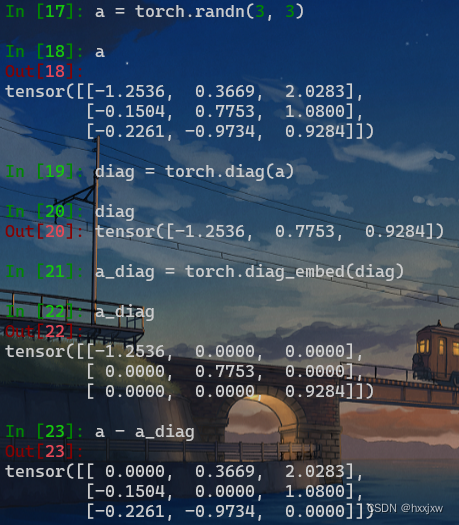
torch.diag()
如果输入是一个向量(1D 张量),则返回一个以input为对角线元素的2D方阵
如果输入是一个矩阵(2D 张量),则返回该矩阵的对角线元素(1D tensor)
>>> a = torch.randn(3) >>> a 1.0480 -2.3405 -1.1138 [torch.FloatTensor of size 3] >>> torch.diag(a) 1.0480 0.0000 0.0000 0.0000 -2.3405 0.0000 0.0000 0.0000 -1.1138 [torch.FloatTensor of size 3x3] >>> torch.diag(a, 1) 0.0000 1.0480 0.0000 0.0000 0.0000 0.0000 -2.3405 0.0000 0.0000 0.0000 0.0000 -1.1138 0.0000 0.0000 0.0000 0.0000 [torch.FloatTensor of size 4x4]
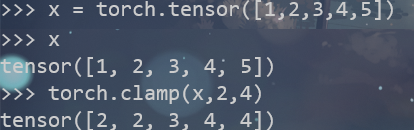
torch.clamp() 截断
用来“截断”tensor,使每个元素都保持在min~max范围内
是指对值的截断
torch.clamp(input,min,max,out=None)
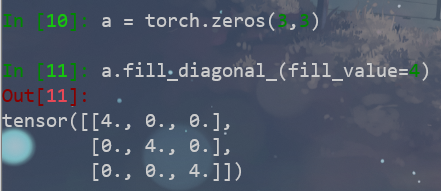
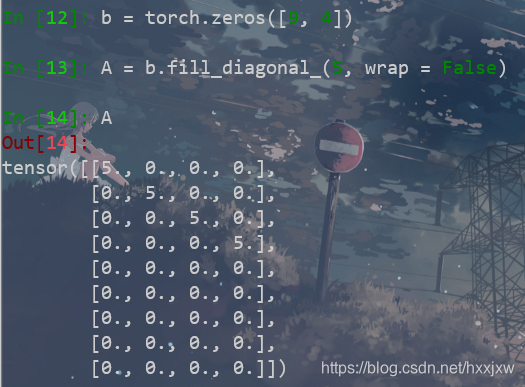
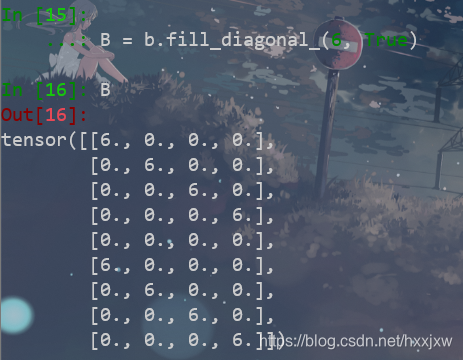
tensor.fill_diagonal_() 填充对角线
fill_diagonal_(fill_value, wrap=False)
至于wrap值的含义
torch.stack()
当有如下情景,我需要4维tensor,(b,c,w,h), 而写的程序是单张图片遍历的,即每张图片(c,w,h),这时,就需要先用一个list,然后每次append,到最后
torch.stack(list)默认是从第0维开始stack
outputs = torch.stack(inputs, dim=0)torch.stack((R, spatial_R), dim=1)
和torch.stack的区别是stack会新增一个维度,cat不会
torch.cat
将两个tensor拼接在一起。 也可以多个,不只是两个
和torch.stack的区别是stack会新增一个维度,cat不会
C = torch.cat( (A,B),0 ) #按维数0拼接(竖着拼) C = torch.cat( (A,B),1 ) #按维数1拼接(横着拼) C = torch.cat( (A,B,C),1 )
torch.cat还可以把list中的tensor拼接起来


torch.zeros_like()
和torch.zeros的区别是
相当于torch.zeros_like(input) is equivalent to torch.zeros(input.size(), dtype=input.dtype, layout=input.layout, device=input.device)
查看当前程序用的GPU个数
torch.cuda.device_count()比如我一共有8张卡,但是我当前程序运行的是CUDA_VISIBLE_DEVICES=0,1
那么torch.cuda.device_count()返回就是2
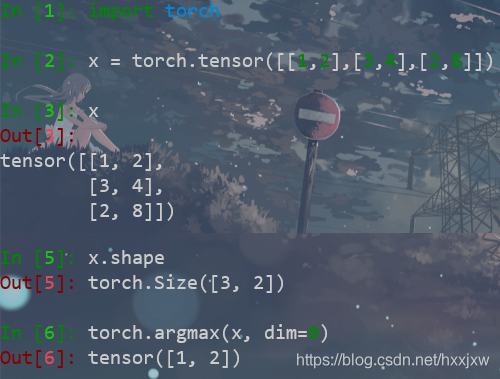
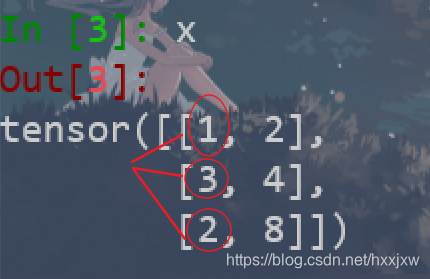
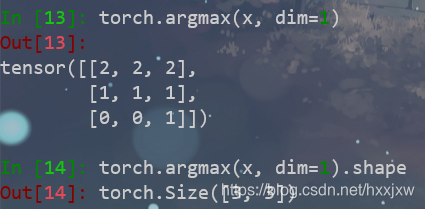
torch.argmax() / torch.argmin()
注意,这个操作是不可导的
返回tensor某一维度上最大值和最小值的下标
如果有多个,会只返回一个
是这么比的
dim=0 是这么比的
dim=1是这么比的
dim=2是这么比的


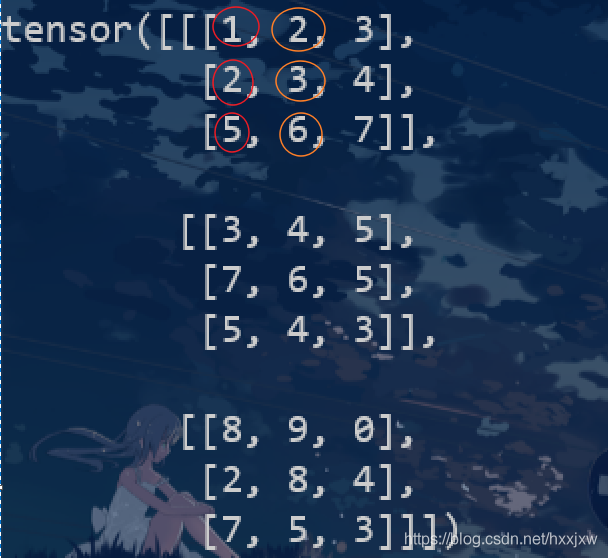


torch.gather() / tensor.gather()
torch.gather(input, dim, index, *, sparse_grad=False, out=None)gather输入数据的特定维度指定位置的值。即沿给定维度
dim将输入索引张量index指定位置的值进行聚合gather相比于index_select, index_select的index只能是1-D的,而gather可以是多维的
返回的结果和index相同shape
注意,在gather函数中,idx隐含着带着dim指定的这个维度的信息
idx的第一行对应着input的第一行,..., idx的第n行对应着input的第n行
例如idx的第0行[5,4,3,2,1], 那么它就是去input的第0行去取第5个,第4个,..., 第1个,即取[0,5], [0,4], [0,3], ..., [0,0]
batch_gather
使用pytorch实现
tf.batch_gather:def batch_gather(data:torch.Tensor, index:torch.Tensor): length = index.shape[0] t_index = index.data.numpy() t_data = data.data.numpy() result = [] for i in range(length): result.append(t_data[i, t_index[i], :]) return torch.from_numpy(np.array(result))


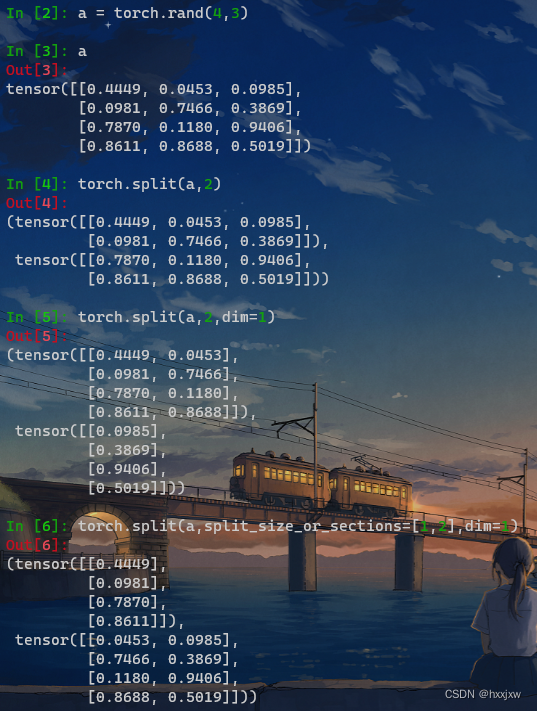
torch.split() / tensor.split()
和numpy的操作不太一样
当split_size_or_sections参数是单个数值的时候,和np.split()一样都是均分成几份
但是当split_size_or_sections参数是list的时候,torch.split代表的是切成每块的长度,所以所有list element的值相加应该等于原feature的长度
而np.split()的list参数指定的是在哪几个位置切一刀,不一样的
torch.split(tensor, split_size_or_sections, dim=0)
例如我在算contrastive loss的时候,有x_i和x_j, 为了方便计算,先concat起来
x = torch.cat((x_i, x_j), dim=0)
x_i, x_j = torch.split(x, batch_size, dim=0)x_i和x_j的b就分别是batch_size
torch.split传入的len还可以是list,就是可以按照你给的不同长度分割
这也是torch.split()和torch.chunk()的区别,split可以不等分,chunk必须等分
torch.sort() 排序
从小到大
x, indices = torch.sort(x, dim=2, descending=False)从大到小是 descending=True
torch.mean()
求平均值
torch.mean(x, dim=0)
Pytorch程序的可复现性 / 设置随机数种子
使得结果可复现
def setup_seed(seed): torch.manual_seed(seed) torch.cuda.manual_seed_all(seed) np.random.seed(seed) random.seed(seed) torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False # 设置随机数种子 setup_seed(20)
nn.Softmax()
numpy没有算softmax的,需要自己写
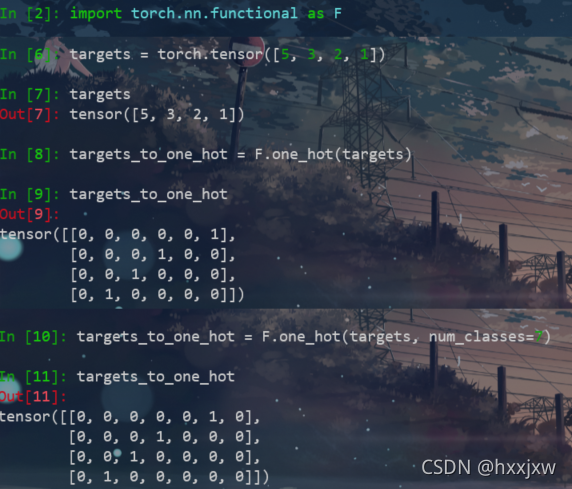
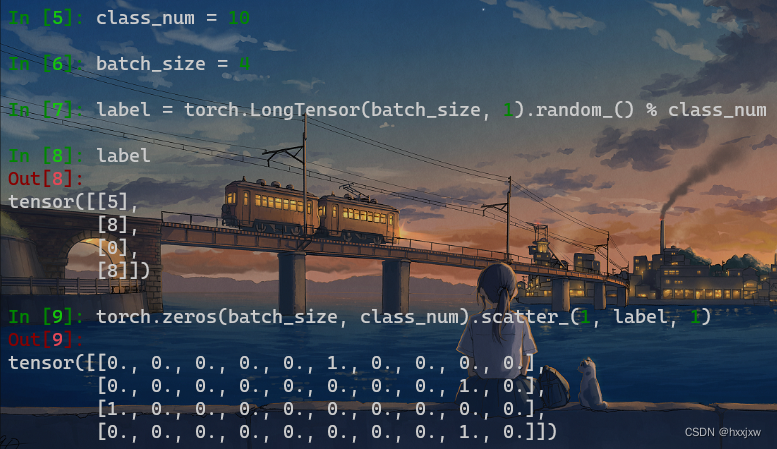
onehot编码 F.onehot()
import torch import torch.nn.functional as F targets = torch.tensor([5, 3, 2, 1]) targets_to_one_hot = F.one_hot(targets) # 默认按照targets其中的最大值+1作为one_hot编码的长度 # result: # tensor( # [0, 0, 0, 0, 0, 1], # [0, 0, 0, 1, 0, 0], # [0, 0, 1, 0, 0, 0], # [0, 1, 0, 0, 0, 0] #) targets_to_one_hot = F.one_hot(targets, num_classes=7) # 指定one_hot编码长度为7 # result: # tensor( # [0, 0, 0, 0, 0, 1, 0], # [0, 0, 0, 1, 0, 0, 0], # [0, 0, 1, 0, 0, 0, 0], # [0, 1, 0, 0, 0, 0, 0] #)
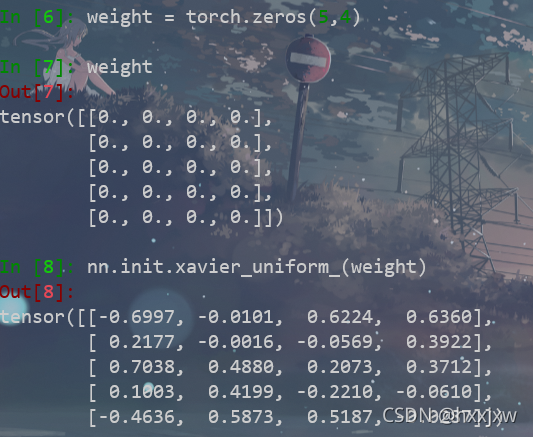
nn.init.xavier_uniform_()
xavier是一种初始化方法
使得每一层输出的方差应该尽量相等,包括前向传播和后向传播。(为了使得网络中信息更好的流动)
还有其他初始化方法
均匀分布 torch.nn.init.uniform_(tensor, a=0, b=1)
服从~U(a,b)
正态分布 torch.nn.init.normal_(tensor, mean=0, std=1)
服从~N(mean,std)
初始化为常数 torch.nn.init.constant_(tensor, val)
初始化整个矩阵为常数val
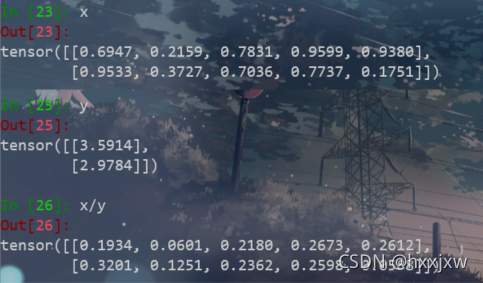
tensor相除
如果是tensor 除 tensor的话
x的第一行的每个值都除以 3.5914
x的第二行的每个值都除以 2.9784
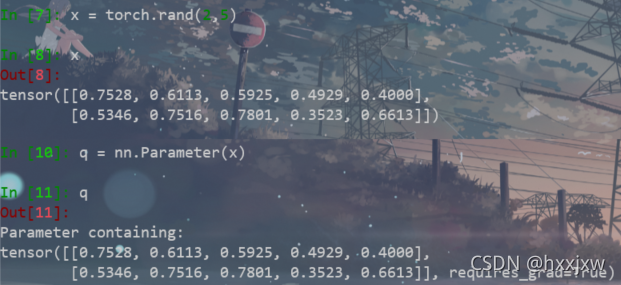
torch.nn.Parameter
Parameter实际上也是Tensor,只不过比tensor多个一个操作,parameter会自动累加到Parameter 列表中。
比如我在模型中加入了一个attention模块,attention中的weight和bias都是需要训练的参数,那我就将weight = nn.Parameter(weight)和bias = nn.Parameter(bias),这样之后
opt = Adam(net.parameters(), learning_rate=0.001)
net.parameters()中就包含了weight和bias了
nn.Module.register_buffer()
往当前Module中添加一个永久的buffer
模型中需要保存下来的参数包括两种:
- 一种是反向传播需要被optimizer更新的,称之为 parameter
- 一种是反向传播不需要被optimizer更新,称之为 buffer
第一种参数我们可以通过
model.parameters()返回;第二种参数我们可以通过model.buffers()返回。因为我们的模型保存的是state_dict返回的OrderDict,这两种参数都会被保存
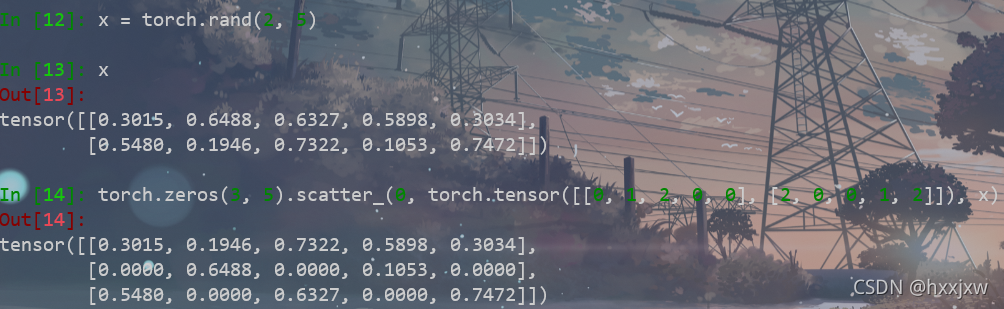
torch.scatter() & torch.scatter_()
这个 scatter 可以理解成放置元素或者修改元素
scatter() 和 scatter_() 的作用一样。不同之处在于 scatter() 不会直接修改原来的 Tensor,而 scatter_() 会在原来的基础上对Tensor进行修改。
两种写法
torch.scatter_(input, dim, index, src) 或 input.scatter_(dim, index, src)将src中数据根据index中的索引按照dim的方向填进input中.
核心就是
这是二维, dim=0的情况,如果dim=1, 那就是 self[i][index[i][j]] = src[i][j]
如果三维的情况
scatter() 一般可以用来对标签进行 one-hot 编码,这就是一个典型的用标量来修改张量的一个例子
但是注意scatter按照index修改,就是说,index值为6,那么就会修改6的位置,但矩阵都是从0开始编号的,修改的其实是第7个位置
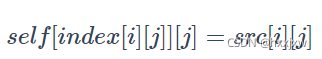

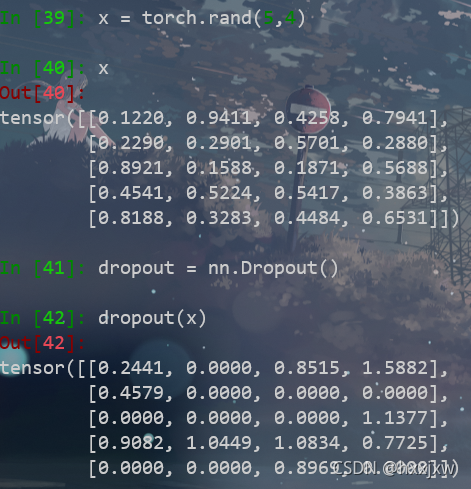
torch.nn.Dropout()
torch.nn.Dropout(p=0.5, inplace=False)
每次随机将tensor中部分元素值为0
inplace=True的话,会直接改x的值,默认是False,不修改x的值
F.dropout()
有坑
如果仅仅使用F.dropout(x)而不改变training值,是没有启用dropout的。

torch.exp()
对tensor取exp
注意这里的x必须要是float,int不行
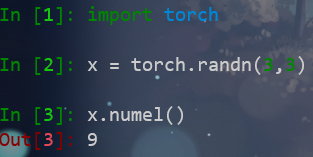
tensor.numel()
获取tensor中一共包含多少个元素
和tensor.nelement()效果一样
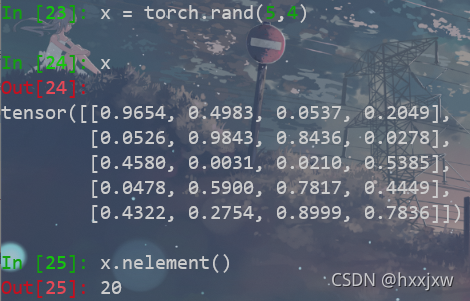
tensor.nelement()
nelement() 可以统计 tensor的元素个数
和tensor.numel()效果一样
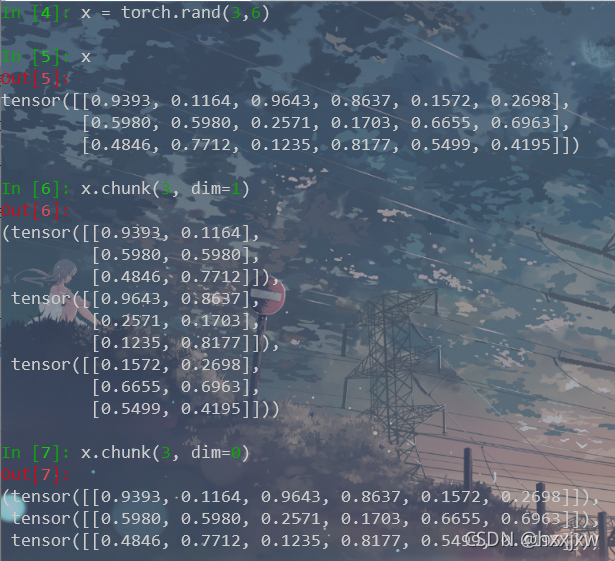
torch.chunk()
chunk方法可以对张量分块,返回一个张量列表
分别是沿dim=0和dim=1将x分成3块
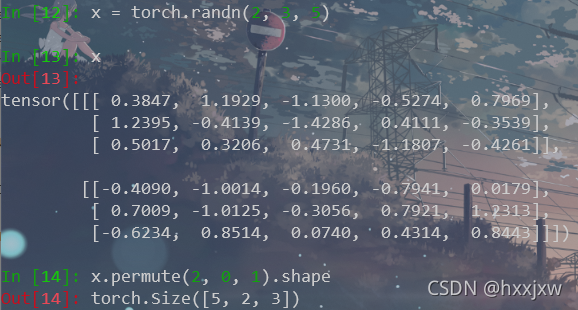
tensor.permute() 维度转换, 通道转换
将tensor的维度换位。
>>> x = torch.randn(2, 3, 5) >>> x.size() torch.Size([2, 3, 5]) >>> x.permute(2, 0, 1).size() torch.Size([5, 2, 3])
x.permute(2,0,1)就是把原来的第2维挪到第0维,第0维挪到第1维,第1维挪到第3维
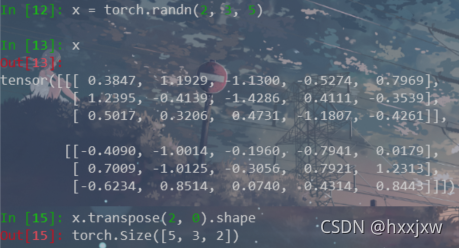
torch.transpose()
transpose只能同时作用于tensor的两个维度
连续使用transpose也可实现permute的效果
tensor.expand() 张量复制
PyTorch 中常用于张量数据复制操作有 expand 和 repeat
expand()返回张量在某一个维度扩展之后的张量,就是将张量广播到新形状。函数对返回的张量不会分配新内存,即在原始张量上返回只读视图,返回的张量内存是不连续的。如果希望张量内存连续,可以调用contiguous函数。
repeat 返回的张量在内存中是连续的
x.expand(2,3) 将x扩展到[2,3]的shape
如果出现-1表明这一维度上原来的size不变
>> x = torch.randn(2, 1, 1, 4) >> x.expand(-1, 2, 3, -1) torch.Size([2, 2, 3, 4])即第0维的2和第3维的4保持原size不变
tensor.expand_as() 张量复制
tensor.expand_as()这个函数就是把一个tensor变成和函数括号内一样形状的tensor,用法与expand()类似。
self.expand_as(other)等价于self.expand(other.size())差别是expand括号里为size,expand_as括号里为其他tensor。

tensor.clone()
tensor的复制,用copy, deepcopy()那一套是不行的
要用tensor.clone()
返回原tensor的拷贝,返回的新的tensor和原来的tensor具有同样的大小和数据类型
最好是tensor.clone().detach()
因为若原tensor的requires_grad = True,clone()返回的是中间节点,梯度会流向原tensor,即返回的tensor的梯度会叠加到原来的tensor上。
torch.addmm()
addmm函数是等式beta*mat + alpha*(mat1 @ mat2)的优化版本torch.addmm(beta=1, mat, alpha=1, mat1, mat2, out=None) 等于 beta * mat + alpha * (mat1 @ mat2)
torch.addmm_()
则是可以在原对象上进行修改
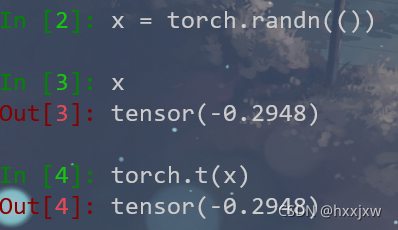
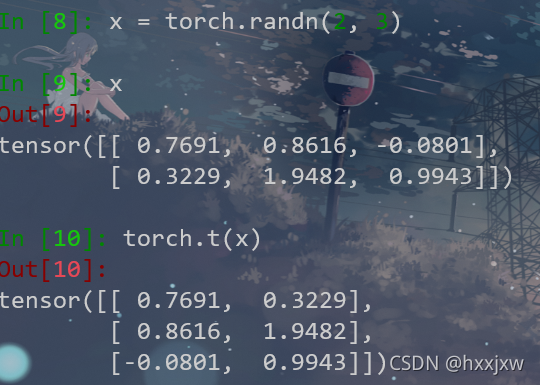
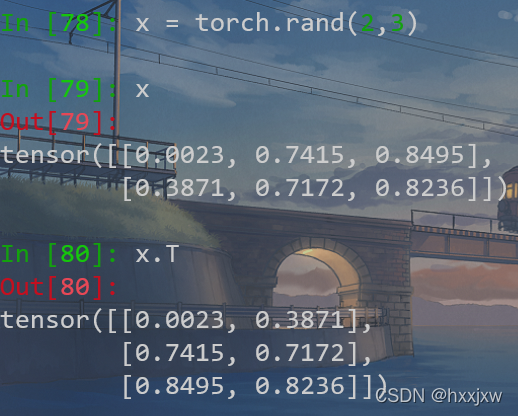
torch.t() / tensor.T 转置
要求输入<=2D
当输入是0D或1D的时候,得到的结果是其本身
当输入是2D的时候就相当于转置
也可以tensor.T

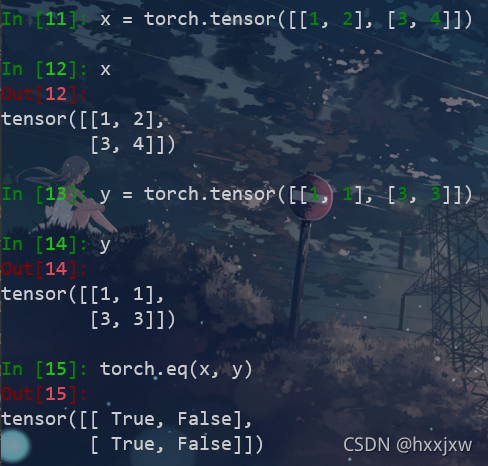
torch.eq()
对两个张量Tensor进行逐元素的比较,若相同位置的两个元素相同,则返回True;若不同,返回False。
torch.equal() / tensor.equal()
torch.equal(x,y) 或 x.equal(y)如果两个tensor x和y有相同的size并且值都相等,返回True,否则False

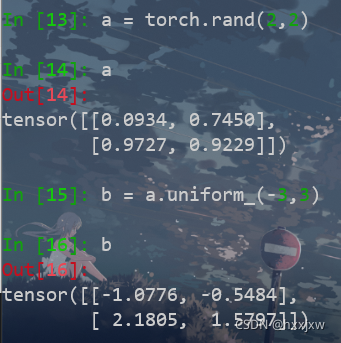
tensor.uniform_()
tensor.uniform_(a,b)
从均匀分布U(a,b)中采样,填充tensor
这里tensor a的作用是提供需要b填充的tensor的size
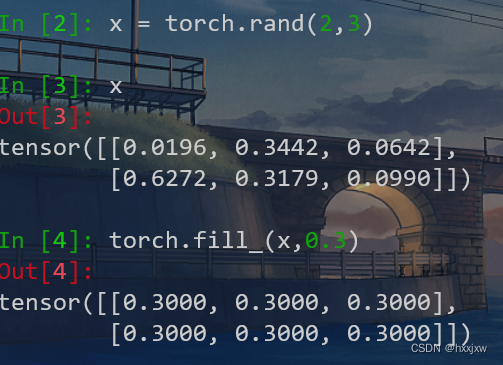
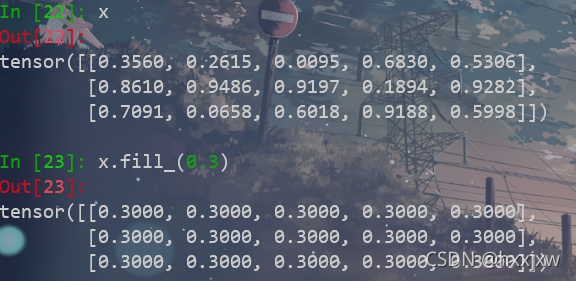
torch.fill_() / tensor.fill_()
用某个值填充tensor
tensor.normal_()
用标准正态分布值填充tensor

torch.normal() 生成正态分布的tensor
torch.normal (mean, std, out =None) 返回一个张量,包含从给定参数 means, std 的离散正态分布中抽取随机数。

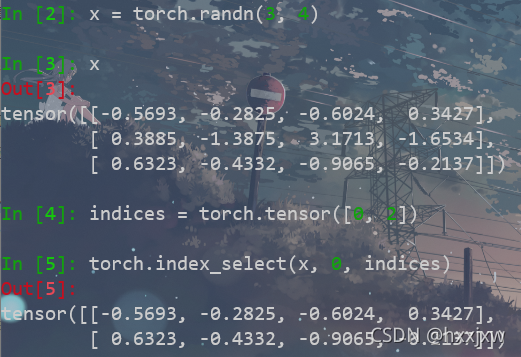
torch.index_select() / tensor.index_select()
根据dim取出input中的index对应的元素,并且返回一个tensor
index_select(input, dim, index)
input表示输入的变量;dim表示从第几维挑选数据,类型为int值;index表示从选择维度中的哪个位置挑选数据,类型为torch.Tensor类的实例;注意index一定要是long类型
也可以
x.index_select(dim, index)
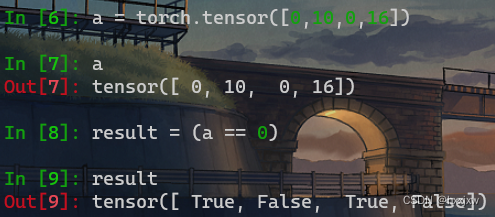
整数tensor转换为布尔的tensor
a = torch.tensor([0,10,0,16]) result = (a == 0)
tensor插值 F.interpolate
既可以上采样又可以下采样,即既可以扩大size又可以缩小size
Python双线性插值resize (opencv)(F.interpolate)_hxxjxw的博客-CSDN博客
tensor.gt 逐元素比较tensor大小, 得到布尔值True, False, 制作mask
即是否( input > other )
torch.ge()
比较的是input >= other ,其他的同torch,gt
torch.le()
比较的是input <= other ,其他的同torch,gt
torch.lt()
比较的是input < other ,其他的同torch,gt

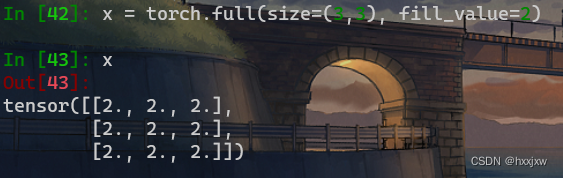
torch.full() / tensor.new_full()
torch.full(size, fill_value, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)生成size大小以指定值填充的tensor
tensor.new_full 返回的tensor与当前tensor的 dtype和device相同,可以不用设定了

torch.full_like()
torch.full_like(input, fill_value, \*, dtype=None, layout=torch.strided, device=None, requires_grad=False, memory_format=torch.preserve_format)torch.full_like(input, fill_value),就是将input的形状作为返回结果tensor的形状, 但是值全部是由fill_value填充
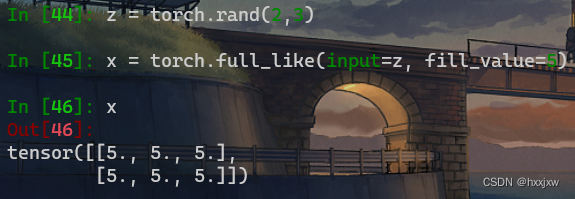
torch.empty()
创建一个未被初始化数值的tensor,tensor的大小是由size确定
每次生成的数值都不一样
torch.tensor() 创建的是float类型的张量
torch.empty() 创建任意数据类型的张量
同样的版本,torch 1.4.0, 上面是在linux下, 下面是在windows下
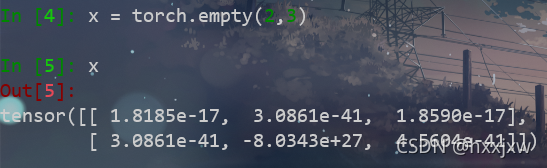

torch.narrow()
tensor.narrow(dim, start, num)
对dim维进行索引,从第start个开始取,取num个
起到筛选一定维度上的数据作用。与
x[begin:end]相同
torch.randperm()
random permutation的缩写, 将0~n-1(包括0和n-1)随机打乱后获得的数字序列
对tensor进行shuffle就用它

仿射变换
在pytorch框架中, F.affine_grid 与 F.grid_sample联合使用来对图像进行变形。
F.affine_grid 根据形变参数产生sampling grid,F.grid_sample根据sampling grid对图像进行变形。
F.affine_grid()
F.affine_grid 根据形变参数产生sampling grid
生成点
F.grid_sample()
F.grid_sample根据sampling grid对图像进行变形
根据点来做操作
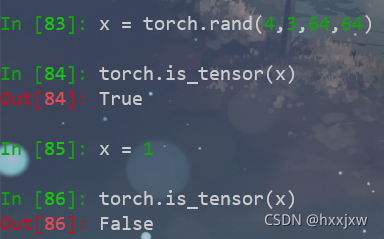
torch.is_tensor()
判断一个值是不是tensor
torch.is_tensor(x) = isinstance(x, Tensor)
但是更推荐使用isinstance(obj, Tensor)这种方法
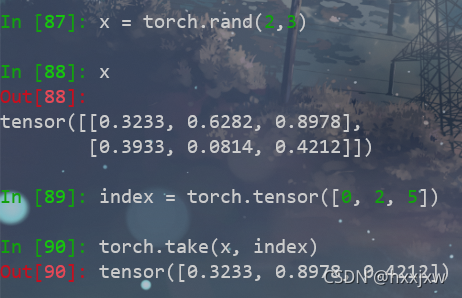
torch.take()
torch.take(input, index)
将输入input,不管是几维的,都看作是1维度的,然后根据index取元素
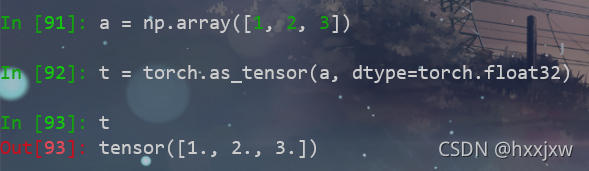
torch.as_tensor()
将其它类型转化为tensor, 这些数据可以是( list, tuple, NumPy ndarray, scalar, and other types.)等等
如果要转换一个 numpy 数组,使用 torch.as_tensor() 或 torch.from_numpy() 来避免复制数据。如果是用torch.tensor() 会复制数据
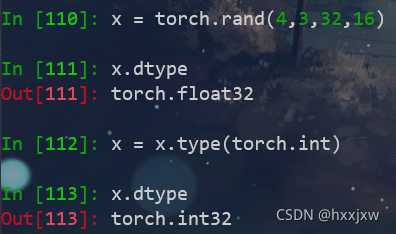
tensor.type()
改变tensor类型
x.type(torch.float) = x.float()
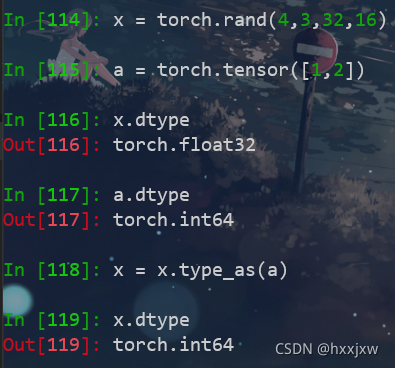
tensor.type_as()
改成相应tensor的类型
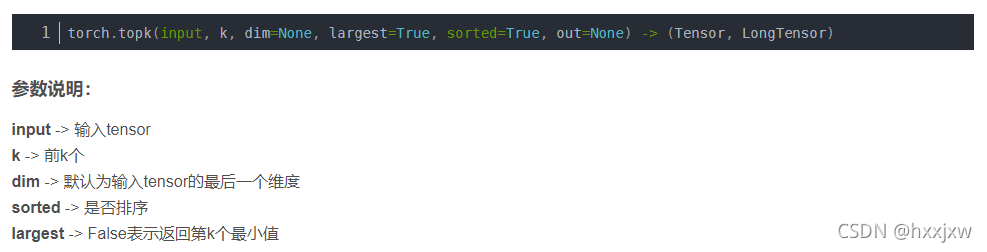
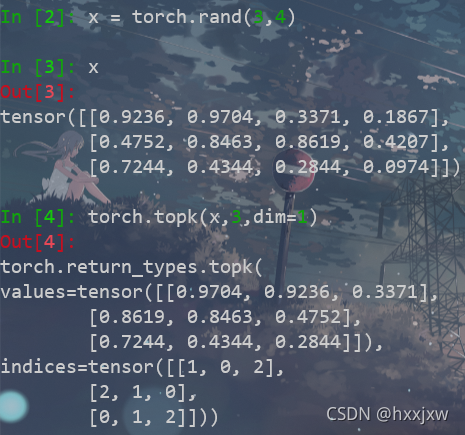
torch.topk() 返回前k个最大元素
这里的dim不能是list,不能和torch.sum一样,dim=[2,3]不行
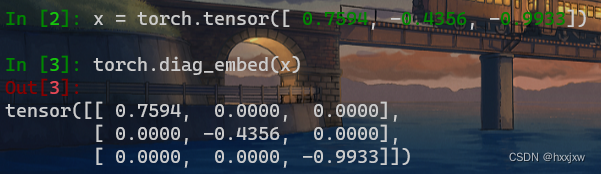
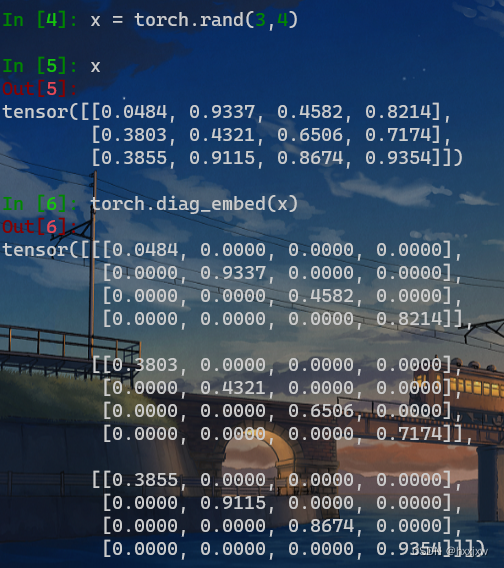
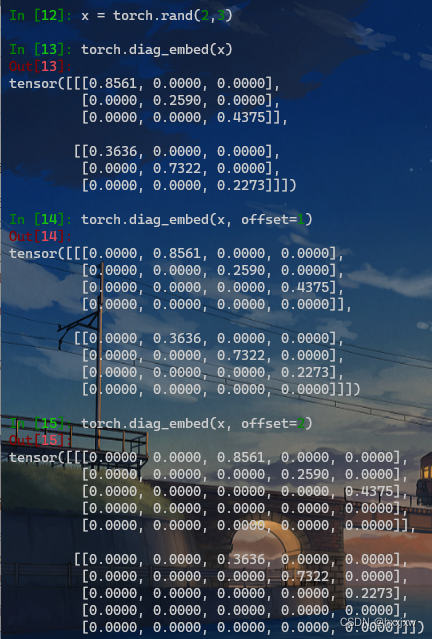
torch.diag_embed() 将输入元素填充为对角线位置,其他位置填充0
torch.diag_embed(input, offset=0, dim1=- 2, dim2=- 1)
三维,四维的也可以
The argument
offsetcontrols which diagonal to consider:
If
offset= 0, it is the main diagonal.If
offset> 0, it is above the main diagonal.If
offset< 0, it is below the main diagonal.
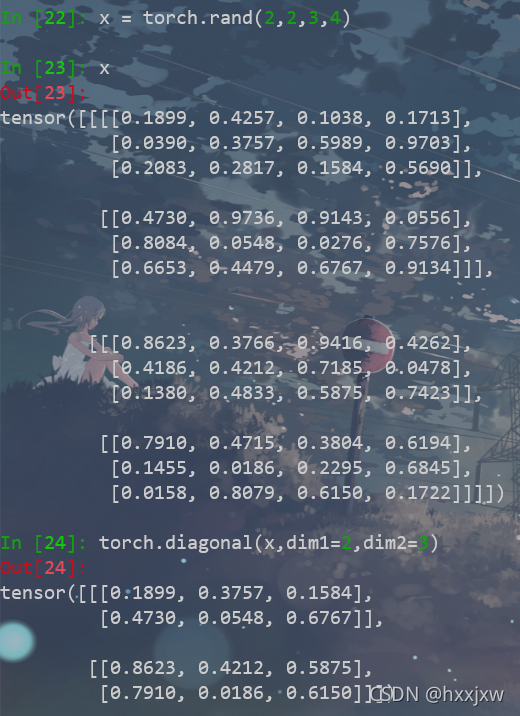
torch.diagonal() 取对角线元素
torch.diag()只能1D或者2D
多维tensor用torch.diagonal()处理
对角线元素置0
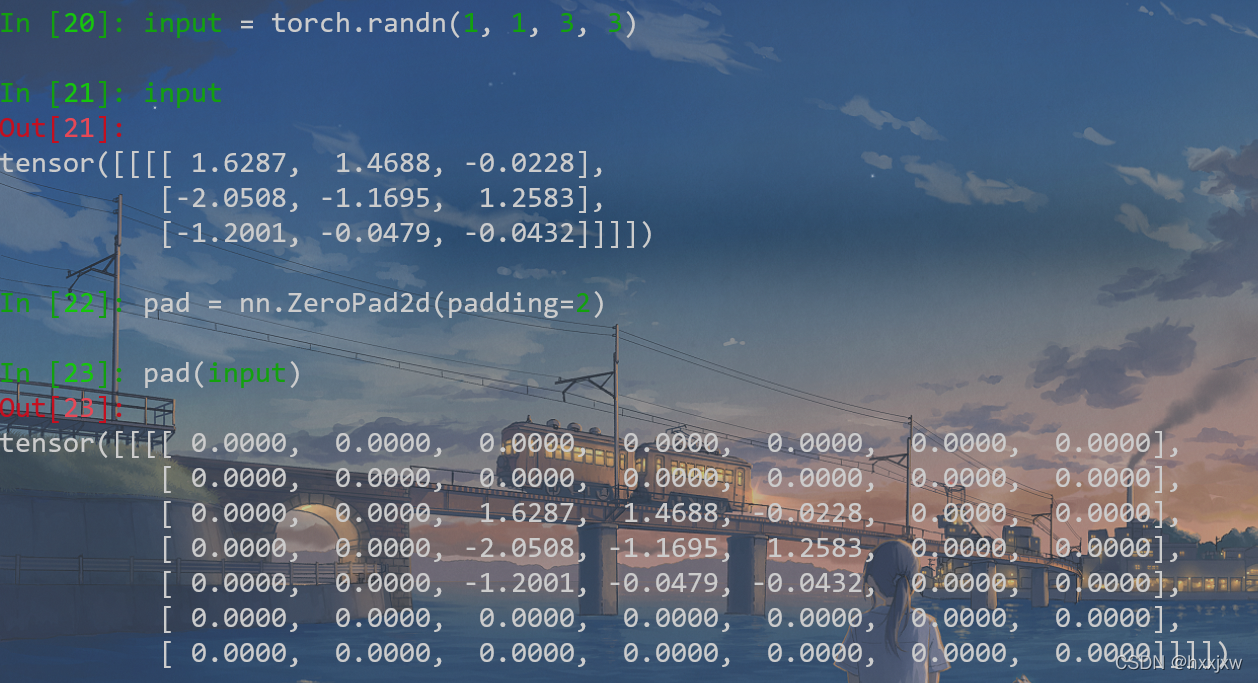
对tensor进行补0(扩展维度)
例如希望得到的是[b,256,16], 而现在有的是[b,256,14],想补0使它最后一维变成16
torch.zeros(b,256,2) torch.cat((x,y), dim=2)也可以用nn.ZeroPad2d
nn.ZeroPad2d() 补零填充
输入要是(b,c,h,w)或是(c,h,w)
删除Tensor中指定位置的元素
pytorch没有类似的函数
自己写也不慢
def del_tensor_ele(arr,index): arr1 = arr[0:index] arr2 = arr[index+1:] return torch.cat((arr1,arr2),dim=0)
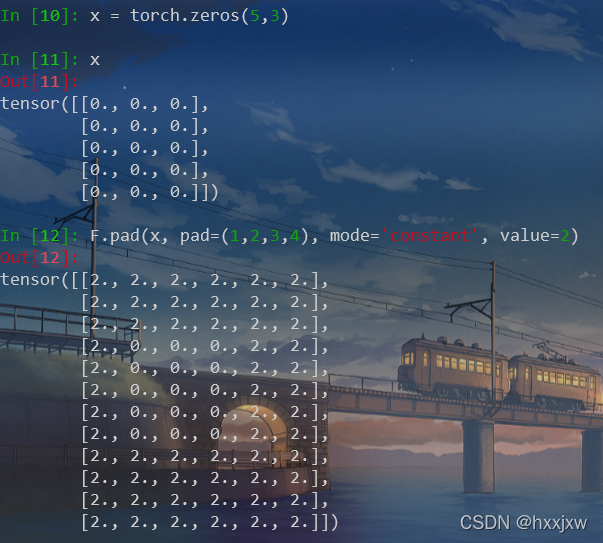
F.pad tensor扩充
torch.nn.functional.pad(input, pad, mode='constant', value=0)input
需要扩充的tensor,可以是图像数据,抑或是特征矩阵数据
pad
扩充维度,用于预先定义出某维度上的扩充参数
mode
扩充方法,’constant‘, ‘reflect’ or ‘replicate’三种模式,分别表示常量,反射,复制
value
扩充时指定补充值,但是value只在mode='constant’有效,即使用value填充在扩充出的新维度位置,而在’reflect’和’replicate’模式下,value不可赋值可以进行一维、两维、三维填充
一维填充
对最后一维进行填充
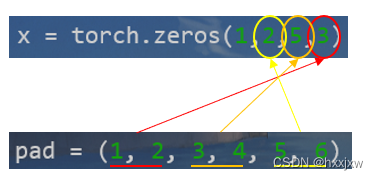
pad的含义是(左边填充数, 右边填充数)
pad也可以写成(1,2,0,0)
二维填充
对后两维进行填充
pad的定义是(左边填充数, 右边填充数, 上边填充数, 下边填充数)
即(最后一维开头填充数,最后一维结尾填充数,倒数第二维开头填充数,倒数第二维结尾填充数)
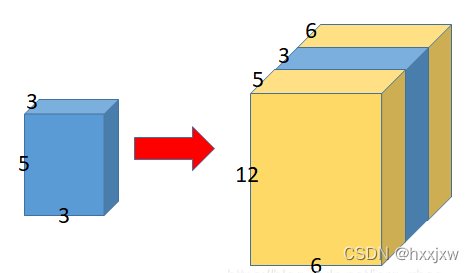
三维填充
pad的含义是(左边填充数, 右边填充数, 上边填充数, 下边填充数, 前边填充数,后边填充数)
即


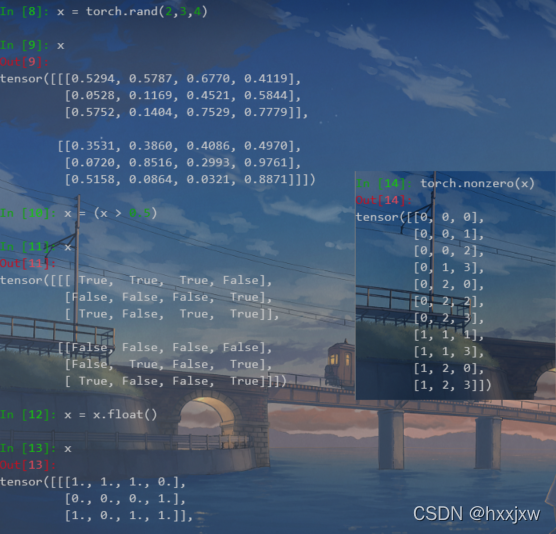
torch.nonzero() 输出input中非零元素的坐标
torch.nonzero(x)
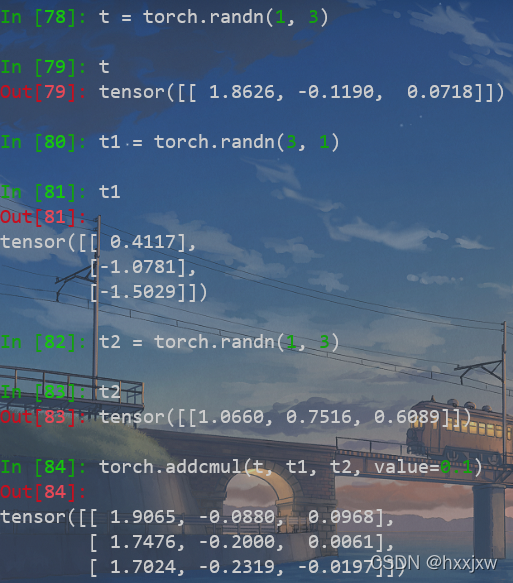
torch.addcmul()
torch.addcmul(input, tensor1, tensor2, *, value=1, out=None)用
tensor2对tensor1逐元素相乘,并对结果乘以标量值value然后加到tensor
0.4117*1.0660*0.1+1.8626 = 1.9065
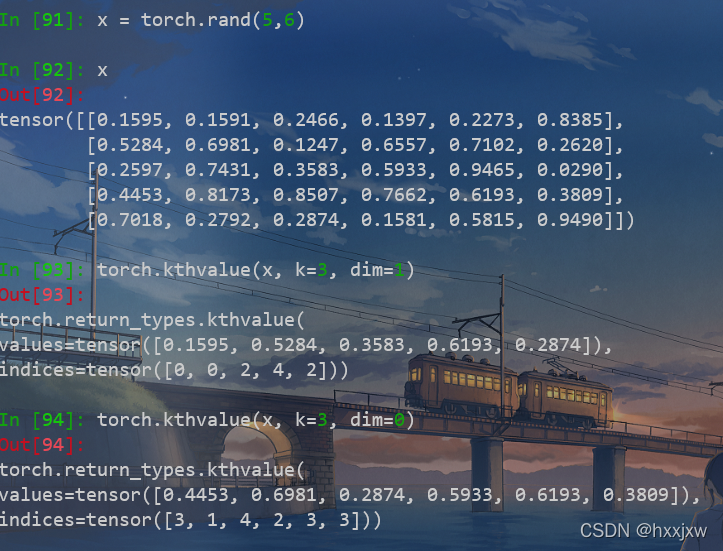
torch.kthvalue() 取
input指定维度上第k个最小值torch.kthvalue(input, k, dim=None, out=None)取输入张量
input指定维度上第k个最小值,若不指定dim,则默认为input的最后一维
第3个最小值
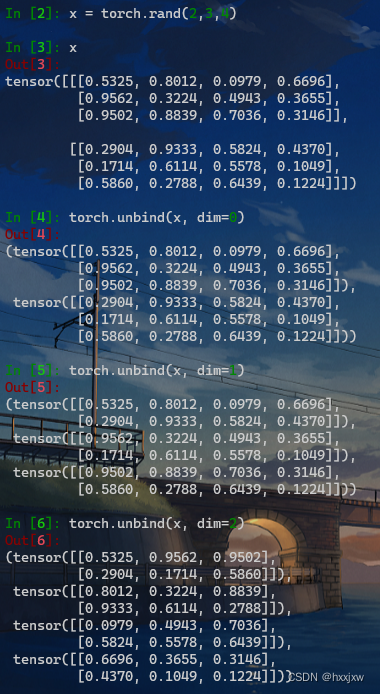
torch.unbind()
torch.unbind(tensor, dim=0)移除指定维度后,返回一个元组,包含了沿着指定维切片后的各个切片
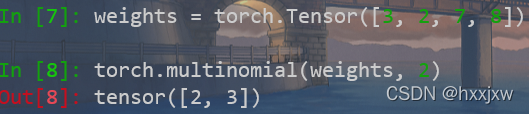
torch.multinomial()
multinomial 是多项式的意思
根据给定权重对数组进行多次采样,返回采样后的元素下标
torch.multinomial(input, num_samples, replacement=False, out=None)设置replacement=True,可以进行有放回的采样,此时的n_sample参数可以大于input的长度:
按权重采样,从四个元素中随机选择两个,每个元素被选择到的概率分别为:[0.2, 0.2, 0.3, 0.3]:
weights = torch.Tensor([0.2, 0.2, 0.3, 0.3]) # 采样权重 torch.multinomial(weights, 2)
按频率采样。multinomial()函数的input可以是大于1的数,在函数内部会再次进行归一化。
例如在处理文本对word进行采样时,直接传入词典中每个词的词频就好了,不需要手动归一化。
weights = torch.Tensor([3, 2, 7, 8]) torch.multinomial(weights, 2)
权重为0的元素
如果是无放回的采样,input中值为0的元素只有在其他元素都被抽到后,才会被抽到;
如果是有放回的采样,input中值为0的元素永远不会被抽到

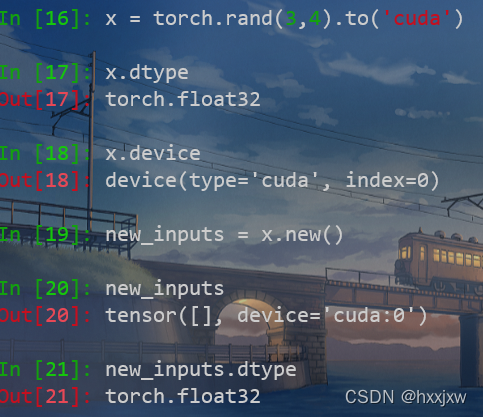
tensor.new() 创建一个新的无内容Tensor,type和device与原Tensor一致
只是type和device一致
torch.einsum
爱因斯坦求和约定:用于简洁的表示乘积、点积、转置等方法。
在代码中上面的式子可以表示为字符串:
'ik,kj->ij'使用torch.einsum实现上述功能:
>>> import torch >>> A = torch.randn(3, 4) >>> B = torch.randn(4, 5) >>> C = torch.einsum('ik,kj->ij', A, B) >>> C.shape torch.Size([3, 5])也可以这样
>>> A = torch.randn(3, 4) >>> B = torch.randn(5, 4) >>> C = torch.einsum('ik,jk->ij', A, B) >>> C.shape torch.Size([3, 5])求和
>>> C = torch.einsum('ij->', A) >>> C tensor(1.5575)列求和
>>> C = torch.einsum('ij->j', A) >>> C tensor([-0.4369, 1.1548, 0.8594, -0.0198]) >>> C.shape torch.Size([4])行求和同理
点积求和
>>> C = torch.einsum('ij,ij->', A, A) >>> C tensor(11.6726)转置
>>> C = torch.einsum('ij->ji', A) >>> C.shape torch.Size([4, 3])多维矩阵乘法
>>> A = torch.randn(3, 4) >>> B = torch.randn(3, 4, 5) >>> C = torch.randn(4, 5) >>> D = torch.einsum('ij,ijk,jk->ik', A, B, C) >>> D.shape torch.Size([3, 5])

torch.var 计算方差
torch.var(input, dim, unbiased=True, keepdim=False, *, out=None)如果
unbiased为False,则将通过有偏估计量计算方差。否则,将使用贝塞尔校正。import torch x = torch.rand(4) print(x) print(torch.var(x, unbiased=False)) mean_ = torch.mean(x) ans = 0. for i in range(4): ans += torch.pow(x[i]-mean_ , 2) ans /= 4 print(ans)
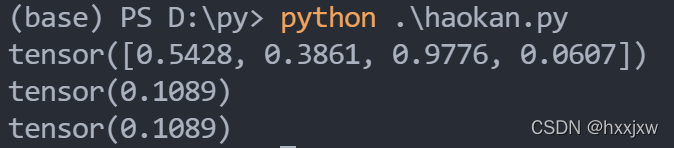
nn.Upsample()
CLASS torch.nn.Upsample(size=None, scale_factor=None, mode='nearest', align_corners=None)align_corners (bool, optional) – 如果为True,输入的角像素将与输出张量对齐,因此将保存下来这些像素的值。仅当使用的算法为
'linear','bilinear'or'trilinear'时可以使用。默认设置为Falsenn.Upsample 和 F.interpolate可以实现一样的功能
既可以上采样又可以下采样,即既可以扩大size又可以缩小size
torch.tile
通过重复
input的元素构造张量torch.tile(input, reps)reps参数指定在每个维度重复次数
>>> x = torch.tensor([1, 2, 3]) >>> x.tile((2,)) tensor([1, 2, 3, 1, 2, 3]) >>> y = torch.tensor([[1, 2], [3, 4]]) >>> torch.tile(y, (2, 2)) tensor([[1, 2, 1, 2], [3, 4, 3, 4], [1, 2, 1, 2], [3, 4, 3, 4]])pytorch 1.4还没有这个函数,1.7及更低都没有,1.8还没试
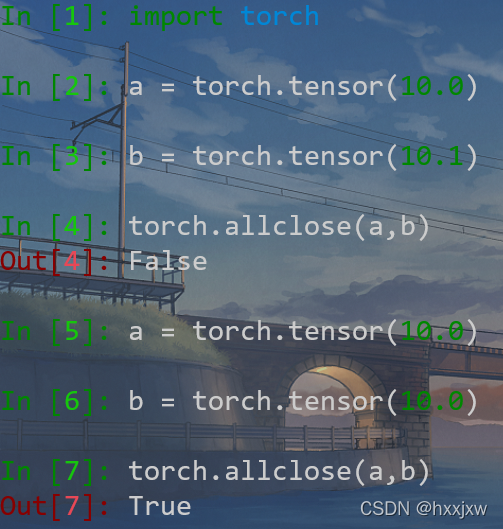
torch.allclose()
比较两个元素是否接近,比较A和B是否接近的公式为
|A-B| <= atol+rtol*|B|
torch.allclose(input, other, rtol=1e-05, atol=1e-08, equal_nan=False)
torch.norm() 求模/求范数
模就是二范数
torch.norm(input, p='fro', dim=None, keepdim=False, out=None, dtype=None)输入代码
import torch rectangle_height = 3 rectangle_width = 4 inputs = torch.randn(rectangle_height, rectangle_width) for i in range(rectangle_height): for j in range(rectangle_width): inputs[i][j] = (i + 1) * (j + 1) print(inputs)得到一个3×4矩阵,如下
tensor([[ 1., 2., 3., 4.], [ 2., 4., 6., 8.], [ 3., 6., 9., 12.]])接着我们分别对其行和列分别求2范数
inputs1 = torch.norm(inputs, p=2, dim=1, keepdim=True) print(inputs1) inputs2 = torch.norm(inputs, p=2, dim=0, keepdim=True) print(inputs2)结果分别为
tensor([[ 5.4772], [10.9545], [16.4317]]) tensor([[ 3.7417, 7.4833, 11.2250, 14.9666]])怎么来的?

nn.ConstantPad2d() 常数填充
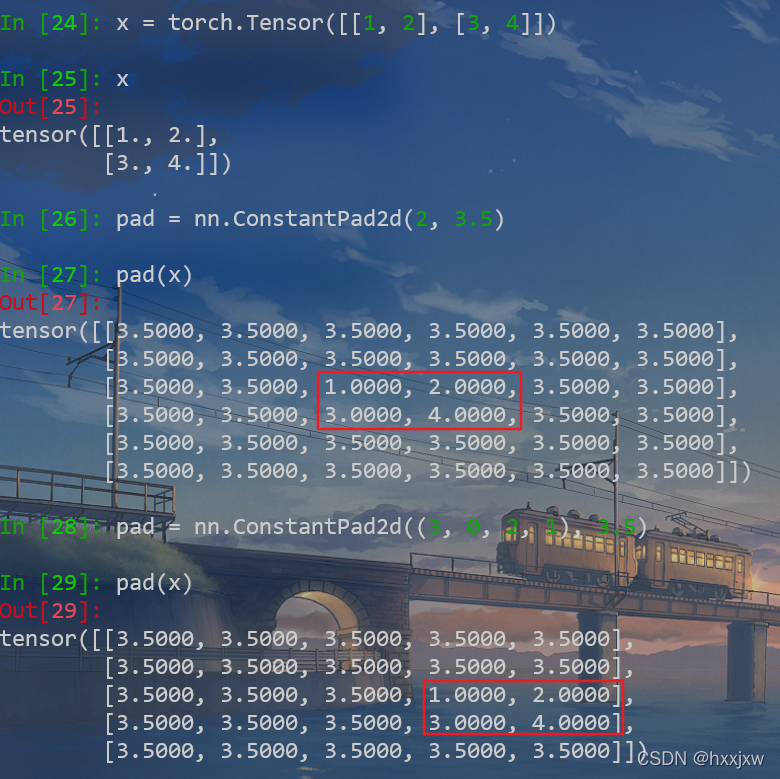
nn.ReplicationPad2d() 重复填充
重复填充即重复图像的边缘像素值,将新的边界像素值用边缘像素值扩展

nn.Unfold() 从分批输入张量中提取滑动局部块
torch.nn.Unfold(kernel_size, dilation=1, padding=0, stride=1)就是im2col的实现,常用作手动实现卷积的滑窗操作
Pytorch im2col (nn.Unfold)_hxxjxw的博客-CSDN博客
这里我们刚才的例子中涉及到了nn.F
old,这个操作和unfold相反,是把一系列的滑动区块拼接成一个张量torch.nn.Fold(output_size, kernel_size, dilation=1, padding=0, stride=1)是col2im的实现
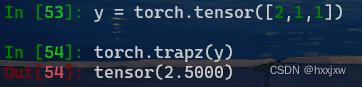
torch.trapz() / torch.trapezoid() 使用复合梯形规则沿给定轴进行积分
trapezoidal 梯形的
torch.trapezoid(y, x=None, *, dx=None, dim=- 1) → Tensor沿
dim计算 trapezoidal rule 。默认情况下,元素之间的间距假定为 1,但dx可用于指定不同的常数间距,而x可用于指定沿dim的任意间距。
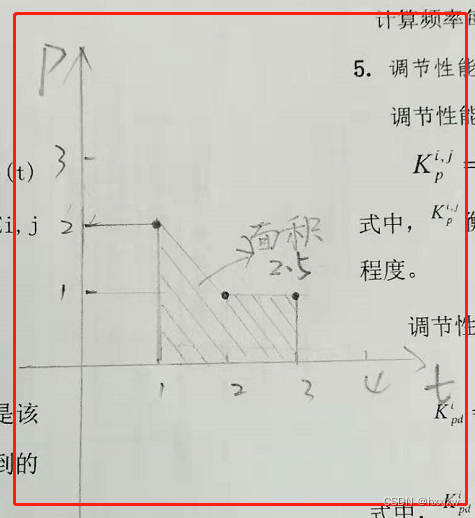
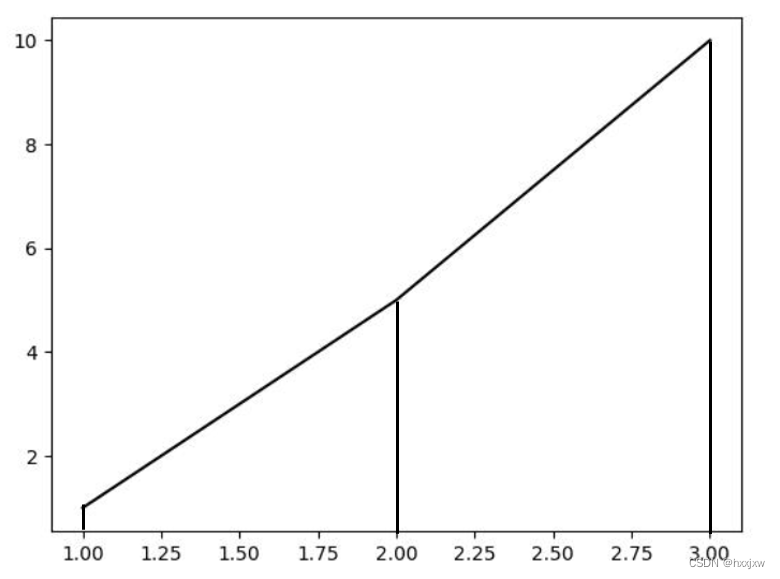
它的计算规则就是一个梯形一个梯形的计算,就算能合起来也不合
像这样的话就直接
计算就是1/2(2+1)+1/2(1+1)



torch.flatten() 拍平
torch.flatten(input, start_dim=0, end_dim=-1)

torch.argsort() / tensor.argsort()
返回的是坐标
默认从小到大排序
torch.argsort(input, dim=- 1, descending=False) → LongTensor

torch 布尔索引
(2条消息) numpy/pytorch 高级索引(整数数组索引 & 布尔索引)_hxxjxw的博客-CSDN博客_python布尔数组索引
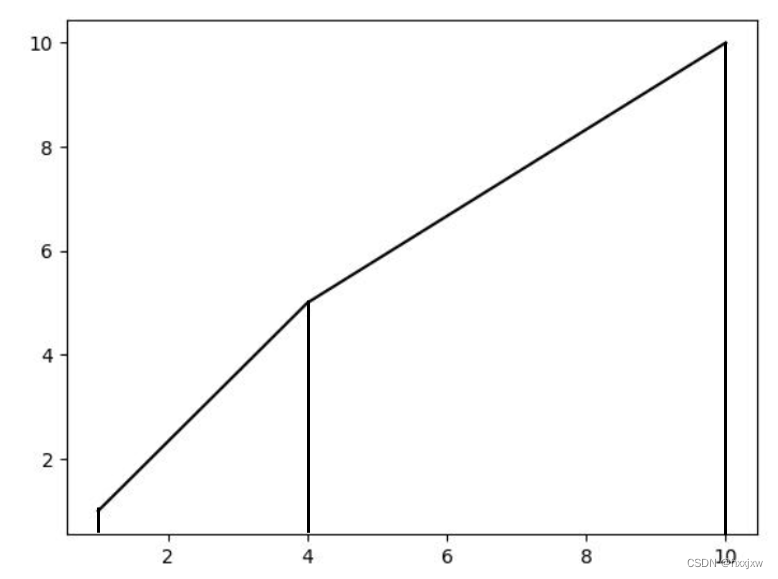
tensor.any()
如果张量tensor中存在一个元素为True, 那么返回True; 只有所有元素都是False时才返回False
tensor.all()
如果张量tensor中所有元素都是True, 才返回True; 否则返回False

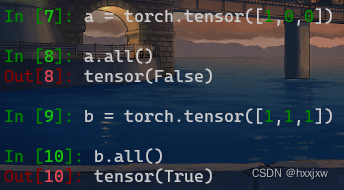
torch.cumsum() 计算
input元素的累积和torch.cumsum(input, dim, *, dtype=None, out=None)返回维度
dim中input元素的累积和
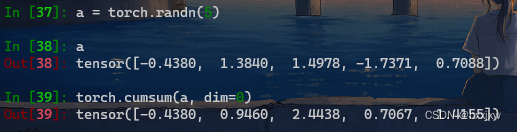
torch.cumprod() 计算
input元素的累积乘torch.cumprod(input, dim, *, dtype=None, out=None)
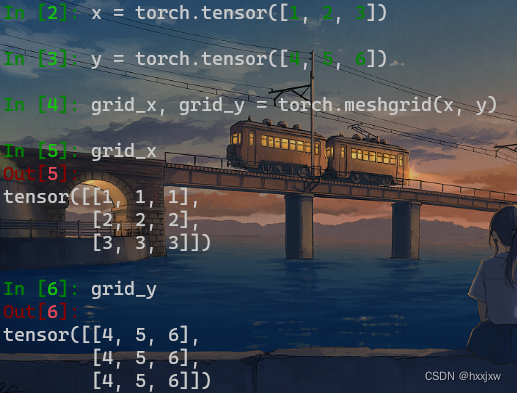
torch.meshgrid() 生成网格
torch.meshgrid()的功能是生成网格,可以用于生成坐标。
函数输入:
输入两个数据类型相同的一维tensor
函数输出:
输出两个tensor(tensor行数为第一个输入张量的元素个数,列数为第二个输入张量的元素个数)
注意:
1)当两个输入tensor数据类型不同或维度不是一维时会报错。
2)其中第一个输出张量填充第一个输入张量中的元素,各行元素相同;第二个输出张量填充第二个输入张量中的元素各列元素相同。<填充效果见实验结果>
即grid_x的值作为点的x坐标,grid_y的值作为点的y坐标
比如0,0点的值就是(1,4), 0,1点就是(1,5)
这个时候再一展平然后拼接就可以了

torch.linspace()
返回一个1维张量,包含在区间start和end上均匀间隔的step个点
torch.linspace(start, end, steps, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False)
- start (float) - 区间的起始点
- end (float) - 区间的终点
- steps (int) - 在start和end间生成的样本数
注意step是产生几个点,而不是各个点之间的距离

torch.cdist() 计算p范数
torch.cdist(x1, x2, p=2.0, compute_mode='use_mm_for_euclid_dist_if_necessary')这个p是指定的,即可以计算1范数(L1loss),可以计算2范数(L2 loss)
即torch.cdist()可以起到l1loss,l2loss的作用
参数
- x1(张量)–形状的输入张量B*P*M. .
- x2(张量)–形状的输入张量B*R*M. .
- p – p值的p范数距离,用于计算每个向量对之间的距离\in [0, \infty] .
- compute_mode –'use_mm_for_euclid_dist_if_necessary'-如果P> 25或R> 25'use_mm_for_euclid_dist',将使用矩阵乘法来计算欧式距离(p = 2)-将始终使用矩阵乘法来计算欧式距离(p = 2)'donot_use_mm_for_euclid -永远不会使用矩阵乘法方法来计算欧式距离(p = 2)默认值:use_mm_for_euclid_dist_if_necessary。
都是算L2范数,L2loss算的最总体的均值或者是和
而cdist算的是各个项之间的均值
即如果a是2*3, b是3*3(这里省略了B,都是1。这里第二维的3可以看作是feature dim)
那么得到的结果是2*3

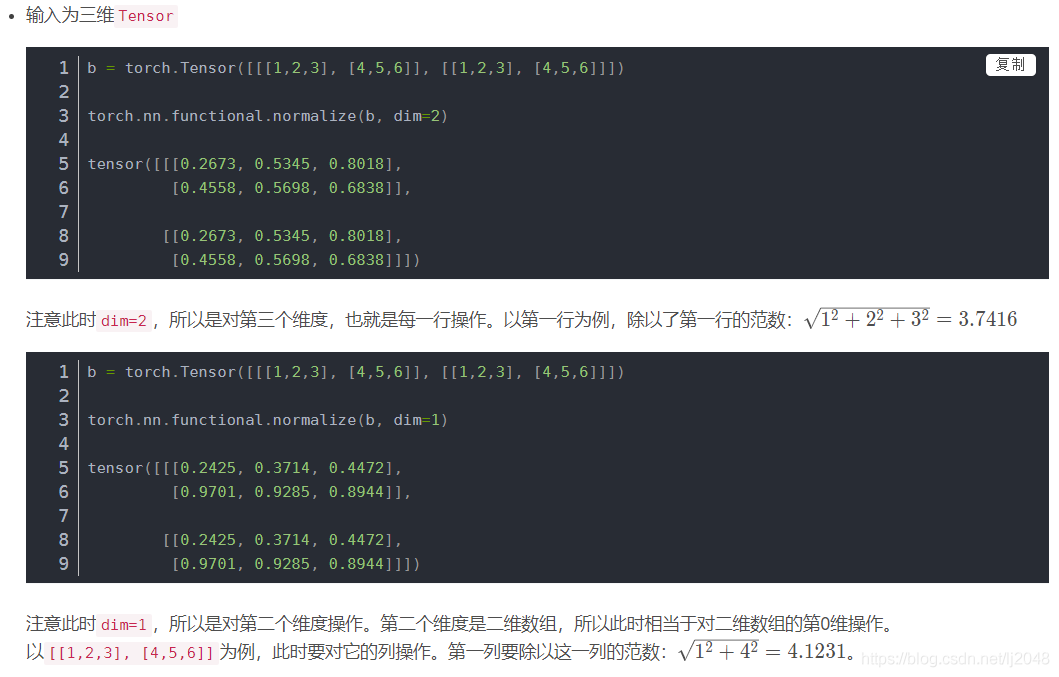
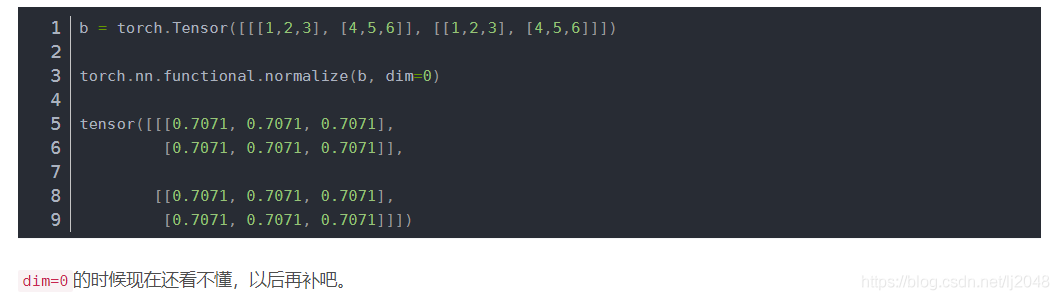
F.normalize / torch.nn.functional.normalize 将某一个维度除以那个维度对应的范数(默认是2范数)
torch.nn.functional.normalize(input, p=2.0, dim=1, eps=1e-12, out=None)
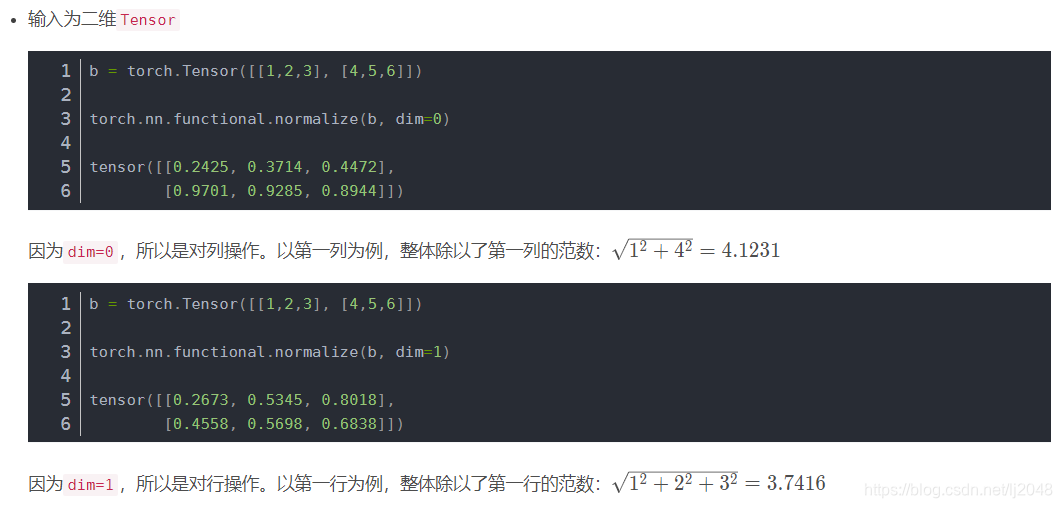
最后dim=0,是1/根号下1平方+1平方,2/根号下2平方+2平方,3/根号下3平方+3平方,所以都是0.7071

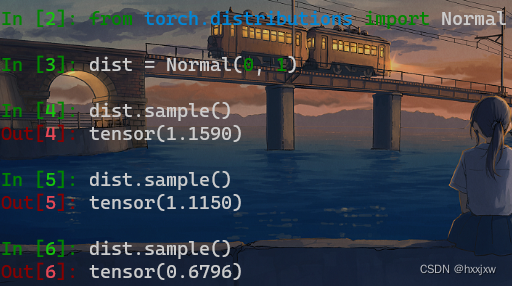
torch.distributions 概率分布和采样相关函数
torch.distributions.Normal()正态分布
Normal(0, 1) 就是期望为0,标准差为1(正态分布的第二个参数应该是方差)
from torch.distributions import Normal dist = Normal(loc=0, scale=1) #loc是μ, scale是σ e = dist.sample()loc是均值(means), scale是标准差σ(sigma)
在低torch版本里这么写:
import torch dis = Normal(torch.Tensor([0.0]), torch.Tensor([1.0])) d = dis.sample()[0]means的形状和sigma的形状可以不一致,遵循广播原理
例如
import torch dis = Normal(torch.Tensor([0.0, 10.0]), torch.Tensor([1.0])) d = dis.sample()设置的高斯分布中sigma虽然只传入了1,这里应该是广播机制,会生成一个二维高斯分布,[N(1,1), N(10, 1)]
对其进行采样dist.sample(),会得到一个数组
那么我有了期望为μ,标准差为σ的概率分布,
对于输入x,怎么获得x在这个概率分布中的概率呢
dist.log_prob(x).exp()
log_prob
log_prob(x)用来计算输入数据x在正太分布中的对应的概率密度的对数
import torch from torch.distributions import Normal dist = Normal(loc=0, scale=1) #loc是μ, scale是σ print(dist.log_prob(torch.Tensor([1.5])))正太分布概率密度函数是
对其取对数可得
得到的值再torch.exp()就是概率密度
pytorch01 torch.distributions.Normal和.log_prob() - 深度学习学不会 - 博客园 (cnblogs.com)

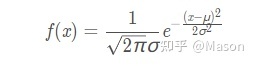
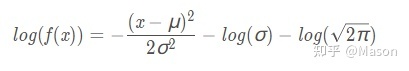
tensor的数据结构
tensor分为头信息区(Tensor)和存储区(Storage)。信息区主要保存着tensor的形状(size)、步长(stride)、数据类型(type)等信息,而真正的数据则保存成连续数组,存储在存储区。torch.long() #将tensor转换为long类型
torch.half() #将tensor转换为半精度浮点类型
torch.int() #将该tensor转换为int类型
torch.double() #将该tensor转换为double(float64)类型
torch.float() #将该tensor转换为float(float32)类型
torch.char() #将该tensor转换为char类型
torch.byte() #将该tensor转换为byte类型
torch.short() #将该tensor转换为short类型tensor.grad & tensor.grad_fn (grad_fn.next_functions)
tensor标量与张量
生成未初始化的数据Torch.empty()、Torch.FloatTensor()、Torch.IntTensor()
tensor的cpu与gpu转换
取tensor的数值 item()
初始化tensor(device,requires_grad)
torch.tensor 和 torch.Tensor的区别
requires_grad_()与requires_grad的区别
判断tensor是否为空见
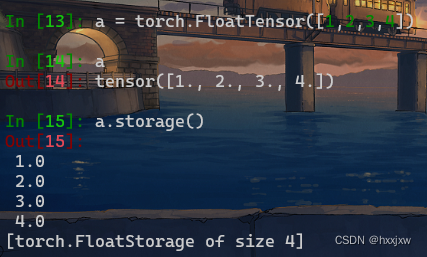
torch.storage
一个torch.Storage是一个单一数据类型的连续一维数组。
每个torch.Tensor都有一个对应的、相同数据类型的存储
例如FloatTensor对应的是torch.FloatStorage
import torch torch.FloatStorage([1,2,3,4,5]) torch.ByteStorage([1,2,3,4,5]) torch.ShortStorage([1,2,3,4,5]) torch.IntStorage([1,2,3,4,5]) torch.LongStorage([1,2,3,4,5]) torch.FloatStorage([1,2,3,4,5]) torch.DoubleStorage([1,2,3,4,5]) torch.ShortStorage([1,2,3,4,5])torch.Storage与torch.Tensor之间的转化
将Tensor转换为Storage非常简单,只需要storage()函数即可
更多可见
torch.frombuffer()
将buffer中的内容转换为tensor
torch.frombuffer(buffer, *, dtype, count=- 1, offset=0, requires_grad=False)关键字参数:
dtype(torch.dtype) -返回张量的所需数据类型。
count(int,可选的) -要读取的所需元素的数量。如果为负,则将读取所有元素(直到缓冲区末尾)。默认值:-1。
offset(int,可选的) -在缓冲区开始时要跳过的字节数。默认值:0。
requires_grad(bool,可选的) -如果 autograd 应该在返回的张量上记录操作。默认值:
False。低版本的写法
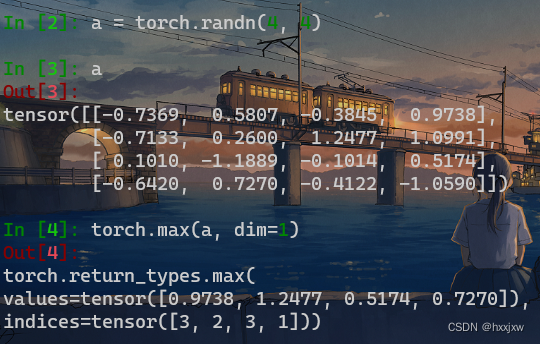
torch.max()
会返回最大值以及最大值的indice
返回indice其实就是用的argmax,是不可导的
torch.max(input, dim, keepdim=False, *, out=None)
torch.log()
以e为底的,即ln
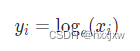

torch.sqrt() 开根号
但是只能对tensor做,常数值不行,常数值用math.sqrt()

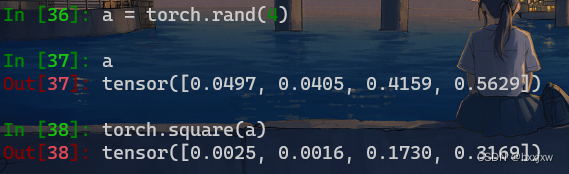
torch.square() 开方
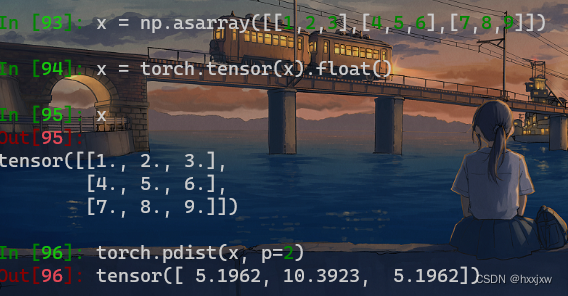
torch.pdist / F.pdist()
计算输入中每对行向量之间的p范数距离。这与
torch.norm(input[:,None]-input, dim=2, p=p])的上三角部分相同,不包括对角线。如果rows是contiguous的话,计算将会faster
torch.nn.functional.pdist(input, p=2)
5.1962 = sqrt((1-4)^2 + (2-5)^2 + (3-6)^2)
10.3923 = sqrt((1-7)^2 + (2-8)^2 + (3-9)^2)
5.1962 = sqrt((4-7)^2 + (5-8)^2 + (6-9)^2)
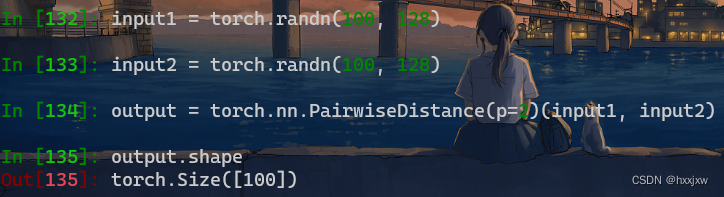
torch.nn.PairwiseDistance()
torch.nn.PairwiseDistance(p=2.0, eps=1e-06, keepdim=False)p=2就是计算欧氏距离,p=1就是曼哈顿距离
计算各自每一行之间的欧式距离。
- 两个输入形状要一样。因为行之间需要相互计算距离。
- 形状必须是[N,D],不能是[D]
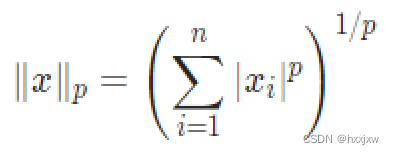
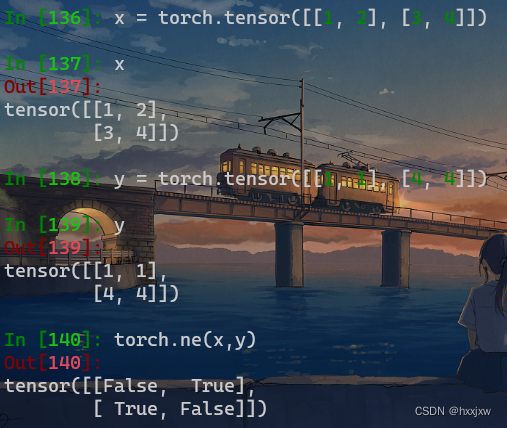
torch.ne() 逐位置比较input和other是否相等
torch.ne(input, other, *, out=None)逐位置比较input和other是否相等
tensor.index_put() 对Tensor不同行、不同列赋值
对二维Tensor不同行、不同列赋值
对三维四维,或者带batch的这些,可以先拍扁,再reshape
Tensor.index_put(indices, values, accumulate=False)将x的第0行的第0、2个元素 与 第1行的第1、3个元素分别替换为[1,2,3,4]
如果accumulate=True,就不是替换了,就是相加了

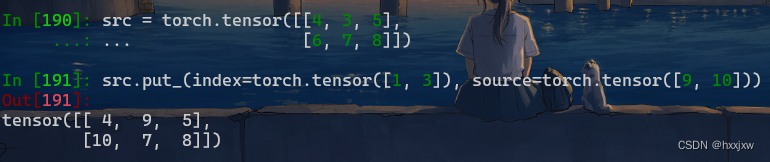
tensor.put_() 将
source中的元素复制到index指定的位置Tensor.put_(index, source, accumulate=False)将
source中的元素复制到index指定的位置。出于索引的目的,self张量被视为一维张量。
index和source需要具有相同数量的元素,但不一定具有相同的形状。如果
accumulate是True,则将source中的元素添加到self。如果累积是False,则如果index包含重复元素,则行为未定义。
这个函数会把src看作是1D向量,即位置0是4,位置1是3,位置2是5,位置3是6......
torch.nan_to_num
torch.nan_to_num(input, nan=0.0, posinf=None, neginf=None, *, out=None)将
input中的NaN、正无穷大和负无穷大值分别替换为nan,posinf和neginf指定的值。默认情况下,NaNs 被替换为 0,正无穷大被替换为input的 dtype 可表示的最大有限值,负无穷大被替换为input的 dtype 可表示的最小有限值。
torch.mean() 求平均值
torch.mean(input, *, dtype=None)

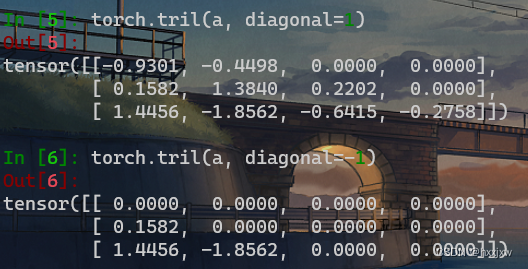
torch.tril() 求 矩阵主对角线的下三角矩阵
其它元素全部为0
torch.tril(input, diagonal=0, *, out=None)
diagonal可以上下移动对角线

torch.triu() 求 矩阵主对角线的上三角矩阵
和torch.tril对应

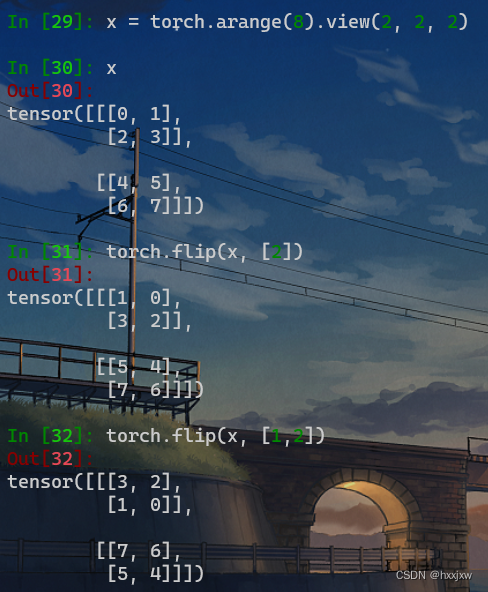
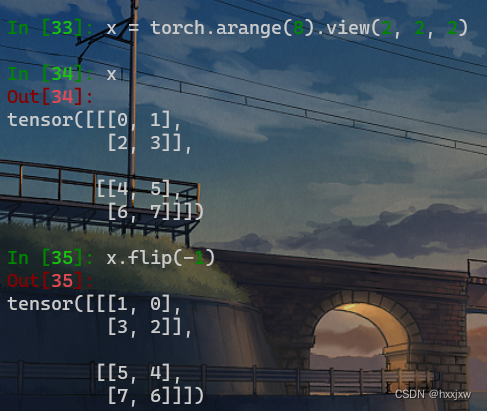
torch.flip() 翻转
torch.flip(input, dims)可以多个维一起翻转
也可以
裁剪 transforms.functional.crop()
torch.erf() 高斯误差函数 & torch.erfinv()
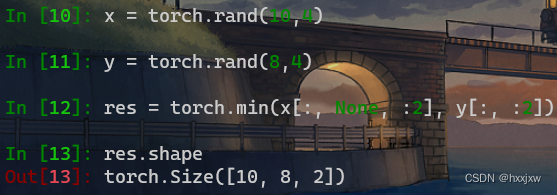
torch.min() / torch.max()的广播机制
torch.max本质上还是要比较两个形状相同的张量的,当两个张量不相同的时候,能通过张量的广播机制,将两者先变成张量一致,再进行比较
torch实现np.nanmean()的功能
tensor[tensor < float('inf')].mean()
torch.quantile() 分位数
分位数是指将数据按照大小顺序排列后,把数据分成几个等份的数值点。具体地,一个数列的第p分位数是这样一个数,它将这个数列分成前 p% 和后 1-p% 两部分,前面的部分中有 p% 的数据比这个数小,后面的部分中有 1-p% 的数据比这个数小。
所以,第一、第二和第三分位数分别为数据的最小值、中位数和最大值。
分位数一般为 0.25 0.5 0.75分位数
torch.quantile(input, q, dim=None, keepdim=False, *, interpolation='linear', out=None)返回
input张量中所有元素的第q个分位数,当第q个分位数位于两个数据点之间时进行线性插值。
torch.bernoulli() 伯努利分布/二项分布
输入是一个概率矩阵,然后它会根据概率得到0或1,结果是一个0/1矩阵
import torch p = torch.tensor([0.3, 0.7]) # 成功的概率分别为0.3和0.7 result = torch.bernoulli(p) # 从伯努利分布中采样,返回一个与p相同形状的张量 print(result) #tensor([0., 1.])














 3332
3332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









