






数据加载及转换
Main.scala
import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object Main { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("linear").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() val file = spark.read.format("csv").option("sep",";").option("header","true").load("house.csv") file.show() } }
选square作为特征变量,预测price
即用square预测price
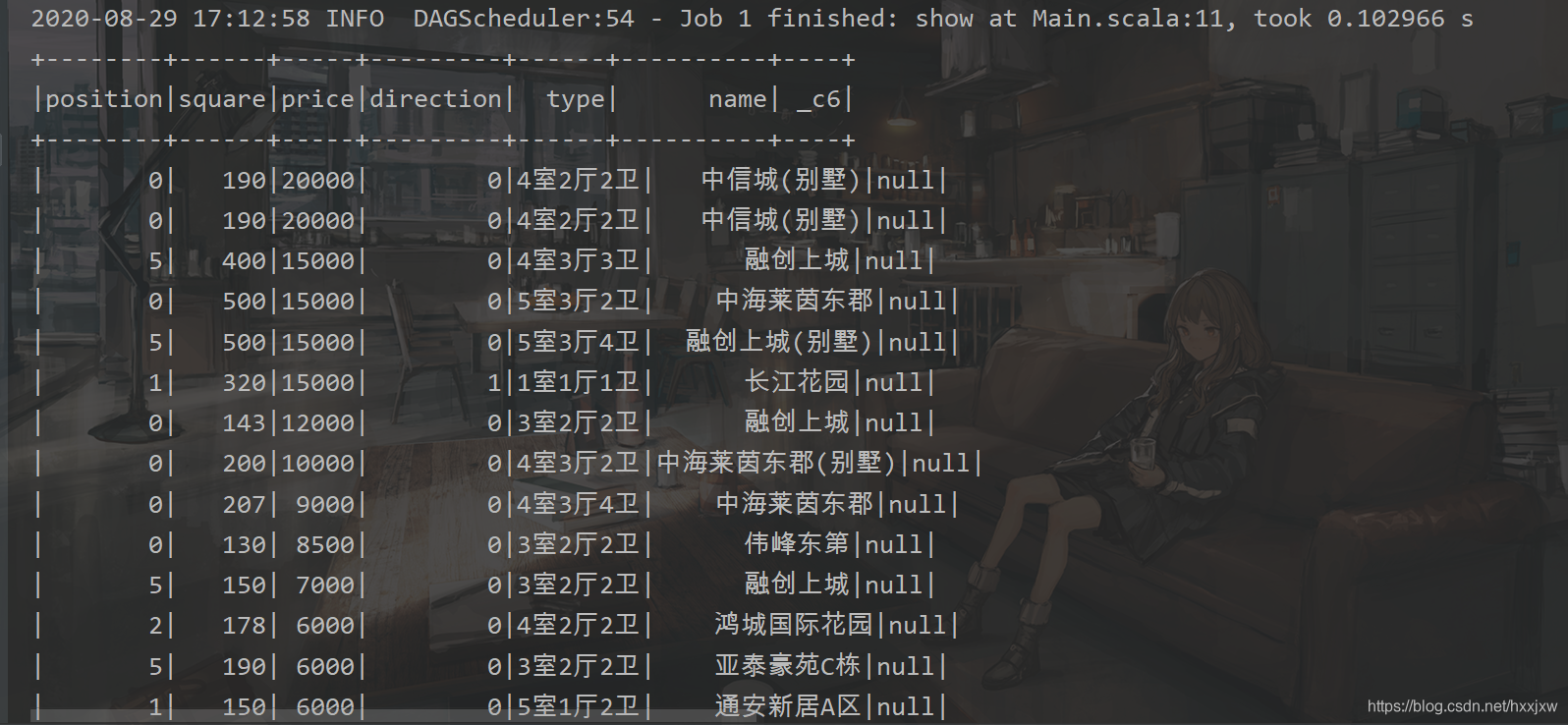
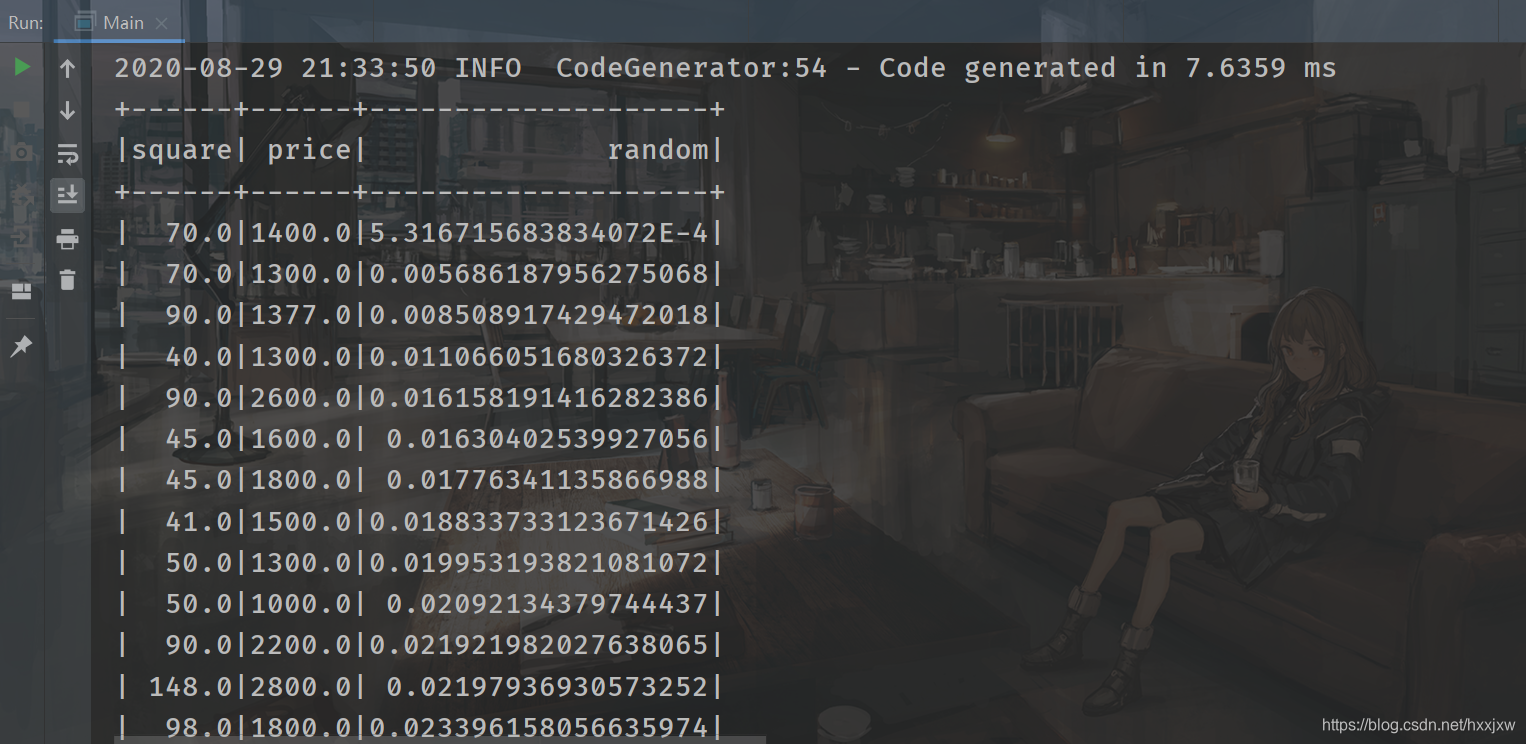
所以有用的列就这两列,我们就把这两列单独提出来
Main.scala
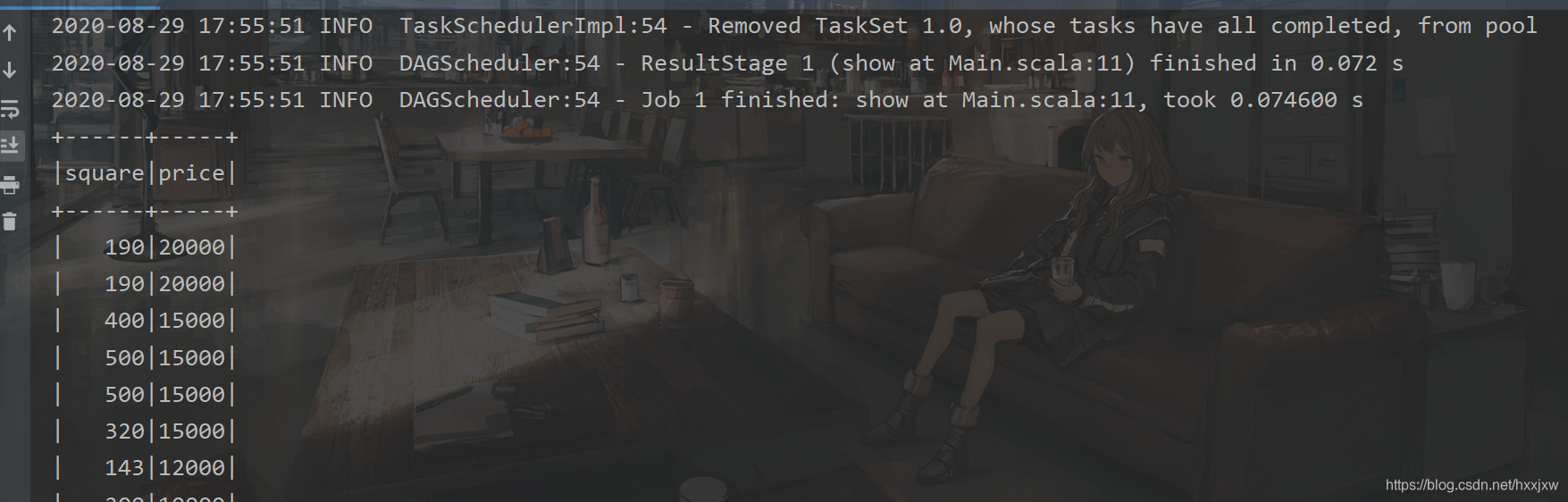
import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object Main { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("linear").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() val file = spark.read.format("csv").option("sep",";").option("header","true").load("house.csv") val data = file.select("square","price").show() } }
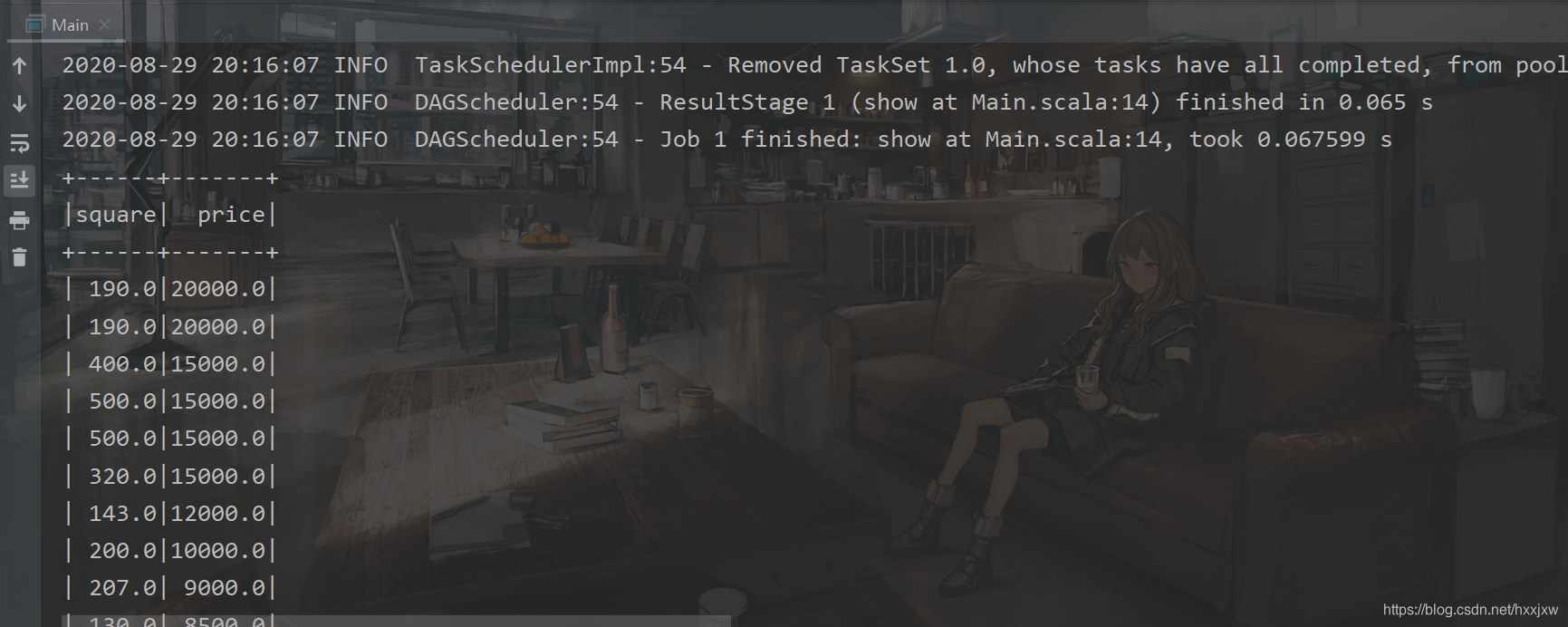
变成字符串来处理
Main.scala
import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object Main { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("linear").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() import spark.implicits._ val file = spark.read.format("csv").option("sep",";").option("header","true").load("house.csv") val data = file.select("square","price").map( row => (row.getAs[String](0).toDouble, row.getString(1).toDouble)) .toDF("square","price").show() //强制类型转换 } }
训练与预测
Main.scala
import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.ml.regression.LinearRegression import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object Main { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("linear").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() val file = spark.read.format("csv").option("sep",";").option("header","true").load("house.csv") import spark.implicits._ val random = new util.Random() val data = file.select("square","price") .map(row => (row.getAs[String](0).toDouble, row.getString(1).toDouble, random.nextDouble())) .toDF("square","price","random") //强制类型转换 .sort("random") //通过添加一列随机数再对随机数排序进行shuffle data.show() } }
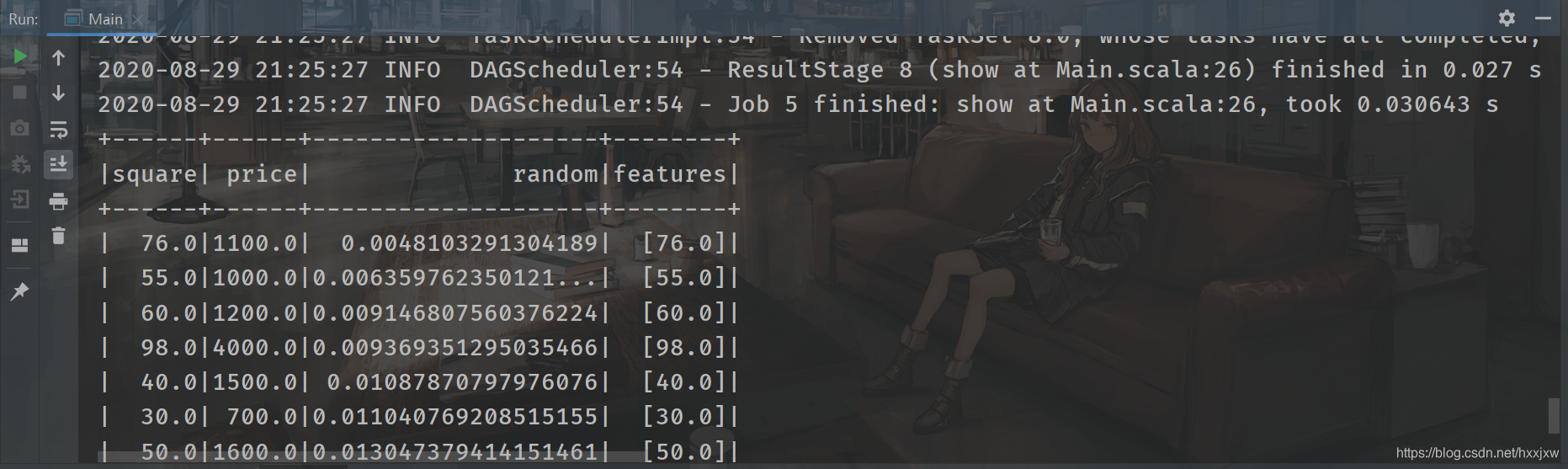
Main.scala
import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.ml.regression.LinearRegression import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object Main { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("linear").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() val file = spark.read.format("csv").option("sep",";").option("header","true").load("house.csv") import spark.implicits._ val random = new util.Random() val data = file.select("square","price") .map(row => (row.getAs[String](0).toDouble, row.getString(1).toDouble, random.nextDouble())) .toDF("square","price","random") //强制类型转换 .sort("random") //通过添加一列随机数再对随机数排序进行shuffle data.show() val assembler = new VectorAssembler() .setInputCols(Array("square")) .setOutputCol("features") val dataset = assembler.transform(data) dataset.show() } }
最终版
Main.scala
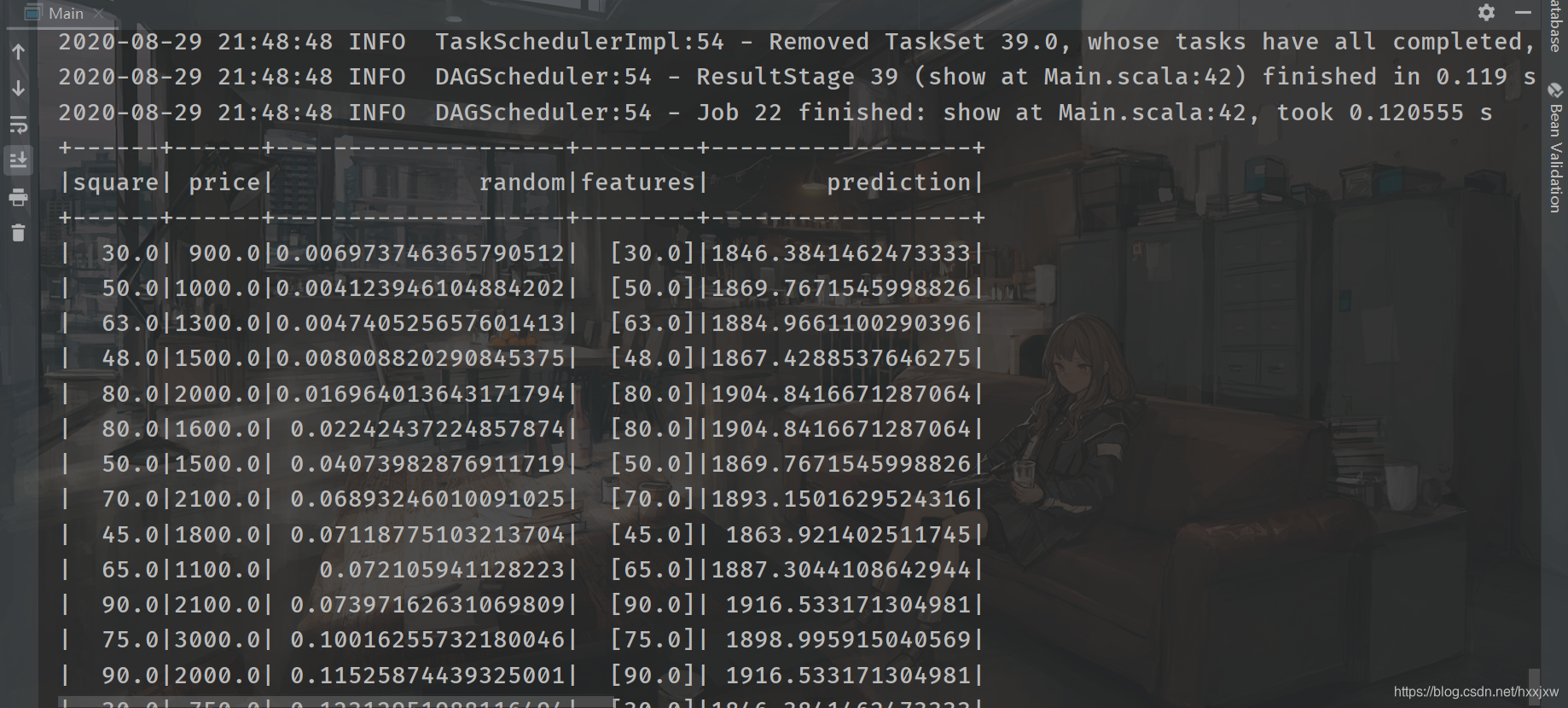
import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.ml.regression.LinearRegression import org.apache.spark.sql.SparkSession import org.apache.spark.{SparkConf, SparkContext} object Main { def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("linear").setMaster("local") val sc = new SparkContext(conf) val spark = SparkSession.builder().config(conf).getOrCreate() val file = spark.read.format("csv").option("sep",";").option("header","true").load("house.csv") import spark.implicits._ val random = new util.Random() val data = file.select("square","price") .map(row => (row.getAs[String](0).toDouble, row.getString(1).toDouble, random.nextDouble())) .toDF("square","price","random") //强制类型转换 .sort("random") //通过添加一列随机数再对随机数排序进行shuffle data.show() val assembler = new VectorAssembler() .setInputCols(Array("square")) .setOutputCol("features") val dataset = assembler.transform(data) dataset.show() //拆分成训练集和测试集 var Array(train, test) = dataset.randomSplit(Array(0.8,0.2),1234L) //train.show() println(test.count()) val regression = new LinearRegression() .setMaxIter(10) //最大迭代次数 .setRegParam(0.3)//设置正则化参数 .setElasticNetParam(0.8)//设置弹性网络参数 val model = regression.setLabelCol("price").setFeaturesCol("features").fit(train) val result = model.transform(test) result.show() /* fit 做训练 transform 做预测 */ } }
预测结果不是很理想
house.csv

















 2408
2408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









