







多租户两种极端实现方式
启用多租户的方法有很多,我不想做一一的介绍,但是有两个极端我们可以考虑一下:
极端一:
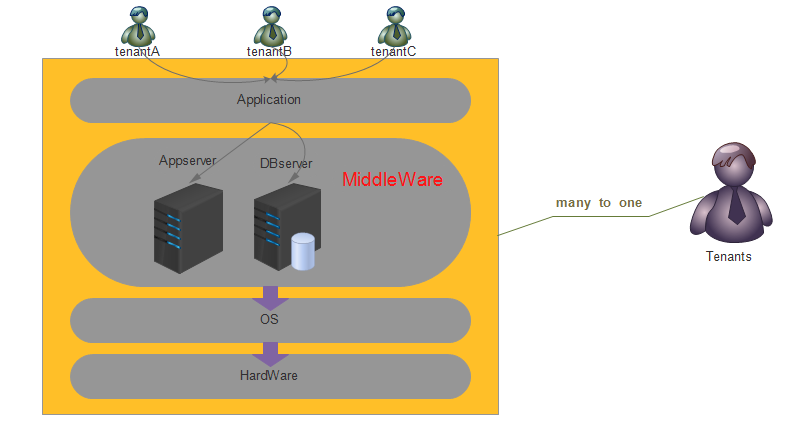
是所有租户共享单一应用程序实例,也就是相同的服务器、中间件和应用程序。实现的方法是用租户标识参数对应用程序的单一实例进行参数化。
图1 在多个租户之间共享应用程序和中间件的单一实例极端二:
是租户在单独的服务器上运行自己的应用程序实例(当前许多 Application Service Provider [ASP] 采用这种方法)。
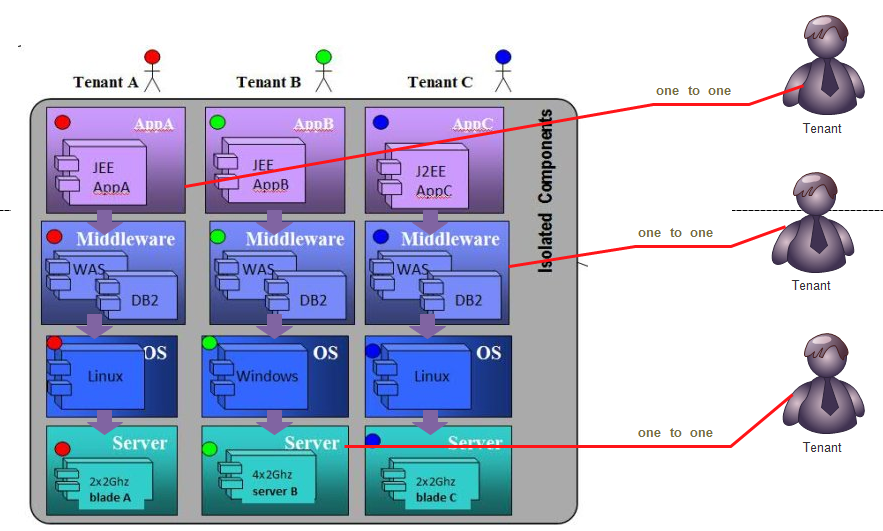
租户只共享数据中心的基础结构(比如供电和制冷),但是使用应用程序、中间件、操作系统和服务器的不同实例。在图 2所示的示例中,租户 A、B 和 C 使用三个不同的应用程序实例 AppA、AppB 和 AppC,它们在与租户相关的中间件实例、操作系统实例和物理服务器上运行。这种方法最适合那些要求为不同的租户提供充分隔离和定制的工作负载和场景
图2 ASP 通过在多个单独的服务器上运行多个实例启用多租户
其实我们经常在这样做,我们为某个A企业开发了一个OA办公系统,当另一个B企业也需要类似的系统时。我们往往在重新发布一个Application实例,供B企业使用,但我们的目的往往是为了简单方便,而不会去考虑为不同的租户提供充分隔离和定制的工作负载和场景。由于极端二对于我们实现上是没有任何问题的,即使是需要一些个性化的配置,由于是两套完全独立的Application,我就就可以随意的改动而不影响其他的企业。所以我们今天的重点是分析极端一的实现方式。极端一的方式中Application只发布一个实例,但可以为多个承租者提供服务。实现这种方式最关键的技术是仙子按多租户的数据隔离。
多租户数据层设计模式
- 通过前面的分析我们知道传统的应用,仅仅服务于单个租户,数据库多部署在企业内部网络环境,对于数据拥有者来说,这些数据是自己“私有”的,它符合自己所定义的全部安全标准。而在云计算时代,随着应用本身被放到云端,导致数据层也经常被公开化,但租户对数据安全性的要求,并不因之下降。同时,多租户应用在租户数量增多的情况下,会比单租户应用面临更多的性能压力。那么多租户在数据层的框架如何在共享、安全与性能间进行取舍。
常见的三种模式
- 独立数据库
- 共享数据库、独立 Schema
共享数据库、共享 Schema、共享数据表
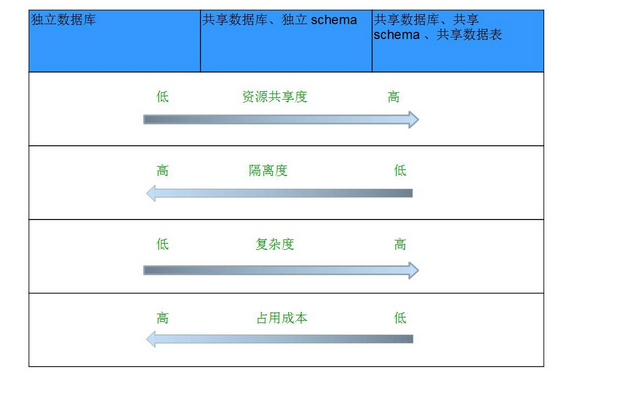
独立数据库是一个租户独享一个数据库实例,它提供了最强的分离度,租户的数据彼此物理不可见,备份与恢复都很灵活;共享数据库、独立 Schema 将每个租户关联到同一个数据库的不同 Schema,租户间数据彼此逻辑不可见,上层应用程序的实现和独立数据库一样简单,但备份恢复稍显复杂; 最后一种模式则是租户数据在数据表级别实现共享,它提供了最低的成本,但引入了额外的编程复杂性(程序的数据访问需要用 tenantId 来区分不同租户),备份与恢复也更复杂。这三种模式的特点可以用一张图来概括:
图 3. 三种部署模式的异同上图所总结的是一般性的结论,而在常规场景下需要综合考虑才能决定那种方式是合适的。例如,在占用成本上,认为独立数据库会高,共享模式较低。但如果考虑到大租户潜在的数据扩展需求,有时也许会有相反的成本耗用结论。
- 而多租户采用的选择,主要是成本原因,对于多数场景而言,共享度越高,软硬件资源的利用效率更好,成本也更低。但同时也要解决好租户资源共享和隔离带来的安全与性能、扩展性等问题。毕竟,也有客户无法满意于将数据与其他租户放在共享资源中。
目前市面上各类数据厂商在多租户的支持上,大抵都是遵循上文所述的这几类模式,或者混合了几种策略,具体的介绍,可以看下面这篇博客进行的详细的介绍:
数据层的多租户浅谈在这篇文章中比较系统全面的介绍了hibernate和eclipselink对于多租户的具体的实现,文章的最后也有源码可以下载,经过简单的配置就能正常的运行。是学习多租户的很好的文章。
学习体会
- 本来我不应该再对此做过多的解释了,但是我还是有一些自己的想法想给大家分享一下。
hibernate
- 首先说hibernate的实现上,在文章中并没有给出独立数据库的实现方式,只是说这种模式可以通过实现 MultiTenantConnectionProvider 接口或继承 AbstractMultiTenantConnectionProvider 类等方式来实现。如果读者认真的分析了代码就会发现对于共享数据库,独立 Schema模式也是需要实现MultiTenantConnectionProvider接口的,其代码如下:
public class SchemaBasedMultiTenantConnectionProvider implements MultiTenantConnectionProvider, Stoppable,
Configurable, ServiceRegistryAwareService {
private final DriverManagerConnectionProviderImpl connectionProvider = new DriverManagerConnectionProviderImpl();
//得到数据库连接
@Override
public Connection getAnyConnection() throws SQLException {
return connectionProvider.getConnection();
}
//关闭数据库连接
@Override
public void releaseAnyConnection(Connection connection) throws SQLException {
connectionProvider.closeConnection(connection);
}
//根据不同用户,Use对应用户的库的链接
@Override
public Connection getConnection(String tenantIdentifier) throws SQLException {
final Connection connection = getAnyConnection();
try {
connection.createStatement().execute("USE " + tenantIdentifier);//重点关注1
} catch (SQLException e) {
throw new HibernateException("Could not alter JDBC connection to specified schema [" + tenantIdentifier
+ "]", e);
}
return connection;//重点关注2
}
@Override
public void releaseConnection(String tenantIdentifier, Connection connection) throws SQLException {
try {
connection.createStatement().execute("USE main");
} catch (SQLException e) {
throw new HibernateException("Could not alter JDBC connection to specified schema [" + tenantIdentifier
+ "]", e);
}
connectionProvider.closeConnection(connection);
}
……
}
- 在重点关注1中其实就是使用当前的connection执行一下“use Schema名”,这样我们下面使用这个链接做的操作就会在新的Schema下操作了。
- 再看重点关注2返回值是一个connection,如果是共享数据库独立schema使用的connection只需要有一个,但如果想实现独立数据库的隔离,其实只需要改变getConnection方法的实现,根据tenantdentifier的值生成不同的connection就能实现了。
多租户下的 Hibernate 缓存
- 我们还应该注意文章中对于多租户下hibernate缓存的说明,为了让读者加深印象我这里也粘贴过来。
- 基于独立 Schema 模式的多租户实现,其数据表无需额外的 tenant_id。通过 ConnectionProvider 来取得所需的 JDBC 连接,对其来说一级缓存(Session 级别的缓存)是安全的可用的,一级缓存对事物级别的数据进行缓存,一旦事物结束,缓存也即失效。但是该模式下的二级缓存是不安全的,因为多个 Schema 的数据库的主键可能会是同一个值,这样就使得 Hibernate 无法正常使用二级缓存来存放对象。例如:在 hotel_1 的 guest 表中有个 id 为 1 的数据,同时在 hotel_2 的 guest 表中也有一个 id 为 1 的数据。通常我会根据 id 来覆盖类的 hashCode() 方法,这样如果使用二级缓存,就无法区别 hotel_1 的 guest 和 hote_2 的 guest。
- 在共享数据表的模式下的缓存, 可以同时使用 Hibernate的一级缓存和二级缓存, 因为在共享的数据表中,主键是唯一的,数据表中的每条记录属于对应的租户,在二级缓存中的对象也具有唯一性。Hibernate 分别为 EhCache、OSCache、SwarmCache 和 JBossCache 等缓存插件提供了内置的 CacheProvider 实现,读者可以根据需要选择合理的缓存,修改 Hibernate 配置文件设置并启用它,以提高多租户应用的性能。
eclipseLink
- 对于eclipseLink,他完整实现了jpa标准,这也对我们实现企业级的应用提供了保障,在下一篇文章中我们也会针对于这一点展开详细的说明。















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









