







均值、方差、标准差、均方根、均方误差、均方根误差的区别与联系
The mean, variance, and standard deviation are the most basic statistical measures. The mean均值
μ
x
\mu_{x}
μx, and variance方差
σ
x
2
\sigma_{x}^{2}
σx2, of a set of
n
n
n observations,
x
i
x_{i}
xi, are defined as
μ
x
=
1
n
∑
i
=
1
n
x
i
,
σ
x
2
=
1
n
∑
i
=
1
n
(
x
i
−
μ
x
)
2
=
1
n
∑
i
=
1
n
x
i
2
−
μ
x
2
.
\mu_{x}=\frac{1}{n} \sum_{i=1}^{n} x_{i}, \quad \sigma_{x}^{2}=\frac{1}{n} \sum_{i=1}^{n}\left(x_{i}-\mu_{x}\right)^{2}=\frac{1}{n} \sum_{i=1}^{n} x_{i}^{2}-\mu_{x}^{2} .
μx=n1i=1∑nxi,σx2=n1i=1∑n(xi−μx)2=n1i=1∑nxi2−μx2.
They may also be written as
μ
(
x
)
\mu(x)
μ(x) and
σ
2
(
x
)
\sigma^{2}(x)
σ2(x), respectively The standard deviation (SD) 标准差
σ
x
\sigma_{x}
σx or
σ
(
x
)
\sigma(x)
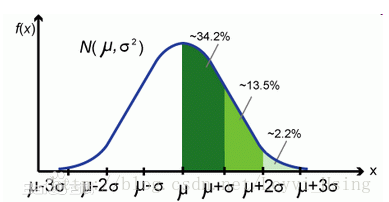
σ(x), is simply the square root of the variance, 既然有了方差来描述变量与均值的偏离程度,那又搞出来个标准差干什么呢?原因是:方差与我们要处理的数据的量纲是不一致的,虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。举个例子:一个班级里有60个学生,平均成绩是70分,标准差是9,方差是81,成绩服从正态分布,那么我们通过方差不能直观的确定班级学生与均值到底偏离了多少分,通过标准差我们就很直观的得到学生成绩分布在[61,79]范围的概率为0.6826,即约等于下图中的34.2%*2
while the root mean square (RMS) is
r
x
=
1
n
∑
i
=
1
n
x
i
2
.
r_{x}=\sqrt{\frac{1}{n} \sum_{i=1}^{n} x_{i}^{2}} .
rx=n1i=1∑nxi2.
The mean and variance form part of a wider set of statistical measures called moments. The
k
th
k^{\text {th }}
kth -order moment (k阶矩)
m
k
m_{k}
mk, and central moment**(k阶中心矩)
c
k
c_{k}
ck**, are defined as
m
k
(
x
)
=
1
n
∑
i
=
1
n
x
i
k
,
c
k
(
x
)
=
1
n
∑
i
=
1
n
(
x
i
−
μ
x
)
k
.
m_{k}(x)=\frac{1}{n} \sum_{i=1}^{n} x_{i}^{k}, \quad c_{k}(x)=\frac{1}{n} \sum_{i=1}^{n}\left(x_{i}-\mu_{x}\right)^{k} .
mk(x)=n1i=1∑nxik,ck(x)=n1i=1∑n(xi−μx)k.
Note that
c
1
c_{1}
c1 is always zero. The mean is the first-order moment and the variance the second-order central moment. The RMS is the square root of the second-order moment. The third-order central moment is known as the skew.请注意,
c
1
c_{1}
c1始终为零,均值是一阶矩,方差是二阶中心矩,均方根是二阶矩的平方根,三阶中心力矩称为偏斜。
Suppose the observations,
x
i
x_{i}
xi, are taken from a population with distribution
X
X
X. Unbiased estimates of the mean,
μ
X
\mu_{X}
μX, and variance,
σ
X
2
\sigma_{X}^{2}
σX2, of the population’s distribution are
μ
^
X
=
μ
x
,
σ
^
X
2
=
n
n
−
1
σ
x
2
.
\hat{\mu}_{X}=\mu_{x}, \quad \hat{\sigma}_{X}^{2}=\frac{n}{n-1} \sigma_{x}^{2} .
μ^X=μx,σ^X2=n−1nσx2.
**一组向量观测值的平均值就是各分量平均值的向量,向量分布的方差的等价物是协方差矩阵。**The mean of a set of vector observations is simply the vector of the means of the components. The equivalent of the variance for a vector distribution is the covariance matrix,
C
\mathbf{C}
C (P may also be used). If
x
\mathbf{x}
x is an
m
m
m-component vector,
C
x
\mathbf{C}_{\mathbf{x}}
Cx is an
m
×
m
m \times m
m×m matrix. A covariance matrix is symmetric with the diagonal elements corresponding to the variances of the components of the vector it describes and the off-diagonal elements giving the covariance of each pair of components.Where the components of the vector are uncorrelated, the off diagonal elements (非对角元素)of
C
\mathbf{C}
C will tend to zero as the number of observations increases.(协方差矩阵是对称的,对角线元素对应于它所描述的矢量的分量的方差,非对角线元素给出每对分量的协方差。在向量分量不相关的情况下,随着观测次数的增加,
C
\mathbf{C}
C的非对角线元素将趋于零) The mean,
μ
x
\boldsymbol{\mu}_{\mathbf{x}}
μx, and covariance,
C
x
\mathbf{C}_{\mathbf{x}}
Cx, of a set of
n
n
n observations,
x
i
\mathbf{x}_{i}
xi, are
μ
x
=
1
n
∑
i
=
1
n
x
i
,
C
x
=
1
n
∑
i
=
1
n
(
x
i
−
μ
x
)
(
x
i
−
μ
x
)
T
=
1
n
∑
i
=
1
n
x
i
x
i
T
−
μ
x
μ
x
T
.
\boldsymbol{\mu}_{\mathbf{x}}=\frac{1}{n} \sum_{i=1}^{n} \mathbf{x}_{i}, \quad \mathbf{C}_{\mathbf{x}}=\frac{1}{n} \sum_{i=1}^{n}\left(\mathbf{x}_{i}-\boldsymbol{\mu}_{\mathbf{x}}\right)\left(\mathbf{x}_{i}-\boldsymbol{\mu}_{\mathbf{x}}\right)^{\mathrm{T}}=\frac{1}{n} \sum_{i=1}^{n} \mathbf{x}_{i} \mathbf{x}_{i}^{\mathrm{T}}-\boldsymbol{\mu}_{\mathbf{x}} \boldsymbol{\mu}_{\mathbf{x}}^{\mathrm{T}} .
μx=n1i=1∑nxi,Cx=n1i=1∑n(xi−μx)(xi−μx)T=n1i=1∑nxixiT−μxμxT.
Higher-order moments can also describe vector data, noting that a
k
th
k^{\text {th }}
kth -order moment or central moment of a vector is a
k
th
k^{\text {th }}
kth -order tensor.高阶矩也可以描述向量数据,注意向量的
k
k
k阶矩或中心矩是
k
k
k阶张量。
均方误差、均方根误差
**均方根误差RMSE:**各个数据偏离真实值的距离的平方和,再开方
**均方误差MSE:**各个数据偏离真实值的距离的平方和
**标准差:**各个数据偏离均值的距离的平方,再开方(也叫均方差)
**方差:**各个数据偏离均值的距离的平方
M
S
E
=
∑
(
x
i
−
x
^
i
)
2
N
R
M
S
E
=
1
N
∑
(
x
i
−
x
^
i
)
2
\begin{array}{c} M S E=\frac{\sum\left(x_{i}-\hat{x}_{i}\right)^{2}}{N} \\ R M S E=\sqrt{\frac{1}{N} \sum\left(x_{i}-\hat{x}_{i}\right)^{2}} \end{array}
MSE=N∑(xi−x^i)2RMSE=N1∑(xi−x^i)2
均方根值(RMS):也称有效值
X
R
M
S
=
1
N
(
X
1
2
+
X
2
2
+
…
X
N
2
)
X_{R M S}=\sqrt{\frac{1}{N}\left(X_{1}^{2}+X_{2}^{2}+\ldots X_{N}^{2}\right)}
XRMS=N1(X12+X22+…XN2)
比如幅度为100V而占空比为0.5的方波信号,如果按平均值计算,它的电压只有50V,而按均方根值计算则有70.71V。这是为什么呢?举一个例子,有一组100伏的电池组,每次供电10分钟之后停10分钟,也就是说占空比为一半。如果这组电池带动的是10Ω电阻,供电的10分钟产生10A的电流和1000W的功率,停电时电流和功率为零。
也就是说均方根值反映的是有效值而不是平均值,它具有一定的实际(物理)意义。**均方误差(Mean Squared Error)、均方根误差(Root Mean Square Error)**在公式形式上与方差、标准差并没有太大区别,但是从物理意义上有明显差异。区别在于前者应用情景存在一个真实值,其衡量的是各数据偏离真实值的情况,
















 6876
6876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









