







 本文详细介绍了UTF-16编码,包括其历史、代理机制、编码规则和计算方法。UTF-16作为Unicode的一种变长编码方式,通过代理对处理增补平面的码点,同时探讨了字节序问题和在实际应用中的优缺点。
本文详细介绍了UTF-16编码,包括其历史、代理机制、编码规则和计算方法。UTF-16作为Unicode的一种变长编码方式,通过代理对处理增补平面的码点,同时探讨了字节序问题和在实际应用中的优缺点。
Unicode编码详解(四):UTF-16编码
本文为原创文章,转载请注明出处,或注明转载自“黄邦勇帅(原名:黄勇)
本文是对《C++语法详解》一书相关章节的增补,以增强读者对字符的理解,因为《C++语法详解》引用的标准过于老旧。
《C++语法详解》网盘地址:
https://pan.baidu.com/s/1dIxLMN5b91zpJN2sZv1MNg
本文摘自本人所作《Unicode编码和双向算法(bidi)详解》网盘地址
链接:https://pan.baidu.com/s/1LLKv22jQPmeba1XUCm0xoQ?pwd=a3x8
提取码:a3x8
有兴趣的读者可参阅本人所著《C++语法详解》一书,电子工业出版社出版,该书语法示例短小精悍,对查阅C++知识点相当方便,并对语法原理进行了透彻、深入详细的讲解,可确保读者彻底弄懂C++的原理,彻底解惑C++,使其知其然更知其所以然。此书是一本全面了解C++不可多得的案头必备图书。
由于本人能力有限,文中难免有错漏之处,望广大读者指出更正,不胜感激
注意:若对本文的专业术语不了解,请参阅本系列文章(一)和(二)
一、UTF-16编码简介
1、
UTF-16是变长编码方式,每个字符编码为2或4字节。
2、历史
- UTF-16编码源于UCS-2,是Unicode最早的编码方式。
- UCS-2编码仅覆盖了基本平面(即BMP,第0平面)中的码点,使用固定的两字节将字符编号(类似于Unicode中的码点值)直接映射为字符编码,中间未经过任何的编码算法转换。
- 很明显,16位的二进制位(范围为0x0000 ~ 0xFFFF)无法表示Unicdoe引入的增补平面中的码点(平面1 ~ 16,码点范围为0x10000~0x10FFFF),为此,Unicode在UTF-16编码中使用“代理(代替)机制”来解决这个问题,代理机制使用4个字节来表示增补平面中的码点,从而使UTF-16成为一种变长编码方式。
- 因此,若软件仅支持UCS-2编码,则意味着仅支持UCS字符集或Unicode字符集基本平面中的字符,而不支持增补平面中的字符。
二、代理(代替)机制与UTF-16编码规则
1、代理机制的基本思想
代理可简单理解为代替,其基本思想就是使用两个基本平面中未定义(或未使用)的码点合起来代替一个增补平面的码点。
2、代理机制的基本规则
- 基本平面中的字符(除U+D800~U+DFFF外)仍然使用固字两字节直接映射的方式编码,即,基本平面字符的字符编号(码点值)就是字符编码。
- 增补平面的字符使用“代理机制”这一编码算法进行编码,使用代理机制后需要使用4字节来表示Unicode增补平面中的码点,因此,UTF-16也是一种变长编码方式。
3、代理对和代理区
-
代理对是指基本平面中用来代替增补平面码点的两个码点,也就是说,代理对是一对(即,两个)码点值。
-
代理区
-
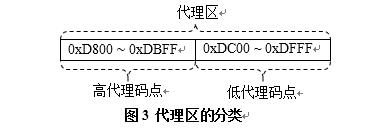
- 基本平面中用来代替增补平面码点的未使用的码点区域被称为代理区,其码点范围为0xD800 ~ 0xDFFF,共2048个码点,
-
- 代理区又分为高代理码点(或称为高代理码元,范围为0xD800 ~ 0xDBFF)和低代理码点(或称为低代理码元,范围为0xDC00 ~ 0xDFFF),图3为代理区的分类。
-
- 需要注意的是,代理区中的码点都未定义字符,这些码点主要用于代理增补平面中的码点。假设为代理区中的码点指定了字符,那么一个代理区中的码元,到底是表示基本平面的字符呢还是增补平面中的字符的代理码元呢?这就产生了冲突,所以,为避免冲突,代理区中的码点都未定义字符。
- 需要注意的是,代理区中的码点都未定义字符,这些码点主要用于代理增补平面中的码点。假设为代理区中的码点指定了字符,那么一个代理区中的码元,到底是表示基本平面的字符呢还是增补平面中的字符的代理码元呢?这就产生了冲突,所以,为避免冲突,代理区中的码点都未定义字符。
4、UTF-16编码规则
把高代理码点和低代理码点合起来组成“代理对”,使用代理对来代替增补平面的码点,代理对刚好可完全表示增补平面内的所有码点(原因见后文)。比如,增补平面的第一个码点0x10000的UTF-16编码是0xD800 DC00,同理,第二个码点0x10001的UTF-16编码是0xD800 DC01,其余以此类推。
三、UTF-16编码方法
1、方法1:查表
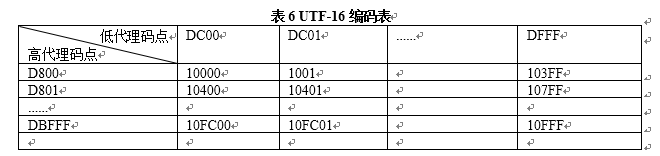
根据UTF-16的编码规则可制出如表6所示的一个表格,然后通过查表的方式查找增补字符的编码,但这种方法非常麻烦,实际编码时并不使用。
2、方法2:计算法
①、将增补字符的码点值减去0x10000,得到一个20位长的二进制数
②、将得到的20位长二进制数拆分为高10位比特和低10位比特
③、20位长的高10位比特加上0xD800得到第一个代理码点,即高代理码点
④、20位长的低10位比特加上0xDC00得到第二个代理码点,即低代理码点
⑤、将得到的高代理码点和低代理码点组合成“代理对”,便得到了增补字符的UTF-16编码
⑥、示例:求增补平面码点值为U+10437的UTF-16编码
-
将0x10437减去0x10000,得到0x00437,二进制为0000 0000 0100 0011 0111
-
将高10位,即0000 0000 01加上0xD800(二进制为1101 1000 0000 0000),得到高代理码点为:0xD801(二进制为1101 1000 0000 0001)
-
将低10位,即00 0011 0111加上0xDC00(二进制为1101 1100 0000 0000),得到低代理码点为:0xDC37(二进制为1101 1100 0011 0111)
-
将高代理码点和低代理码点组合成代理对得到UTF-16编码为0xD801 DC37
3、方法3:二进制位填补法
①、原理
高代理码点的起始值0xD800(二进制为1101 1000 0000 0000)和低代理码点的起始值0xDC00(二进制为1101 1100 0000 0000),可发现,他们的前6位分别为110110和110111,而后10位都是0,总共有20位(220=1048576),刚好可表示增补平面中的所有码点(0x10000 ~ 0x10FFFF,共220=1048576个码点),若利用代理码点的这20位来表示增补码点,则高代理码点的范围为1101 1000 0000 0000(0xD800) ~ 1101 1011 1111 1111(0xDBFF),低代理码点的范围为1101 1100 0000 0000(0xDC00) ~ 1101 1111 1111 1111(0xDFFF),刚好在高代理码点和低代理码点的范围内。因此,可利用填补二进制位的方法来编码UTF-16
②、步骤1:
将高代理码点和低代理码点分别展开为如图4所示的形式,其中高代理单元的110110和低代理单元的110111是固定不变的数(定数),p和x是变数,去掉定数后组合起来就是pppp xxxx xxxx xxxx xxxx,共20位,刚好可表示全部增补码点,其中pppp表示16个增补平面的编码(24=16),紧接着的16个x表示某个增补平面内的码点。

③、步骤2、
将增补字符的码点值减去0x10000,得到一个20位长的二进制数
④、步骤3、
将得到的20位长二进制数依次填补步骤1中的变数便得到UTF-16的编码
⑤、示例:
求增补平面码点值为U+10437的UTF-16编码
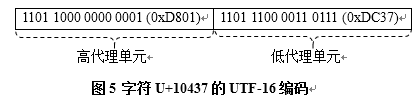
- 将0x10437减去0x10000,得到0x00437,二进制为0000 0000 0100 0011 0111
- 将0000 0000 0100 0011 0111依次填补高代理单元和低代理单元中的变数(如图5所示),得到其编码为0xD801
DC37
四、字节序问题
UTF-16编码后的码元序列在映射为物理意义上的字节序列时,又分为UTF-16BE (大端序),UTF-16LE (小端序)两种情况,大端序和小端序又分为带有字节序标记(with BOM)和不带字节序标记(without BOM)两种情形。比如,“ABC”这三个字符的UTF-16编码(码元序列)为:00 41 00 42 00 43;其对应的各种字节序列如表7所示:

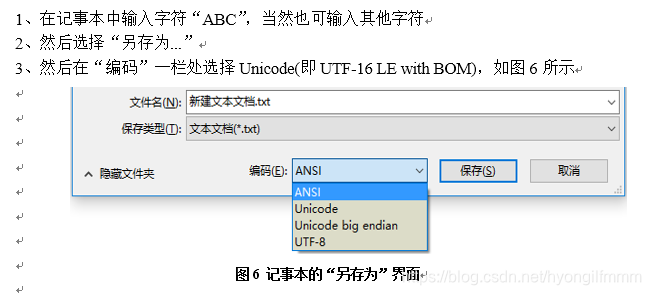
五、在记事本中使用UTF-16编码

六、UTF-16编码的优缺点及特点



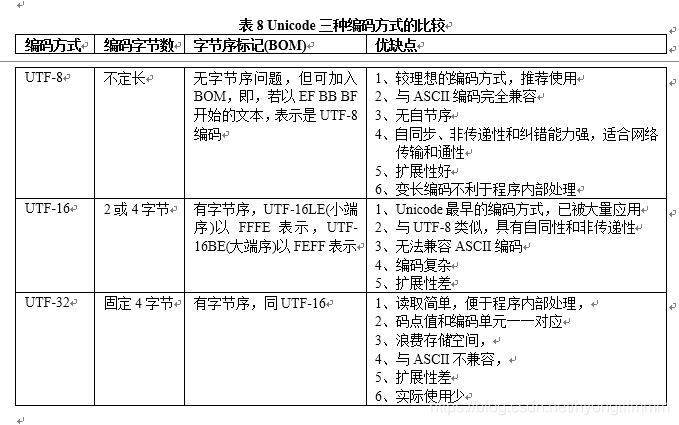
九、Unicode编码方式总结
代码页、内码、外码、汉字编码简介
本文作者:黄邦勇帅(原名:黄勇)


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









