






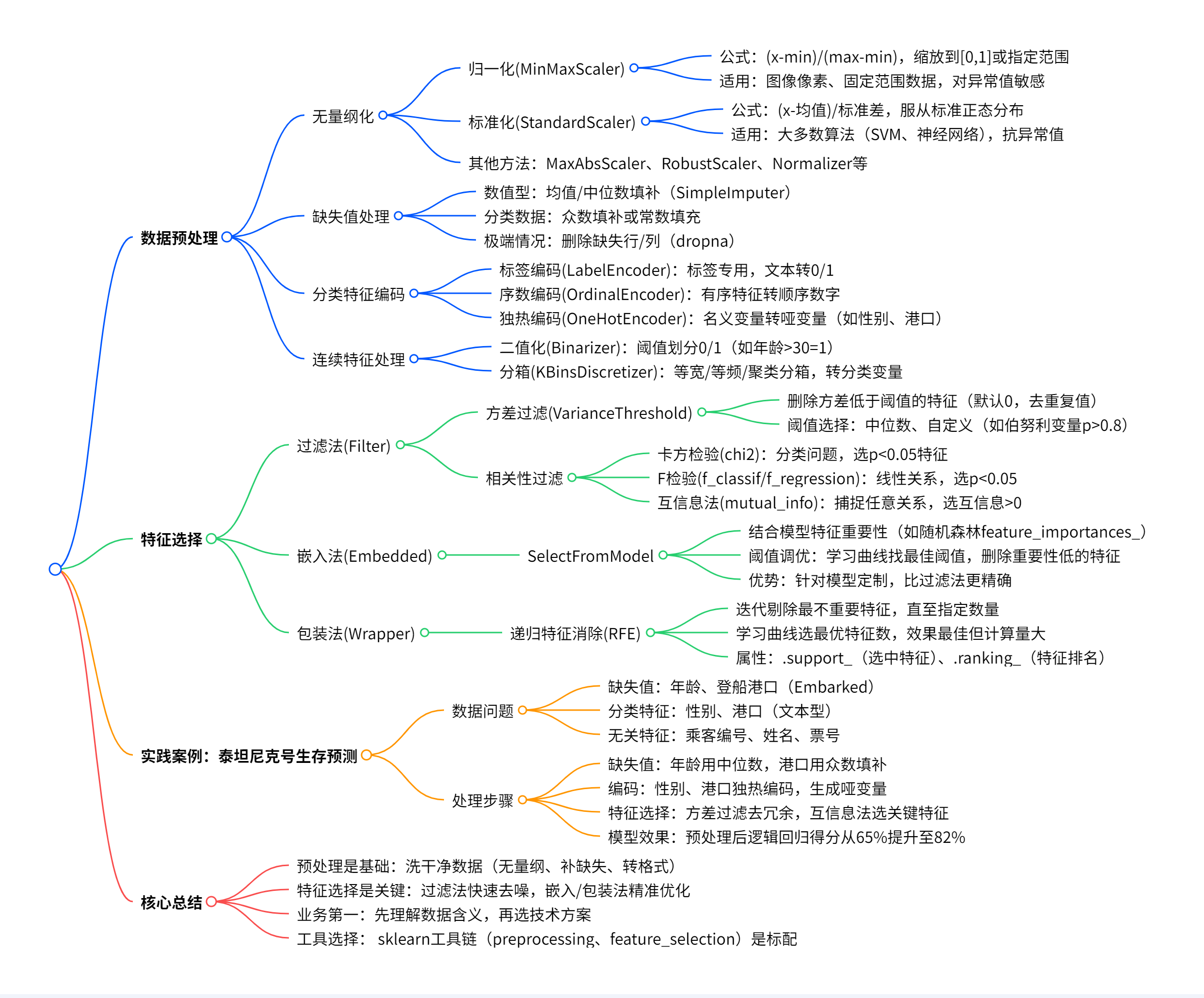
一、数据预处理:给数据洗个澡🛁
想象一下,你拿到的原始数据可能有缺失、单位混乱、文字标签…… 就像刚跑完马拉松的脏衣服,必须洗干净才能用!
1. 无量纲化:统一数据 “尺码”👕
-
归一化(MinMaxScaler) ✨ 把数据缩到 [0,1] 区间,公式是\((x - 最小值)/(最大值 - 最小值)\)。 👉 适合图像像素、固定范围数据,比如把年龄缩到 0-1,但遇到异常值(比如 100 岁的寿星)容易 “挤成一团”。
-
标准化(StandardScaler) ✨ 让数据变成均值为 0、方差为 1 的 “标准身材”,公式是\((x - 均值)/标准差\)。 👉 大多数算法的 “心头好”,比如 SVM、神经网络,对异常值更宽容,适用范围广。
💡 小贴士:决策树不需要无量纲化,它 “不拘小节”,只关心数据相对大小~
2. 缺失值处理:填坑还是丢坑?🪤
- 数值型数据:用中位数(抗噪)或均值填补,比如年龄缺失了,用中间年龄填,比平均年龄更靠谱;
- 分类数据:用众数(出现最多的值),比如 “登船港口” 缺失了,就填最常见的港口;
- 极端情况:直接填 0?小心 “0” 可能有特殊含义,别乱填哦~
3. 分类特征编码:让计算机听懂 “人话”👄
- 标签编码(LabelEncoder):给标签(比如 “存活”=1,“遇难”=0)转数字,只适用于标签!
- 序数编码(OrdinalEncoder):给有顺序的特征(比如学历:小学 = 0,初中 = 1)转数字,保留顺序关系;
- 独热编码(OneHotEncoder):给无顺序的特征(比如性别 “男 / 女”)拆成两列 0/1,避免计算机误解为 “男 = 1 比女 = 0 大”。
4. 连续特征处理:二值化与分段📊
- 二值化:设定阈值,比如年龄 > 30 岁 = 1,否则 = 0,适合简化问题;
- 分箱:把连续数据切成段,比如年龄分 “0-20”“20-40”“40+”,用等宽、等频或聚类分箱,让模型更容易理解。
二、特征选择:给数据挑挑刺🔍
洗干净的数据可能还有 “刺”—— 无关特征、冗余特征,必须挑出来!
1. 过滤法(Filter):用统计量粗筛
- 方差过滤:删掉方差接近 0 的特征(比如所有值都一样,毫无存在感);
- 相关性过滤:用卡方检验(分类问题)、F 检验(线性关系)、互信息法(任意关系)筛选和标签相关的特征,比如 “乘客编号” 这种和 “是否存活” 无关的直接扔掉~
2. 嵌入法(Embedded):让模型自己选✨
- 结合具体模型(如随机森林的
feature_importances_),按特征重要性筛选,比过滤法更精准,但计算量稍大。比如随机森林觉得重要的特征,优先留下!
3. 包装法(Wrapper):反复训练选最优🎁
- 递归特征消除(RFE):每次剔除最不重要的特征,直到剩下指定数量,效果最好但最慢,适合小数据集追求极致精度。
三、实战案例:泰坦尼克号生存预测🚢
数据问题:
- 缺失值:年龄、登船港口缺失;
- 分类特征:性别、登船港口是文字;
- 无关特征:乘客编号、姓名、票号没啥用。
处理步骤:
-
缺失值处理:
python
运行
from sklearn.impute import SimpleImputer # 年龄用中位数填补 imp_median = SimpleImputer(strategy="median") data["Age"] = imp_median.fit_transform(data[["Age"]]) # 登船港口用众数填补 imp_mode = SimpleImputer(strategy="most_frequent") data["Embarked"] = imp_mode.fit_transform(data[["Embarked"]]) -
分类特征编码:
python
运行
from sklearn.preprocessing import OneHotEncoder encoder = OneHotEncoder(sparse=False, drop="first") # 避免多重共线性 encoded_features = encoder.fit_transform(data[["Sex", "Embarked"]]) data = pd.concat([data, pd.DataFrame(encoded_features)], axis=1) data.drop(["Sex", "Embarked", "PassengerId", "Name", "Ticket"], axis=1, inplace=True) -
特征选择:
python
运行
from sklearn.feature_selection import VarianceThreshold, SelectKBest, mutual_info_classif # 方差过滤 selector_var = VarianceThreshold() X_var = selector_var.fit_transform(X) # 互信息法选前5个特征 selector_mi = SelectKBest(score_func=mutual_info_classif, k=5) X_selected = selector_mi.fit_transform(X_var, y) -
模型效果:
- 原始数据(未处理):逻辑回归得分 65%;
- 处理后数据:得分提升至 82%!
四、避坑指南⚠️
- 业务优先:先和数据提供者聊!比如 “乘客编号” 虽然是数字,但本质是 ID,直接删;
- 编码注意:有序特征用序数编码,无序特征用独热编码,别搞混;
- 计算成本:数据量大先用过滤法(快),小数据用包装法(精);
- 可视化辅助:画特征重要性图、学习曲线,直观判断效果。
五、总结:数据好,模型才好🚀
数据预处理和特征工程就像给模型 “打地基”,地基稳了,模型才能盖得高!记住:
- 预处理:洗干净数据,处理缺失、编码、无量纲化;
- 特征选择:挑出有用特征,过滤法快、嵌入法准、包装法精;
- 实战为王:多练泰坦尼克号、鸢尾花等案例,熟能生巧~

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









