






 本文详细探讨了Transformer模型在机器翻译任务中的维度变化过程,从输入的词向量到输出的概率分布。内容涵盖input Embedding、positional encoding、multi head self-attention、残差连接和层归一化等关键步骤,解释了如何通过注意力机制捕捉句子中的多种语义关系,并在decoder中进行解码和预测。
本文详细探讨了Transformer模型在机器翻译任务中的维度变化过程,从输入的词向量到输出的概率分布。内容涵盖input Embedding、positional encoding、multi head self-attention、残差连接和层归一化等关键步骤,解释了如何通过注意力机制捕捉句子中的多种语义关系,并在decoder中进行解码和预测。
例如我们要进行机器翻译任务法语–英语,输入一种法语,经过 Transformer,会输出另英语。Transformer 有 6 个编码器叠加和 6 个解码器组成,在结构上都是相同的,但它们不共享权重。拿出经典的图,我将从encoder一步一步走,再到decoder一步一步走到output probabilities。
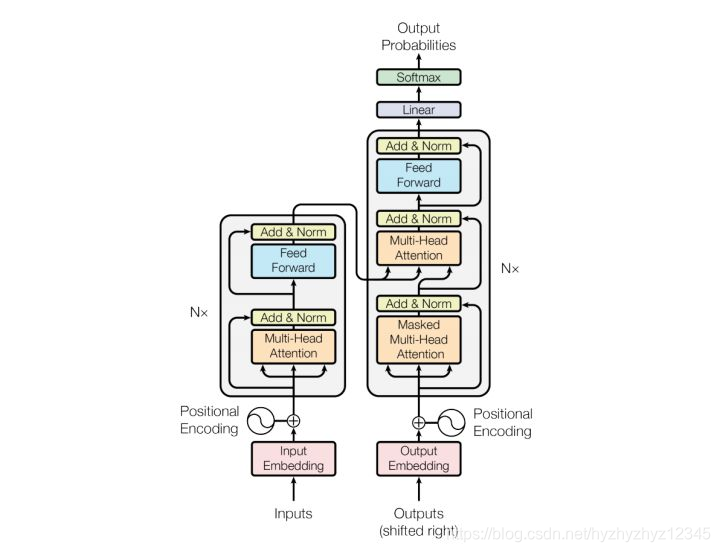
1、输入的是批量(batch_size)含有许多句子,最长为max_seq_length,不足的会padding 0。向量维度(batch_size * max_seq_length)
2、经过input_Embedding,查询词库表(vocab_size * embedding_size)查询得到字的词向量。
向量维度(batch_size * max_seq_length * embedding_size)
3、经过positional encoding,用不同频率的sine和cosine函数直接计算,将encoding后的数据与embedding数据求和,加入了相对位置信息(由于模型输入句子的所有word是同时处理的,但是每个字在句子中的位置具有重要意义,RNN具有天然的顺序,所以需要提供位置信息)。PE为二维矩阵,大小为(max_seq_length * embedding_size),pos 表示字在句子中的位置;dmodeld表示词向量的维度;i表示词向量的位置。因此,公式表示在每个词语的词向量的偶数位置添加si
说说transformer当中的维度变化
最新推荐文章于 2025-03-20 14:22:41 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









