






 ELMo通过双向LSTM解决多义词问题,提供动态词向量。预训练模型根据上下文推断词向量,提升下游NLP任务性能。缺点包括LSTM的并行计算限制和上下文理解能力有限。
ELMo通过双向LSTM解决多义词问题,提供动态词向量。预训练模型根据上下文推断词向量,提升下游NLP任务性能。缺点包括LSTM的并行计算限制和上下文理解能力有限。
2018年3月份提出ELMo(Embedding from Language models),模型通过对不同句子创建不同的词向量,进行动态调整,解决了之前工作2013年的word2vec及2014年的GloVe的多义词问题,可以称之为静态词向量。模型经过大量语料库预训练好之后
(context—before预测当前字,context—after预测当前字,而且不是同时的),使用预训练时,将任务实际的一句话或一段话输入该模型,模型会根据上下文来推断每个词对应的词向量,可以称之为动态词向量。
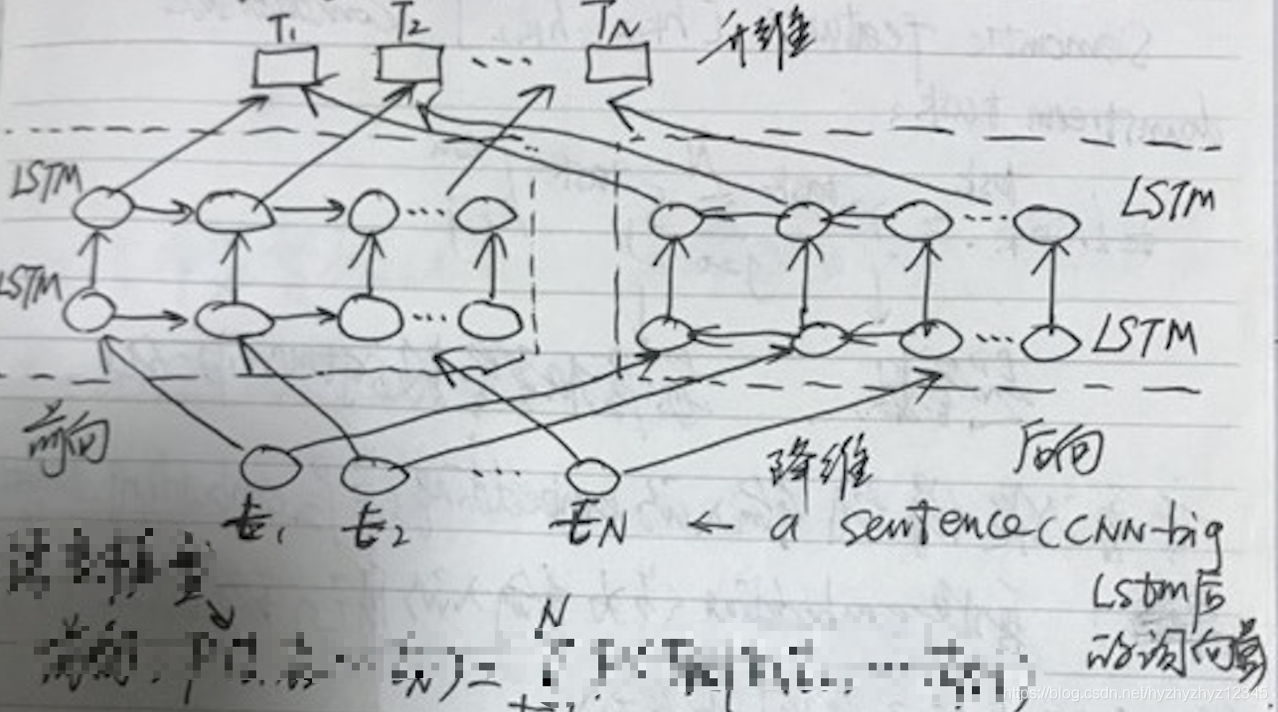
模型使用双向的LSTM语言模型,由一个前向和一个后向语言模型构成,目标函数是这两个方向语言模型的最大似然函数。给定一串长度为N的词条(t1,t2,…,tN),前向语言模型通过对给定句子左侧(t1,…tk−1)预测tk进行建模(auto regressive language model),前向LSTM: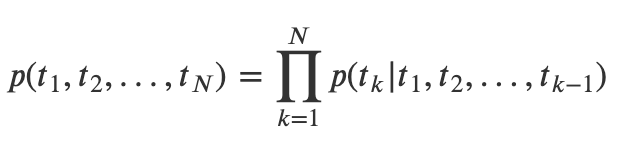
同理,后向语言模型通过对给定句子右侧(tN…tk-1)预测tk进行建模(auto regressive language model),后向LSTM: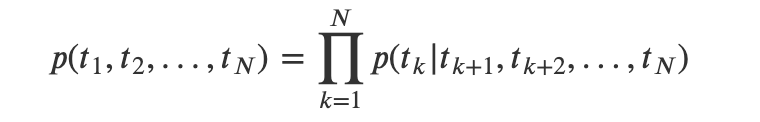
求取最大似然函数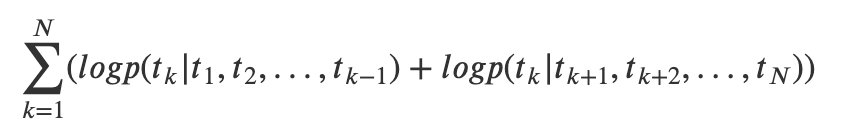
经过双向三层LSTM进行特征提取(word features,syntactic features,semantic features),得到预训练模
elmo算法解析
最新推荐文章于 2023-07-20 11:35:23 发布

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 373
373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









