






一、rk3588介绍
(一)NPU介绍
NPU:加速神经网络计算的处理器
RKNPU:瑞芯微处理器内置的NPU
NPU1.0、NPU2.0——RKNPU
NPU3.0、NPU4.0——RKNPU2
NPU算力:每秒可处理的运算次数、以TOPS为单位
(二)RK3588介绍
(1)3588特点:(浅列举几项)
-
NPU CORE*3
-
支持单、双、三核
-
通过AHB接口配置寄存器
-
通过AXI接口连接内存
(2)单核架构
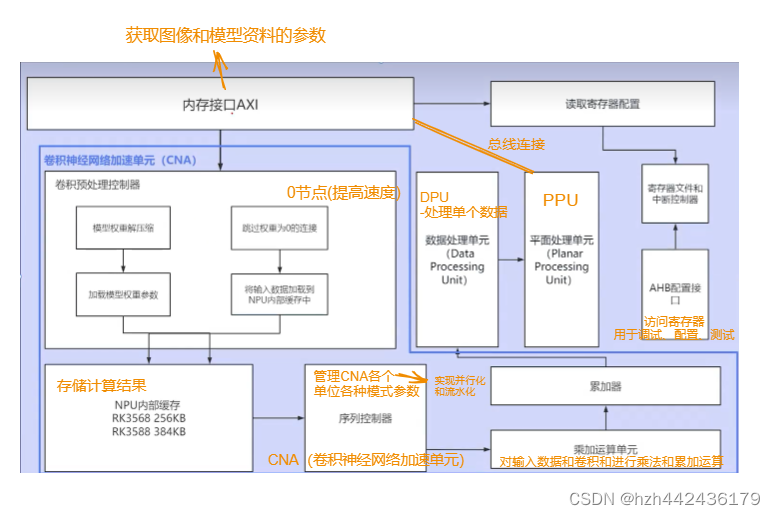
(3)应用场景:

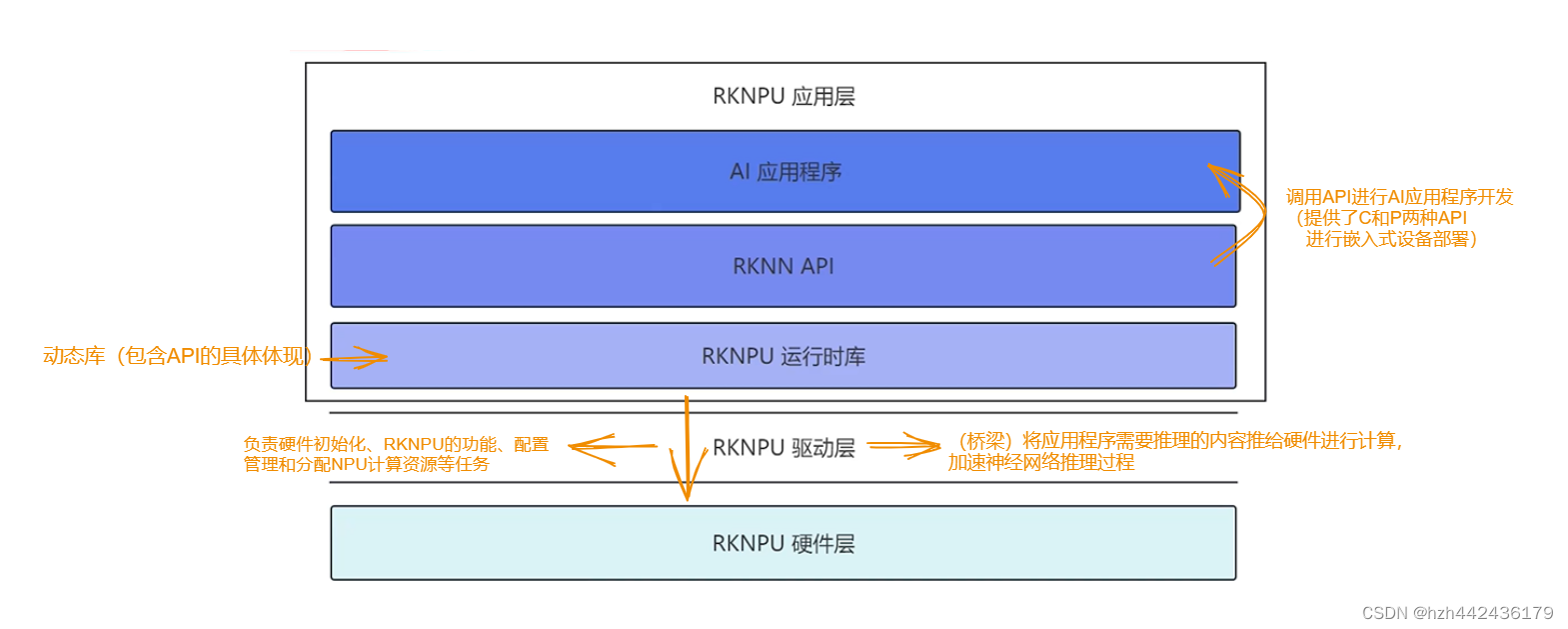
(4)RKNPU推理软件框架
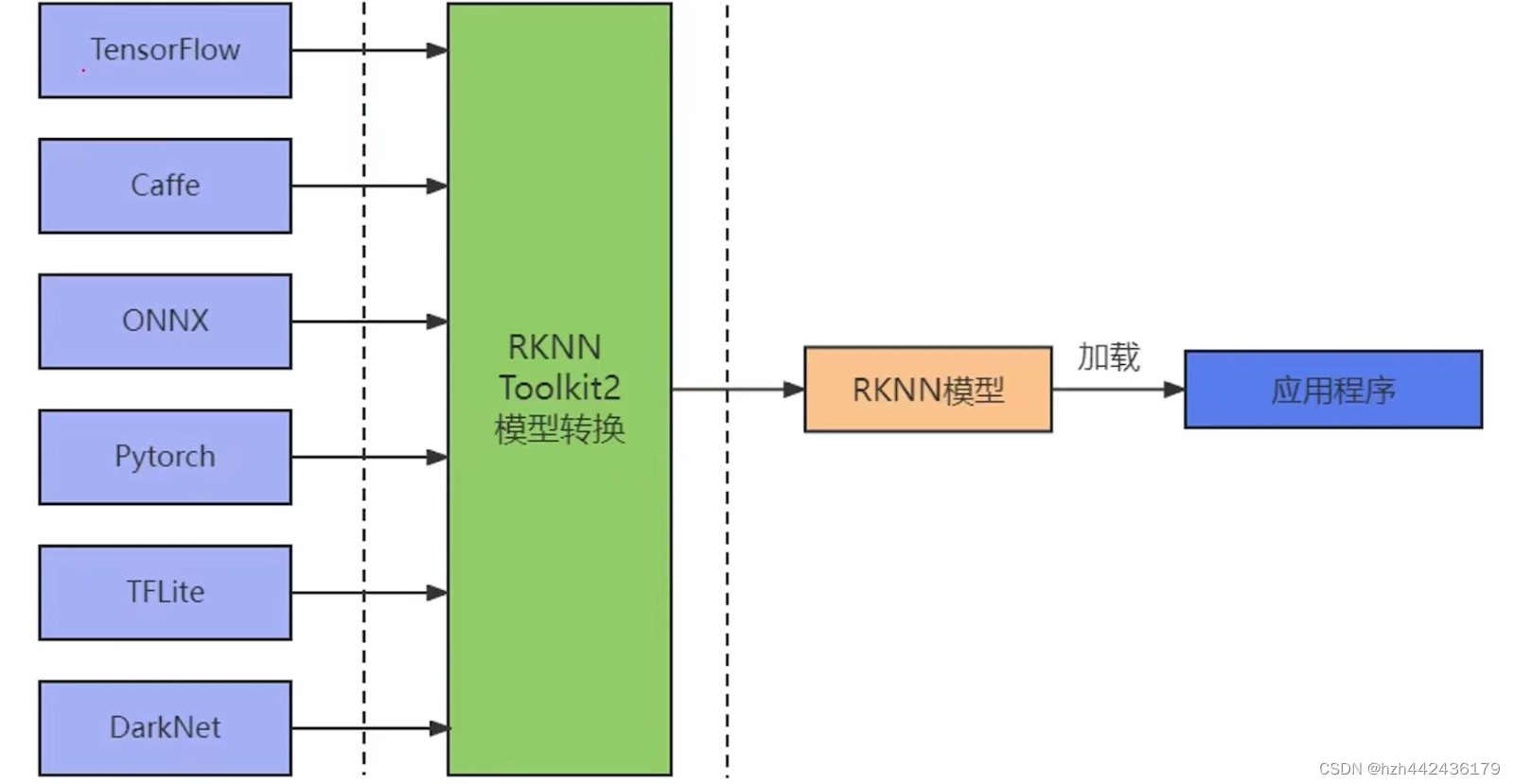
(5)RKNN模型
二、实践运用
(一)简单介绍
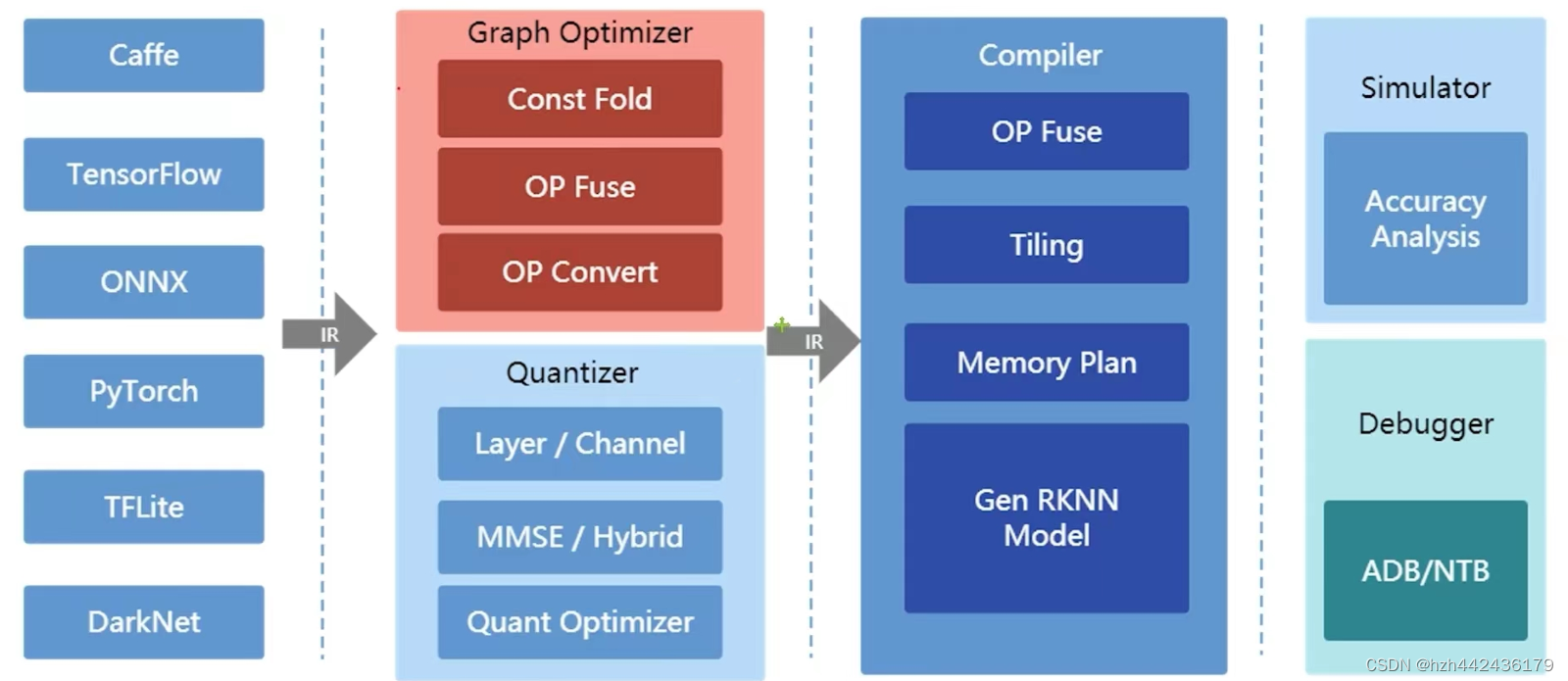
RKNN Toolkit2是一个软件开发套件,在PC平台和Rockchip NPU平台上进行模型转换、推理、性能评估
RKNN Toolkit-lite2(阉割版)(lite为某产品或某服务或某程序的轻量级版本)
在NPU平台上提供Python-API来部署RKNN模型、加速人工智能应用的实现
(二)RKNN Toolkit2介绍
(1)实践:可在GitHub上搜索rockchip-Linux个人用户找到rknn-toolkit2仓库
(2)RKNN Toolkit2库内容:
doc:使用文档、更新记录、python环境的所依赖项*2、RKNN所支持的算子列表、快速入门指南、指导使用手册
examples:示例代码(用于演示TOOLKIT2功能的使用方法)
packages:python3.6安装包-适用于X86 Ubuntu18; python3.8安装包-适用于X86 ubuntu20
(3)RKNN-TOLLKIT2(提供python接口)主要功能:
-
模型转换:将常用的深度学习模型转换为RKNN模型(只有转换了才能被C或P的 api进行加载)
(常用的深度学习模型的精度一般为float32格式,将float32模型量化为8位的定点模型后,对模型进行了瘦身,保留了精度的同时还提高了推理速度)
-
量化功能:支持将浮点模型转化为定点模型,方法为asymmetric-quantized-8(8位非对称量化)
-
模型推理:
-
能在PC(X86 Linux平台)上模拟NPU运行RKNN模型并获取推理结果
-
将RKNN分发到指定NPU设备上进行推理
-
性能和内存评估:用于评估模型在实际设备上运行时的性能和内存占用情况(只能在连扳推理下使用)
-
量化精度分析
-
模型加密功能
(三)RKNN Toolkit-lite2介绍
(1)RKNN Toolkit-lite2库内容:
doc:使用文档
examples:示例代码*1
packages:python3.7/.39安装包(arch64)(需要安装在RK3588或RK3568运行的int系统上)
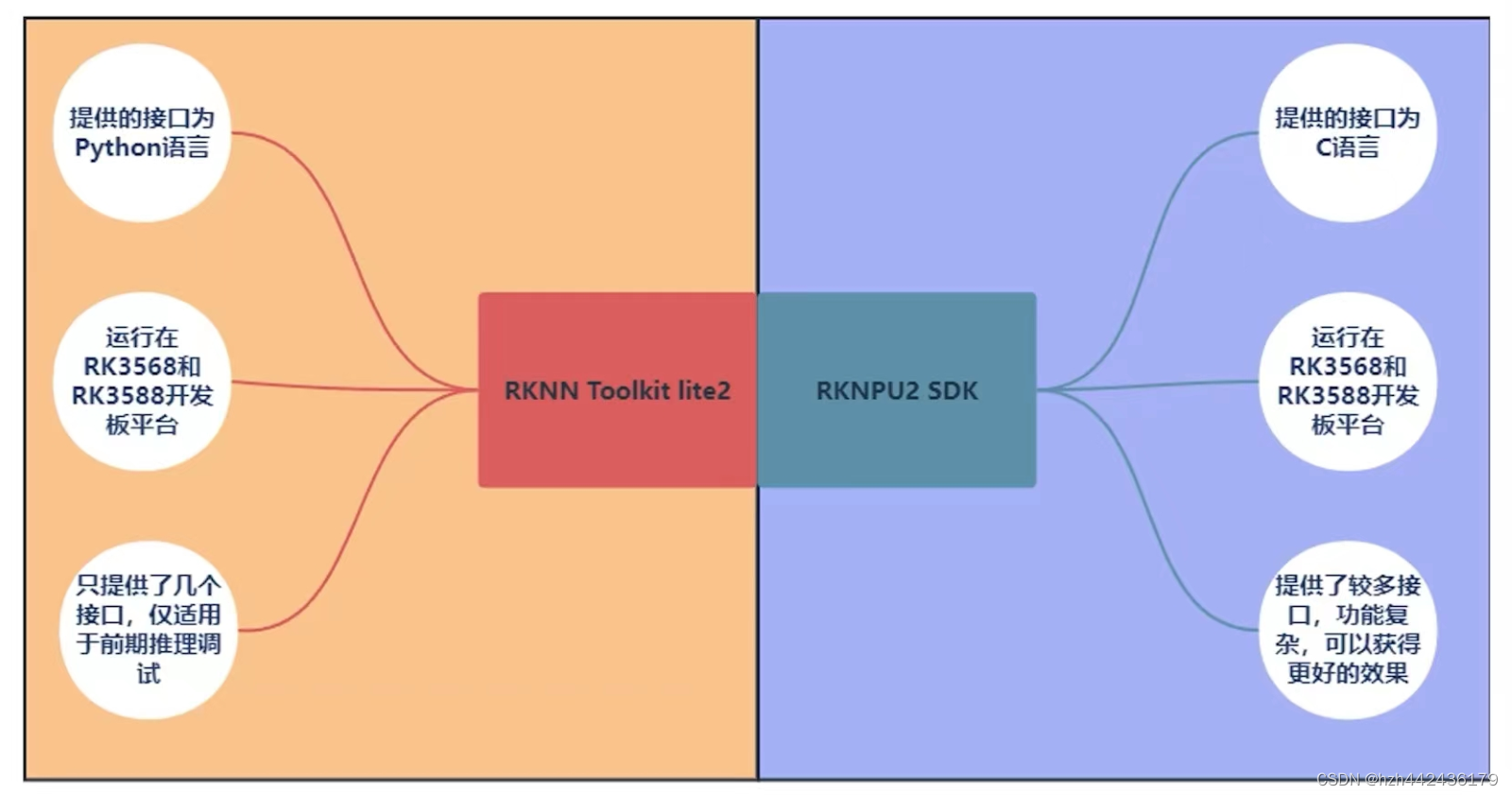
(四)RKNN-TOLLKIT2和RKNN Toolkit-lite2的区别
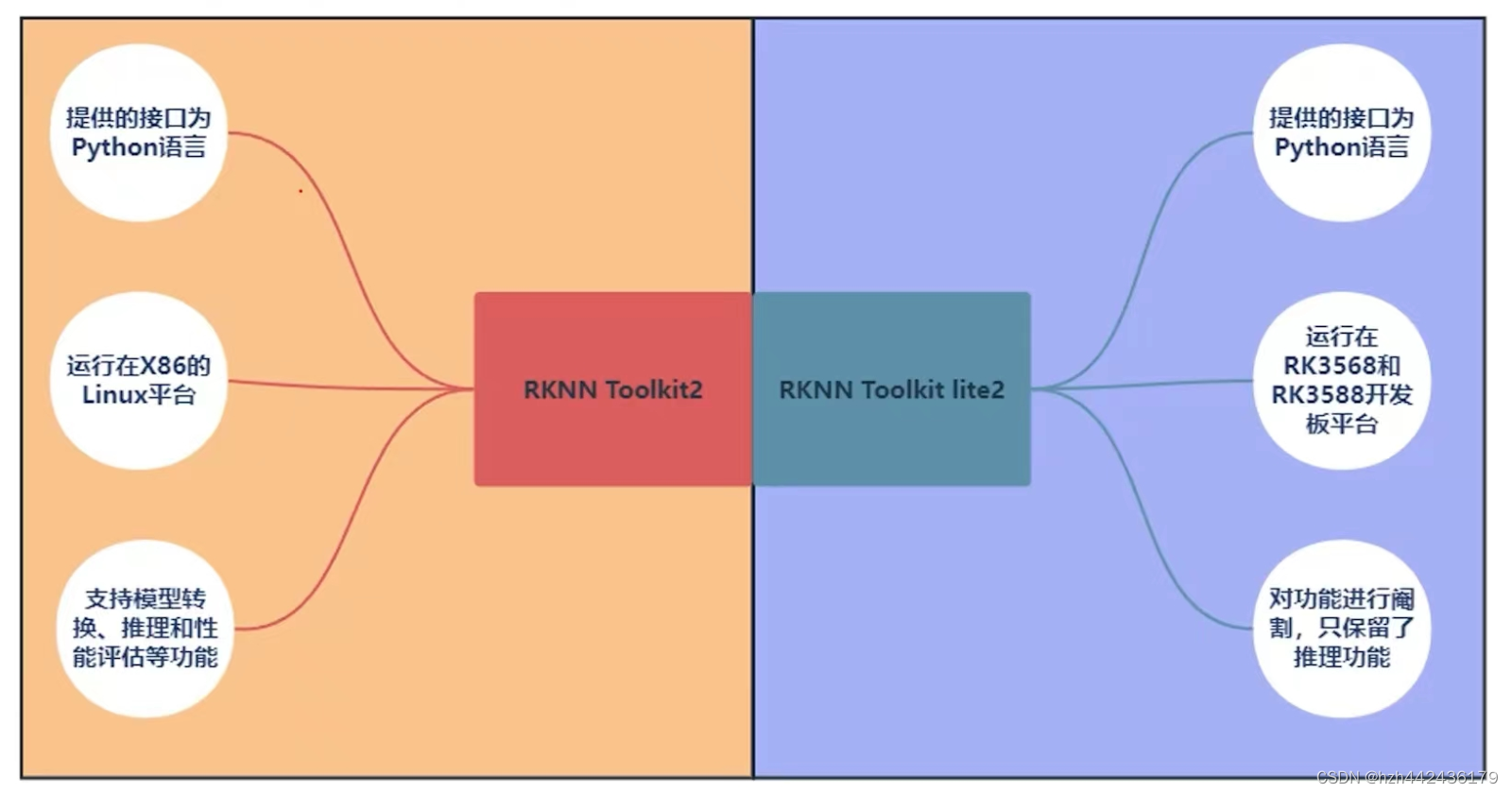
(五)RKNPU2 SDK介绍
(1)RKNPU2 SDK库内容:
doc:使用文档、算子支持列表、快速入门、指导手册
examples:示例代码、第三方库(3rdparty)
runtime:存放API运行时所依赖的动态库和头文件、rknn_sever可执行文件(如需使用连板推理功能,需要先在开发板上运行rknn_sever)
(2)RKNPU2 SDK:
与RKNN Toolkit-lite2的功能相同,同样是在开发板上部署模型进行推理,但提供了更多的接口(调用较复杂、运行效果更好)
(六)RKNPU2 SDK和RKNN Toolkit-lite2区别
(七)总结:
无论是使用RKNN Toolkit-lite2或者是使用RKNPU2 SDK进行推理,都要先使用RKNN-TOLLKIT2进行RKNN模型转换、精度分析、性能评估
三、代码实践
(一)前置流程:
打开虚拟机Ubuntu--打开pycharm--创建rknn项目—新建目录01_export_rknn—新建文件export_rknn.py
(二)模型构建的代码编写
-
创建RKNN对象,以及初始化RKNN_SDK环境
1 from rknn.api import RKNN # 使用RKNN-TOLLKIT2的所有的api接口时,都需先调用RKNN方法、初始化RKNN对象
2 if __name__ == '__main__':
rknn = RKNN(verbose=True, verbose_file="log.txt") # verbose参数为ture时可在终端打印日志信息,verbose_file参数用于指定日志信息存放在指定文件
-
调用config接口设置模型的预处理、量化方法等参数
3 # 调用config接口配置要生成的RKNN模型
rknn.config(
mean_values=[[123.675, 116.28, 183.53]], # mean_values参数表示预处理要减去的均值化参数
std_values=[[58.395, 58.395, 58.395]], # std_values参数表示预处理要除的标准化参数
quantized_dtype="asymmetric_quantized-8", # quantized_dtype参数表示量化的类型,默认为asymmetric_quantized-8,(通用的深度学习模型为4字节,经过8位量化后,会将权重和激活值量化为int8类型,只占据1字节,模型大小变为原来的四分之一,计算速度会提高四倍)
quantized_algorithm='normal', # quantized_algorithm参数表示量化的算法,默认为normal
quantized_method='channel', # quantized_method参数表示量化的方式,默认为channel(通道级量化)(精度较高),另一个为layer(层级量化)
quant_img_RGB2BGR=' False ', # 表示在量化阶段加载图像时是否先做RGB2BGR的转换,默认是False(只会在量化阶段使用,不会嵌入进rknn模型中)
target_platform ='rk3588', # target_platform参数表示模型运行的平台
float_dtype="float16", # float_dtype参数表示RKNN模型中默认的浮点数类型,只支持float16格式(如不进行量化会将原模型的flat32转换为float16格式)
optimization_level=3, # optimization_level参数表示优化等级,默认为3级,表示打开全部的优化选项(0为关闭所有优化的选项,1和2代表中间值,表示打开部分优化选项)(该参数可能会对最后的精度值产生影响)
custom_string="this is my rknn model ", # custom_string参数表示向rknn模型中添加的自定义字符串信息,可以在C-API中通过查询接口来查询到添加的自定义字符串信息
remove_weight=False, # remove_weight参数默认为 False ,表示生成一个去除权重的从模型,可以使用C-API与另一个完整的模型共享权重,减少了内存的消耗,用在RV106/109上
compress_weight=False, # compress_weight参数表示压缩权重,默认为 False,可以减小模型的体积
inputs_yuv_fmt=None, # inputs_yuv_fmt参数默认为None,表示rknn模型输入数据的yuv格式
single_core_mode=False, # single_core_mode参数默认为 False ,只适用于rk3588,表示生成的rknn模型运行在单核心模式,设置为True可以减小生成的rknn模型的体积
)
(一般只需要添加 mean_values=; std_values; target_platform这三个参数,其他根据具体使用场景具体分析使用)
-
调用接口导入原始模型
rknn.load_pytorch(
model="./resnet18.pt", # model 参数表示加载模型的地址
input_size_list=[[1, 3, 224, 224]], # input_size_list参数表示模型输入节点对应的图片尺寸和通道数,要和训练时所输入的图像的属性来确定(1/3为通道数,224/224为图片的高度和宽度)
)
-
调用BUILD接口构建RKNN模型
build接口会依照加载的模型结构、权重数据和config接口中的配置来构建对应的rknn模型
rknn.build(
do_quantization=True, # do_quantization 参数默认为Ture,表示是否对生成的rknn模型进行量化操作
dataset="dataset.txt", # dataset参数只在 do_quantization设置为Ture时生效,表示rknn模型构建时采用的量化矫正数据集(正常有20-100张量化图片)
rknn_batch_size=-1, # rknn_batch_size参数默认为-1,表示自行填写,用于调整输入的batch数量,可以提高推理的效率,通常用于音视频流和超小模型上
)
-
调用export_rknn接口导出rknn模型
rknn.export_rknn(
export_path="resnet18.rknn", # export_path 参数表示导出的rknn模型的名称和路径
)
运行完成后会出现.rknn文件
-
调用release接口释放rknn对象
rknn.release()
(三)模型评估-推理测试
模型的不同运行方式
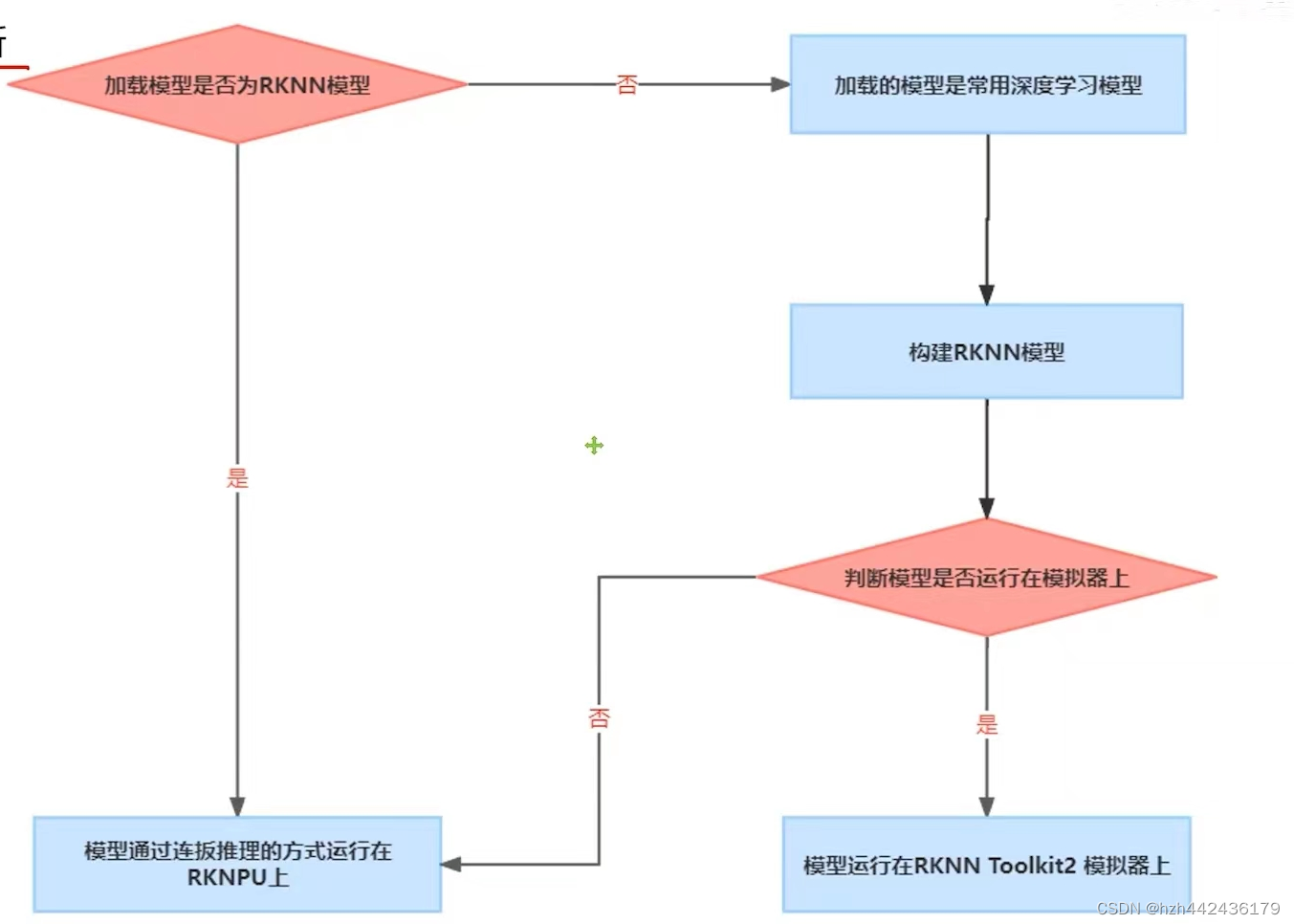
加载的模型:
直接加载Rknn模型:通过连板推理加载到NPU上(不能运行在模拟器上)(是经过编译步骤调整后的模型)
常用深度学习模型:转换成rknn模型-既可以运行在模拟器,也可以运行在rknpu上()
模型的最终运行设备:模拟器/rknpu
Rknn模型的构建框图
的代码编写















 1995
1995











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









