









先来试听感受下效果:
字节开源TTS MegaTTS3
1. MegaTTS3 介绍
MegaTTS3是字节跳动与2025年3月27日首次开源的文本转语音服务。我们以官方提供的性能对比来介绍MegaTTS3的优势:
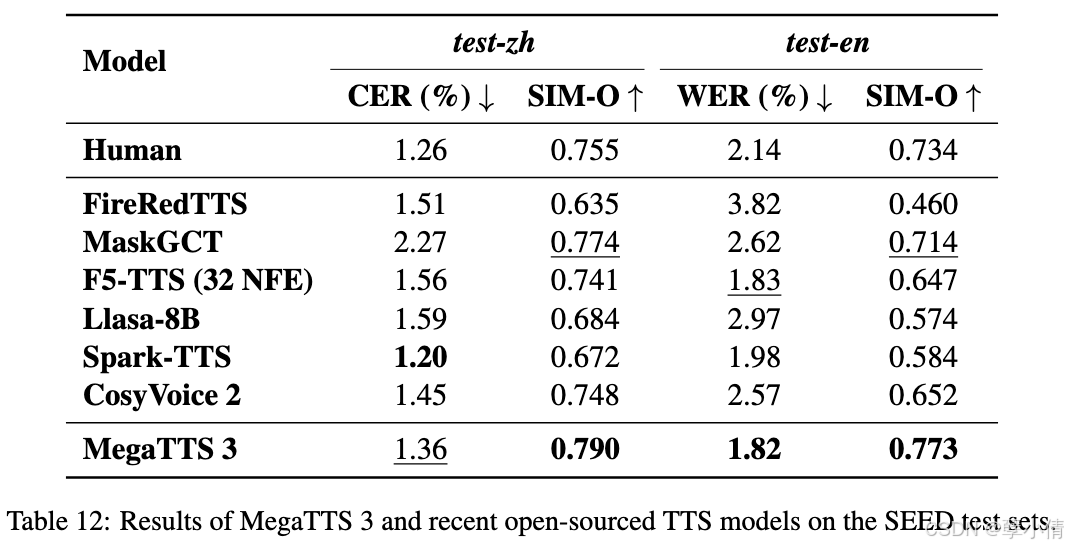
上图中,CER是字符错误率,即文本转语音时多读,漏读,或者误读的出错率,自然越低越好,从数据看,MegaTTS3虽然不是最低的错误率 ,但是已经是倒数第二低的错误率,英文WER甚至做到了最低,表现相当良好。
SMI-O(Speech Modeling Index - Objective)是语音合成(TTS, Text-to-Speech)领域中的一个评估指标,用于评估语音合成系统的质量,特别是其自然度和清晰度。它是一种基于客观评估的评分方法,旨在通过自动化手段评估合成语音的音质和表现,而不依赖于人工评分。分数越高越好,表格中分数取值0-1,无论英文还是中文,MegaTTS3都做到了最优,即发音最清晰,最容易理解,最自然。
使用docker版本的项目地址:https://github.com/leeyeel/MegaTTS3
2. 前置准备
官方github项目中不包含模型本身,因为模型本身巨大,不适合放置到项目本身中。使用前需要下载模型以及参考音频。为了方便期间,我们使用这个已经做了docker配置的克隆项目。
https://github.com/leeyeel/MegaTTS3![]() https://github.com/leeyeel/MegaTTS3
https://github.com/leeyeel/MegaTTS3
git clone https://github.com/leeyeel/MegaTTS32.1 下载模型
根据官方README文件,需要到链接处下载模型。每个都需要下载,下载完成后放置到MegaTTS3内的checkpoints文件夹下,下载链接
或者
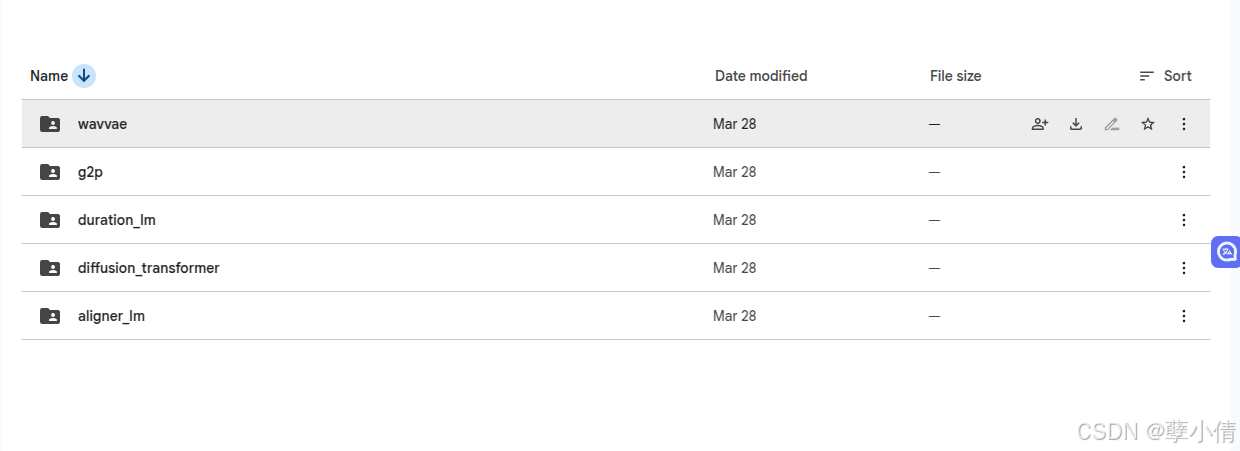
checkpoints的位置如下:
➜ MegaTTS3 git:(main) ls
assets checkpoints Dockerfile LICENSE readme.md requirements.txt tts目录结构如下:
2.2 下载参考音频、模型
可在这里下载,下载的文件一个wav音频文件,一个.npy模型文件
4. 部署
准备完毕以后,构建docker镜像:
docker build . -t megatts3:latest
5. 推理
构建成功之后,对于是使用GPU加速(目前GPU只支持CUDA)还是CPU运行有两种不同的命令方式:
使用GPU:
docker run -it -p 7929:7929 --gpus all -e CUDA_VISIBLE_DEVICES=0 megatts3:latest
使用CPU:
docker run -it -p 7929:7929 megatts3:latest
启动后访问http://0.0.0.0:7929/即可
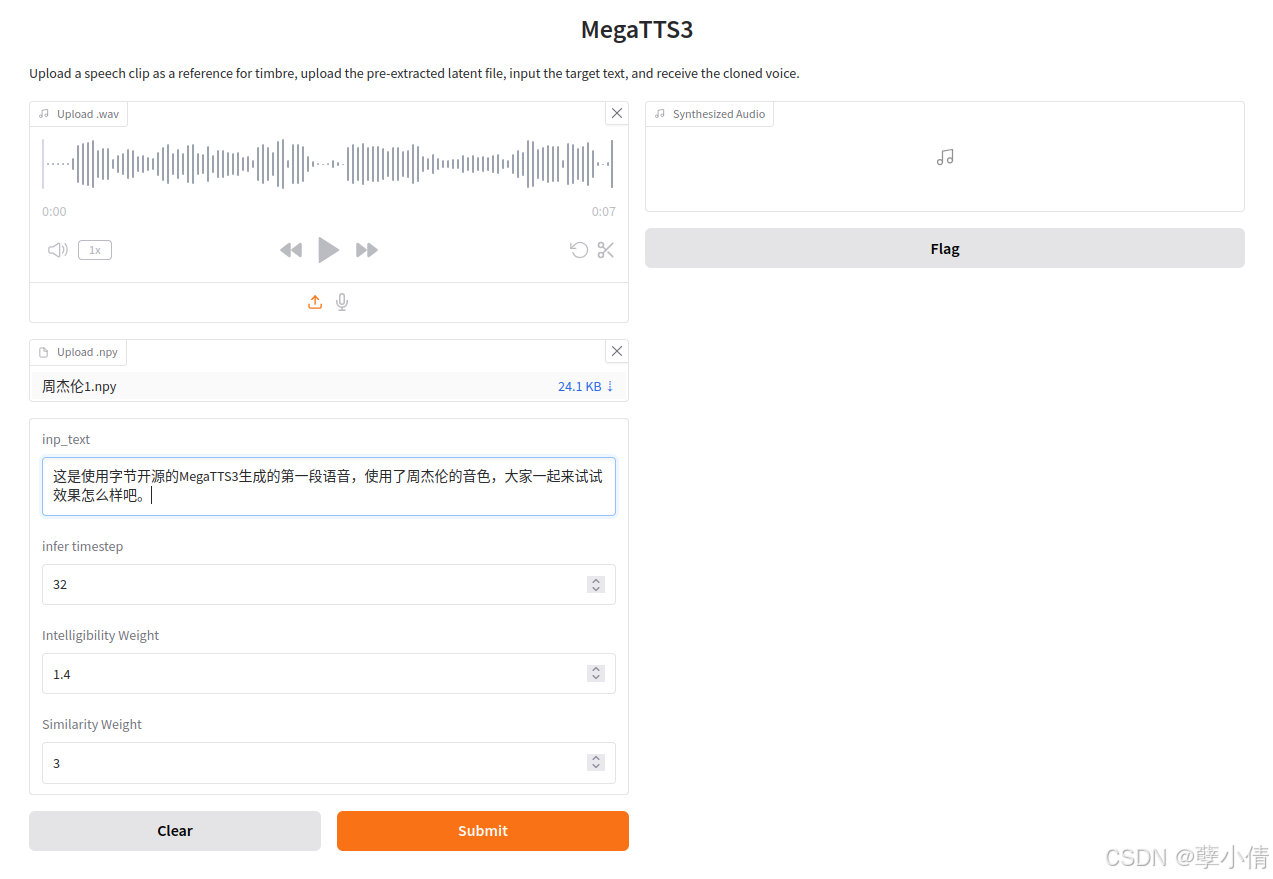
分别上传之前wav文件以及npy模型文件,然后输入想要转换的文字,点击submit即可开始进行生成语音。



















 243
243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











