







论文地址:https://arxiv.org/abs/1904.02948v1
代码地址:https://github.com/liuwei16/CSP
1、概述
传统的目标检测大多基于滑动窗体或者先验框方式,而无论哪个方法都需要繁杂的配置。本文中所介绍的检测器(CSP--Center and Scale Prediction),以行人检测为例,提出了一个高级语义特征检测的新视角。CSP放弃传统的窗体检测方式,通过卷积操作直接预测行人的中心位置和维度大小。结果显示CSP在准确率和速度上都有显著提高。
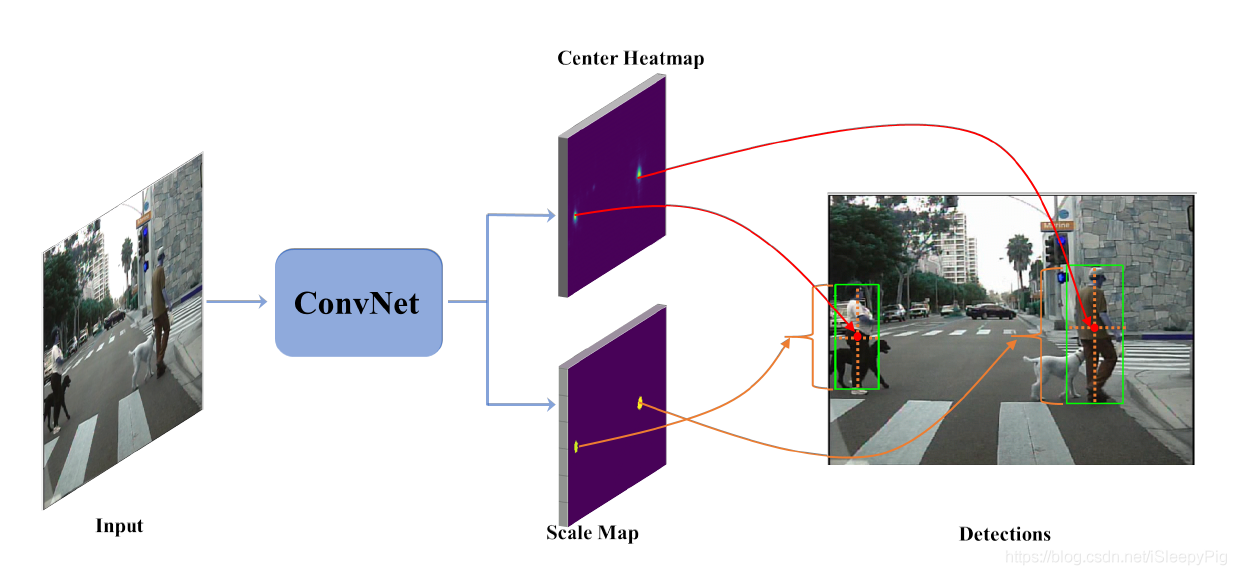
2、结构设计

CSP整体结构如图一所示,其中主干网络部分缩减自一个标准的网络结构(如:ResNet-50 和 MobileNet),并且在ImageNet上预训练过。主要分成两部分:Feature Extraction和Detection Head。
2.1 Feature Extraction
以ResNet-50为例,以每次下采样为界将其卷积层分为五个阶段,每个阶段的大小是原图以缩减因子分别为2,4,8,16,32得到的缩略特征图。并且在第五步采用孔洞卷积,最终得到的特征图大小与第四阶段一致,是原图的1/16。因为浅层含有更加准确的位置信息,深层拥有更多的语义信息,所以作者将不同阶段的特征图串联成一个。又因为图片特征图大小不一,所以采用反卷积方式将图片转换成相同
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 177
177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









