






CNN FPGA加速器实现(小型)CNN FPGA加速器实现(小型)
通过本工程可以学习深度学习cnn算法从软件到硬件fpga的部署。
网络软件部分基于tf2实现,通过python导出权值,硬件部分verilog实现,纯手写代码,可读性高,高度参数化配置,可以针对速度或面积要求设置不同加速效果。
参数量化后存储在片上ram,基于vivado开发。
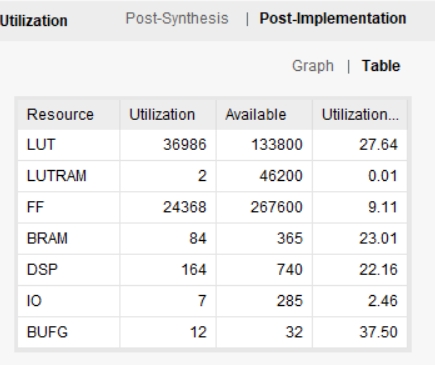
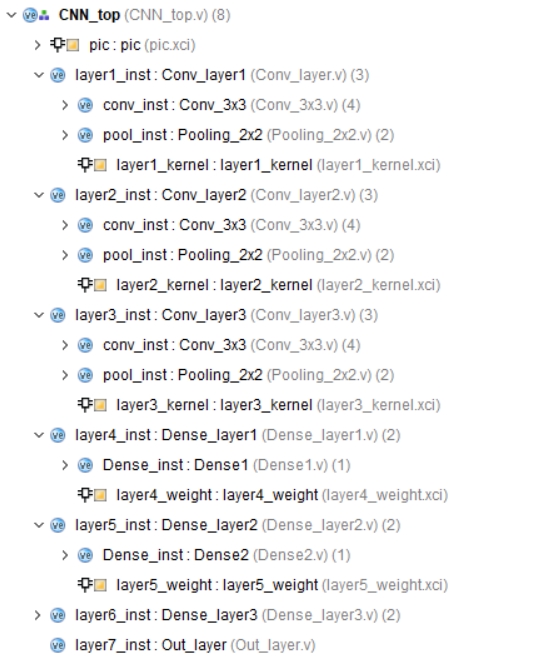
图一为工程结构图,提供基础的testbench,加速器输入存在ram上,图二为在artix7 fpga xc7a200t所占资源(资源和速度互相折中,可以用更多的资源换速度,也可以降速度减少资源消耗)。
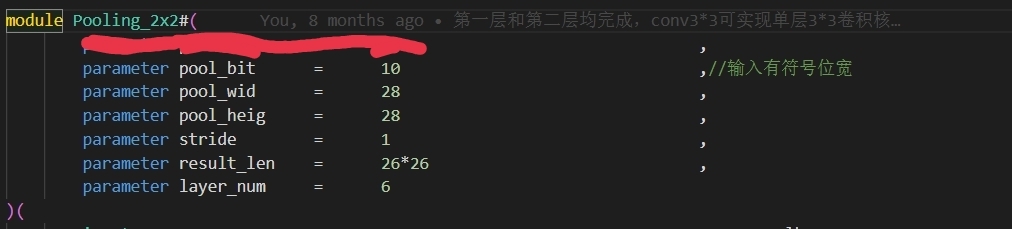
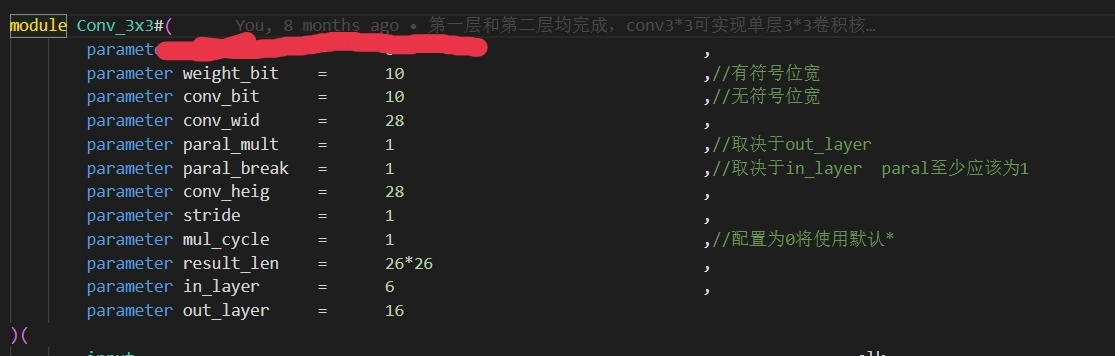
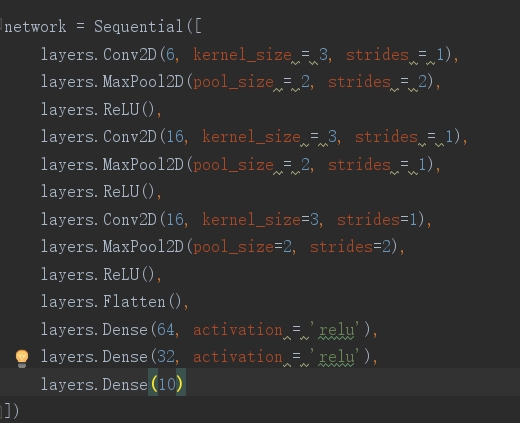
图三为网络结构图,demo所实现输入为28*28*1,图四五为卷积层和池化层可配置部分。
单张图片推理时间50us左右
提供本项目实现中所用的所有软件( python)和硬件代码( verilog)。
ID:52300624043661539
云赐记
标题:基于CNN FPGA加速器的深度学习算法实现及性能优化
摘要:本文介绍了一种基于CNN FPGA加速器的深度学习算法实现方法,通过软件到硬件的部署,实现了对CNN算法的加速。软件部分采用TensorFlow2实现,通过Python将权值导出;硬件部分采用Verilog手写代码实现,具有高可读性,并且高度参数化,可以根据速度或面积要求设置不同的加速效果。本文详细介绍了工程结构、测试原理、资源占用和网络结构,并提供了所有实现所用的软件和硬件代码。
-
引言
近年来,深度学习算法在计算机视觉、自然语言处理等领域取得了巨大的突破,但由于深度学习算法的计算复杂度高,对硬件设备性能的要求也越来越高。传统的CPU在运行深度学习算法时,效率低下,因此需要借助专门的硬件平台来加速计算,提高算法的运行速度。本文介绍了一种基于CNN FPGA加速器的深度学习算法实现方法,旨在提供一种高效的计算加速方案。 -
CNN FPGA加速器实现原理
CNN FPGA加速器是通过将深度学习算法的计算过程以硬件形式实现,从而提高运行速度。具体实现过程如下:
- 2.1 网络软件部分
本文采用TensorFlow2作为网络软件部分的实现工具,通过Python将深度学习网络的权值导出。这一步骤可以保证软硬件的一致性,将网络中的权值保存在片上RAM中,为后续的硬件部分提供数据。 - 2.2 硬件部分
硬件部分采用Verilog进行手写代码的实现,具有高可读性。通过Vivado开发工具,进行资源分配和参数配置,可以根据速度或面积要求设置不同的加速效果。
-
工程结构
本工程的结构如图一所示,其中包括网络软件部分和硬件部分。工程提供了基础的testbench,用于测试加速器的输入。加速器输入存储在片上RAM中,以提高运行效率。 -
资源占用
本工程实现部署在Artix7 FPGA XC7A200T上,资源占用与运行速度可以进行折中。通过调整资源的使用量,可以实现不同的加速效果。图二展示了Artix7 FPGA XC7A200T所占用的资源情况。 -
网络结构
本工程实现的深度学习网络结构示意图如图三所示,其中展示了一个输入为28281的网络。图四和图五展示了可配置的卷积层和池化层部分,可以根据具体需求进行参数配置。 -
性能优化
经过测试,本工程实现的CNN FPGA加速器在单张图片推理时间上,约为50us。在实际应用中,可以通过进一步优化硬件设计和参数配置,提高运行速度,实现更高效的图像识别。 -
总结
本文介绍了一种基于CNN FPGA加速器的深度学习算法实现方法,通过软件到硬件的部署,实现了对CNN算法的加速。该方法具有较高的性能和灵活性,可根据实际需求进行参数配置,达到不同的加速效果。未来,可以进一步研究并优化硬件设计和参数配置,提高算法的运行速度和准确性。
关键词:CNN FPGA加速器,深度学习算法,硬件部署,Verilog,Vivado,资源占用,性能优化
相关的代码,程序地址如下:http://imgcs.cn/624043661539.html


















 795
795

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









