






前言:
本文是Stable Diffusion进阶教程,手把手教你使用插件为LoRA模型添加高质量缩略图。包含风格化模板库、批量生成技巧和行业标准规范,解决"预览不直观"、“风格不统一”、"制作效率低"三大痛点,让你的模型库更专业。
LORA缩略图和管理(Civitai Helper)
强大的LORA管理插件,可以自动下载缩略图和更新版本

自动下载缩略图

没有缩略图
LORA越来越多,自己手动弄缩略图太麻烦了,不然就一片灰?
试试这个插件,可以自动下载,简单易用
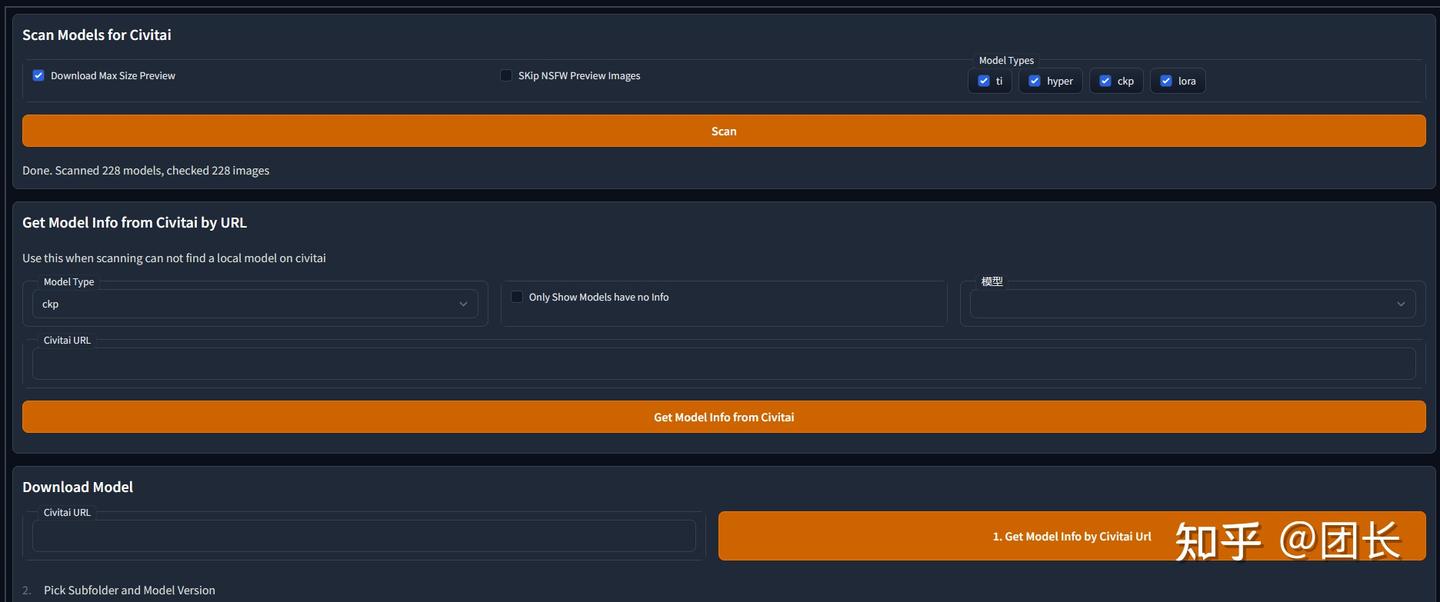
Civitai Helper插件设置页
下载地址
C站地址: Civitai | Share your models
这份完整版的SD、comfyui模型整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

LORA按需分类
想做到LORA这样一目了然,分类明确吗?
其实很简单
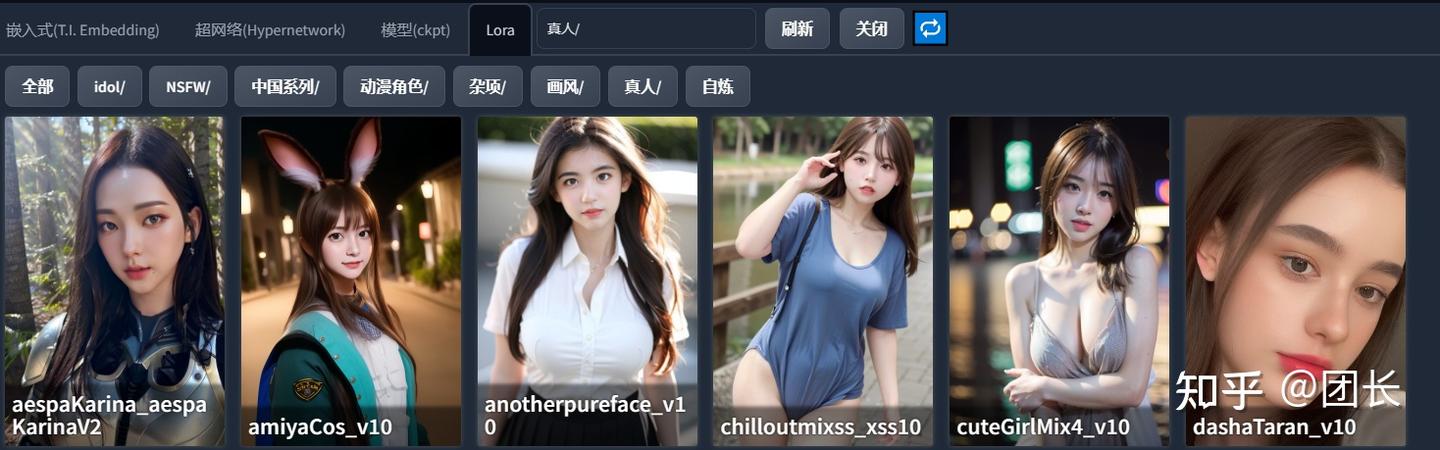
虽然方法简单,貌似说的人很少很少
进到存放lora的文件夹

然后在此目录下,建立你想要分类的文件夹,把相应的lora拖进去就行了
是不是很简单?
大模型按需分类
和lora分类的方法类似
进到model的目录
如下

然后建立自己想分类的目录,例如我建立一个动漫的文件夹

把相应的模型丢进去
然后刷新UI,模型选择界面就可以看到这个了
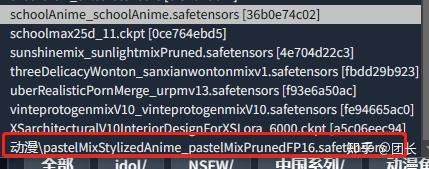
切换模型的VAE
随着我们的模型越来越多,我们会发现模型需要配套的VAE是不一样的,有时候切来切去会很麻烦,这时候我们可以利用SD原有的功能来实现快速切换VAE

快速切换VAE
先进入到设置页面,选择用户界面
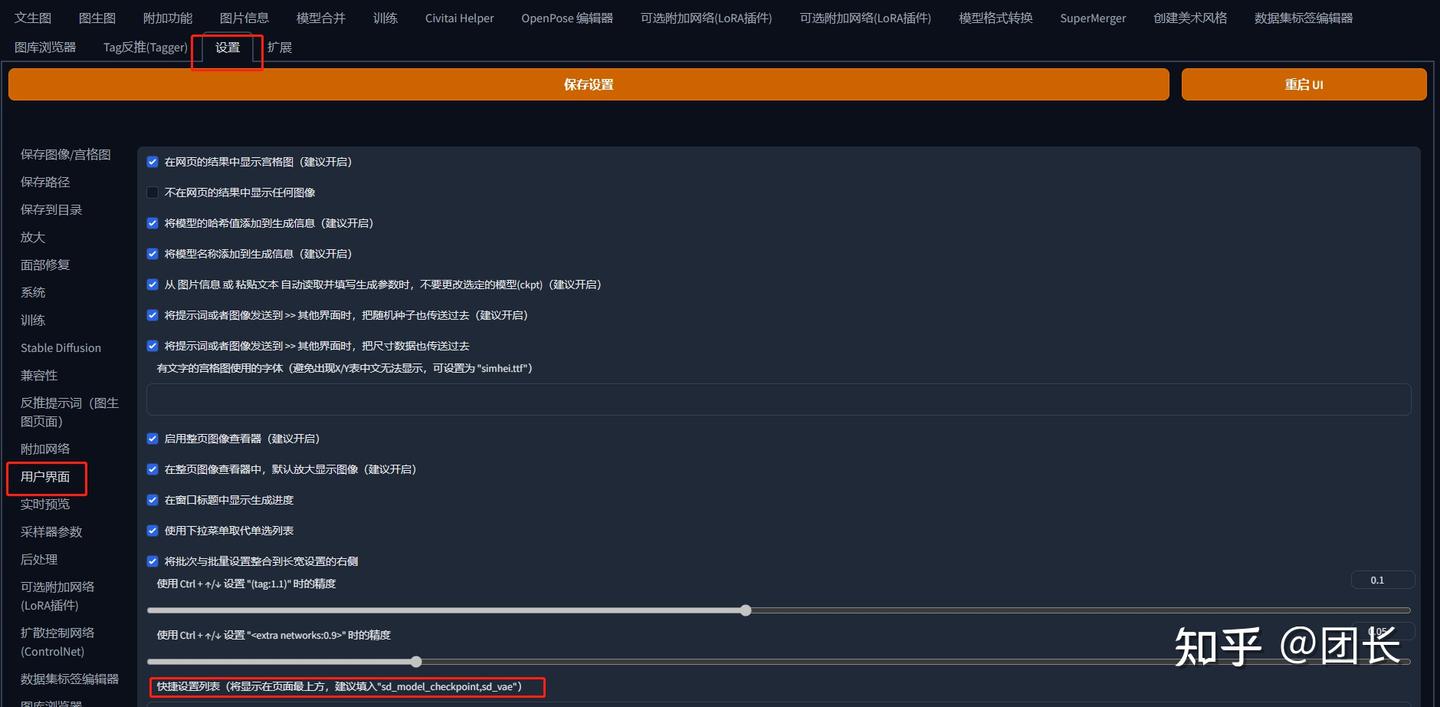
找到快捷设置列表
在sd_model_checkpoint后面输入,sd_vae
变成sd_model_checkpoint,sd_vae,保存设置并重启UI即可
高级预设模版Preset Manager
SD有自带的预设模版,可以一键保存我们的关键词
但是局限性很强,步数,种子,绘图方式,高清修复都不能保存,用Preset Manager可以保存我们大多数参数
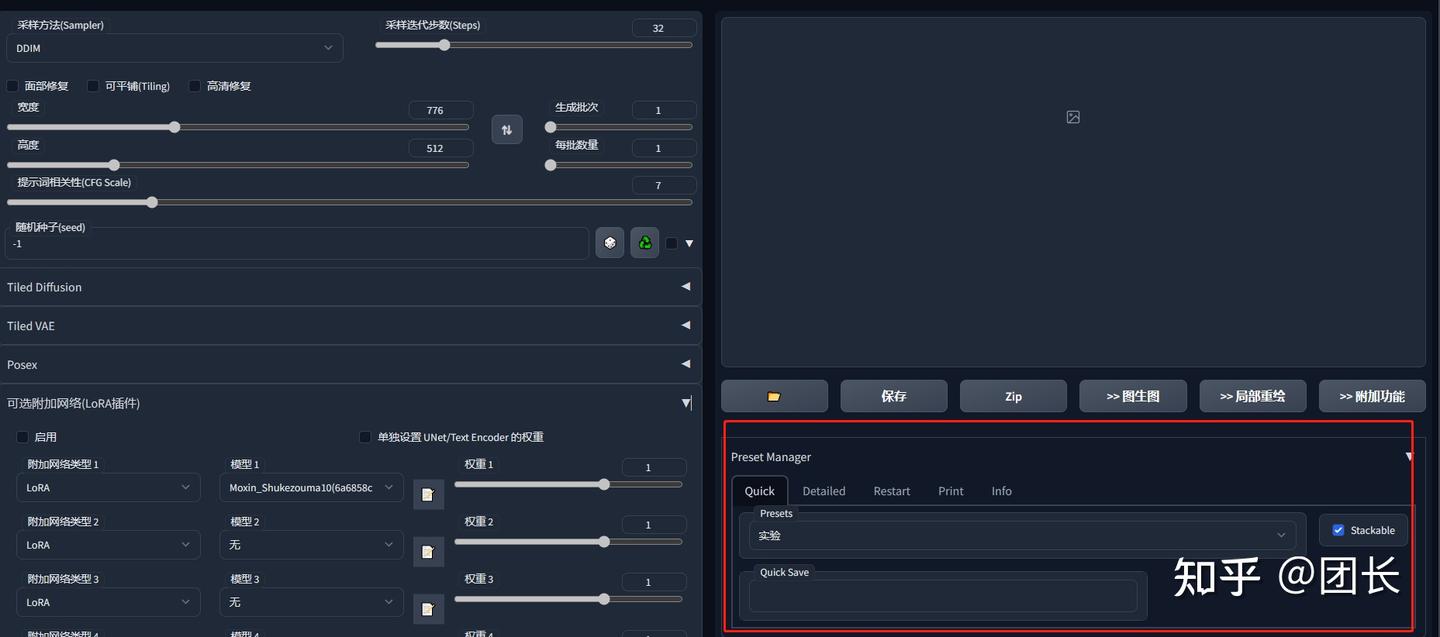
也可以快速切换预存设置,很是方便
下载地址
GitHub - Gerschel/sd_web_ui_preset_utils: Preset Manager moved private
显存神器Tiled VAE
显存小但是想要大尺寸怎么办?这时候我们可以试试这个工具Tiled VAE
如果原先只能512x768,用了翻倍,高清修复highres.fix同样有效,1.5倍能提升到2倍,相当给力
原理是将大图分成一片一片的区域,分开生成再合并
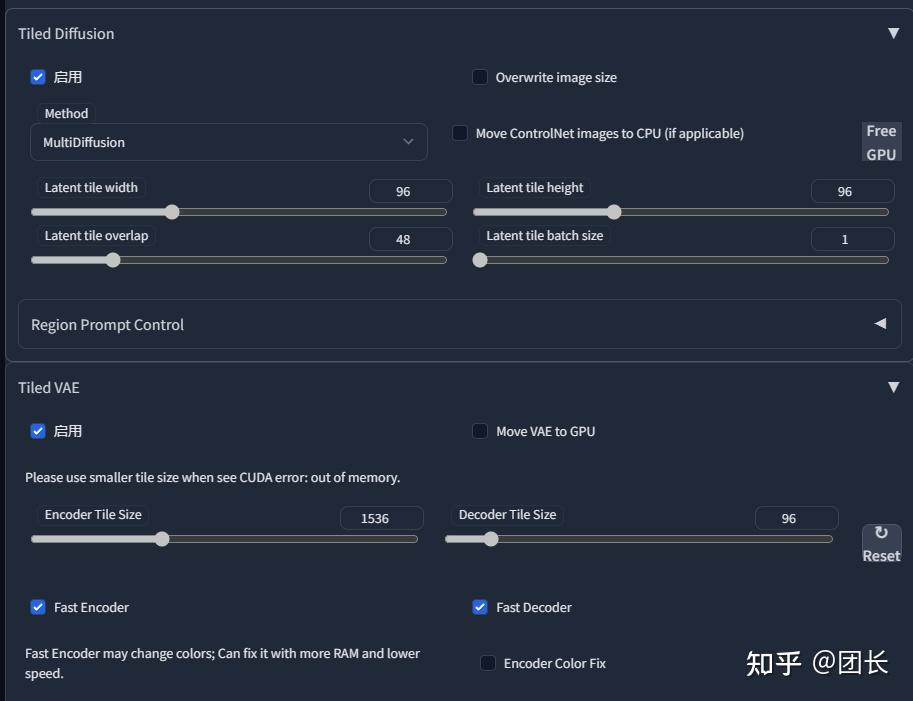
插件界面
下载地址
图片反推文字及打标(TAGGER)
可以导入图片让AI反推文字,功能和准确性都比SD自带的强不少,达到模仿和学习的目的,更多时候是训练LORA的时候用于批量打标签。
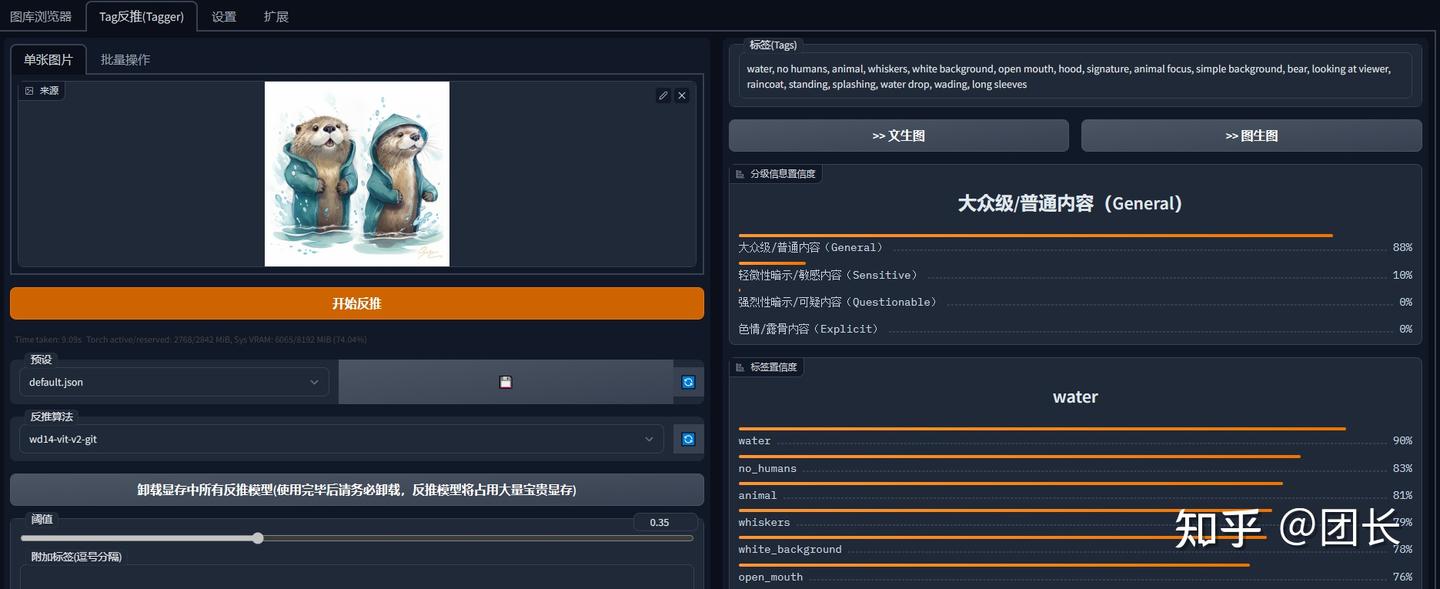
用完记得卸载模型,不然很占显存
下载地址
GitHub - toriato/stable-diffusion-webui-wd14-tagger: Labeling extension for Automatic1111’s Web UI
抠图插件(有些麻烦)
- 1,需要安装SD插件,
- 下载地址https://pan.baidu.com/s/17s_RVoZ4ec_BWIXwjUPnDQ?pwd=ktwu
- 2,需要安装CUBA支持
- 3,需要下载TensorRT,教程https://blog.csdn.net/Yang_4881002/article/details/124292512,下载https://pan.baidu.com/s/1YAjFZyNRPoE8J35n3pFJng?pwd=2jak
安装后可以找到后期处理这个选项
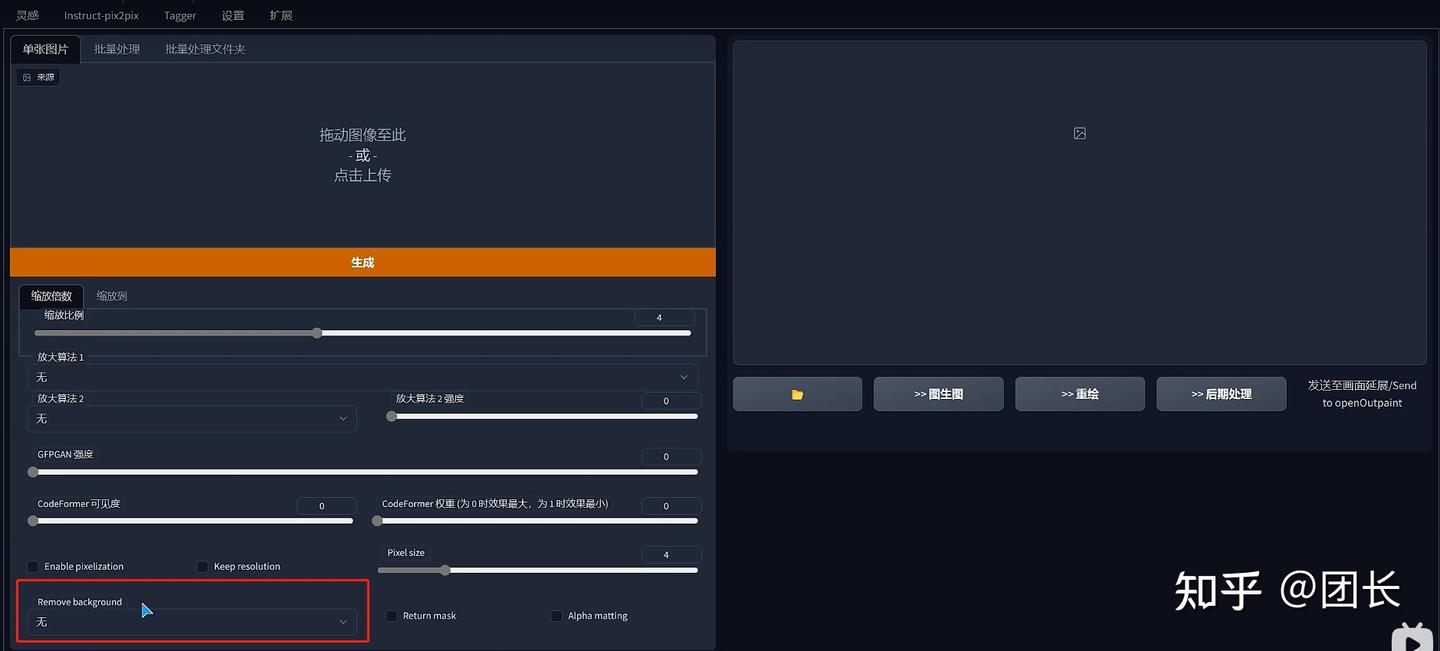
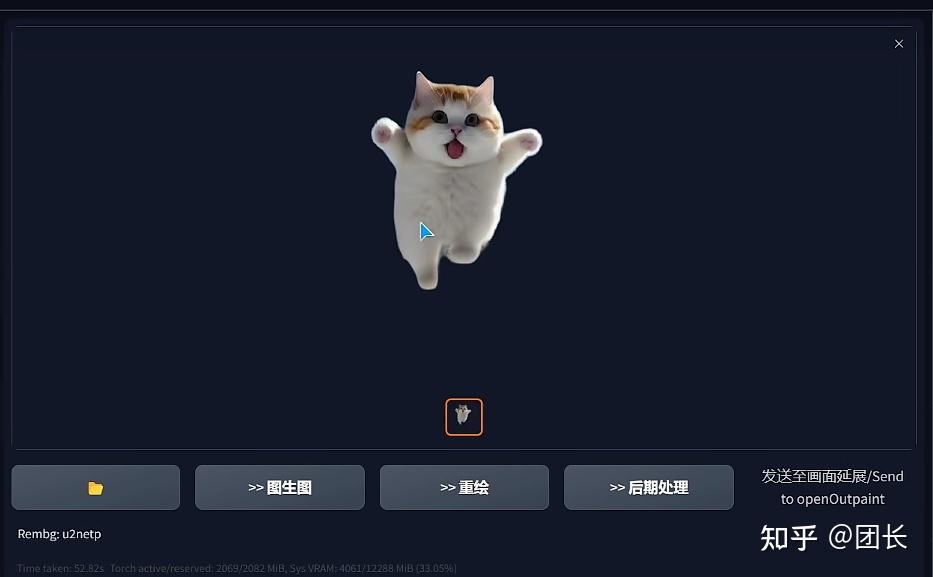
选择remove background,然后选择u2netp算法
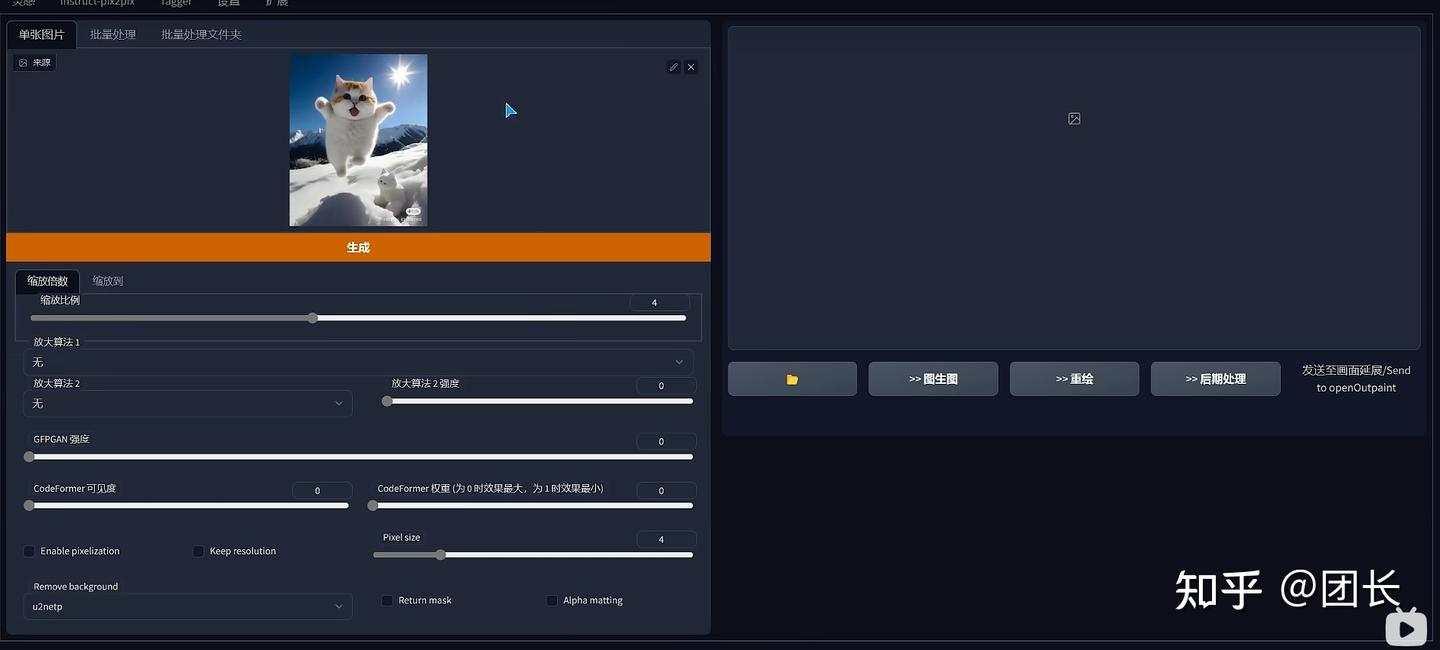
抠图成功
图片放大神器Tiled VAE
依然还是Tiled VAE,在图生图界面中可以直接把图放大,补充细节,超级给力
示例:从1024 * 800 放大到 4096 * 3200 ,使用默认参数
-
参数:
-
- 降噪 = 0.4,步数 = 20,采样器 = Euler a,放大器 = RealESRGAN++,负面提示语=EasyNegative,
- 模型:Gf-style2 (4GB 版本), 提示词相关性(CFG Scale) = 14, Clip 跳过层(Clip Skip) = 2
- 方法(Method) = MultiDiffusion, 分块批处理规模(tile batch size) = 8, 分块高度(tile size height) = 96, 分块宽度(tile size width) = 96, 分块重叠(overlap) = 32
- 全局提示语 = masterpiece, best quality, highres, extremely detailed 8k wallpaper, very clear, 全局负面提示语 = EasyNegative.
原图:

1024x800分辨率

4X放大4096 * 3200
下载地址
1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的SD、comfyui模型整合包已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

















 3666
3666

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









