







一、前言
从源码的角度剖析MapReduce 作业的工作机制
二、MapReduce 执行流程
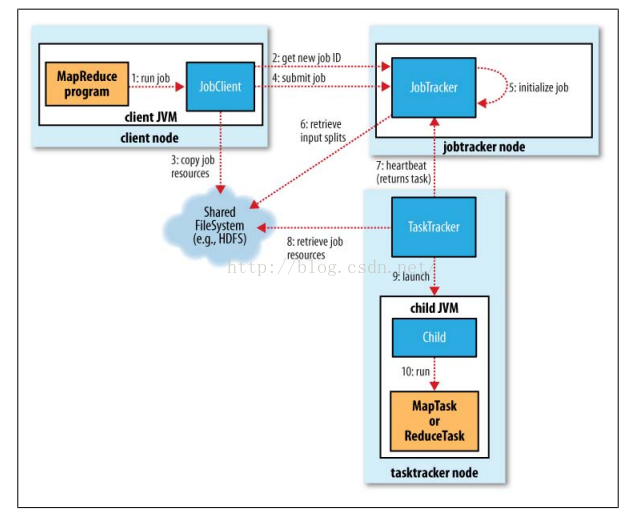
分析如下:
整个过程包含4个独立的实体
客户端: 提交MapReduce 作业
JobTracker: 初始化作业、分配作业。与TaskTracker通信
TaskTracker:保持与JobTracker的通信,在分配的数据片段上执行MapReduce任务
HDFS: 保存数据
2.1、提交作业
JobClient 调用submitJob()方法实现如下 :
JobClient 会先调作JobSubmissionProtocol 定义的submitJob()方法,submitJob() 实际 调用submitJobInternal(job)方法
public
RunningJob submitJobInternal(final JobConf job
) throws FileNotFoundException,
ClassNotFoundException,
InterruptedException,
IOException {
/*
* configure the command line options correctly on the submitting dfs
*/
return ugi.doAs(new PrivilegedExceptionAction<RunningJob>() {
public RunningJob run() throws FileNotFoundException,
ClassNotFoundException,
InterruptedException,
IOException{
JobConf jobCopy = job;
Path jobStagingArea = JobSubmissionFiles.getStagingDir(JobClient.this,
jobCopy);<span style="white-space:pre"> </span>//从JobTracker 得到当前任务ID
JobID jobId = jobSubmitClient.getNewJobId();<span style="white-space:pre"> </span><span style="white-space:pre"> </span>//根据jobID生成目录 Path submitJobDir = new Path(jobStagingArea, jobId.toString());
jobCopy.set("mapreduce.job.dir", submitJobDir.toString());
JobStatus status = null;
try {
populateTokenCache(jobCopy, jobCopy.getCredentials());
copyAndConfigureFiles(jobCopy, submitJobDir);
// 获取路径令牌
TokenCache.obtainTokensForNamenodes(jobCopy.getCredentials(),
new Path [] {submitJobDir},
jobCopy);
Path submitJobFile = JobSubmissionFiles.getJobConfPath(submitJobDir);
int reduces = jobCopy.getNumReduceTasks();
InetAddress ip = InetAddress.getLocalHost();
if (ip != null) {
job.setJobSubmitHostAddress(ip.getHostAddress());
job.setJobSubmitHostName(ip.getHostName());
}
JobContext context = new JobContext(jobCopy, jobId);
// Check the output specification
if (reduces == 0 ? jobCopy.getUseNewMapper() :
jobCopy.getUseNewReducer()) {
org.apache.hadoop.mapreduce.OutputFormat<?,?> output =
ReflectionUtils.newInstance(context.getOutputFormatClass(),
jobCopy);
output.checkOutputSpecs(context);
} else {
jobCopy.getOutputFormat().checkOutputSpecs(fs, jobCopy);
}
jobCopy = (JobConf)context.getConfiguration();
// 为job生成splits分块
FileSystem fs = submitJobDir.getFileSystem(jobCopy);
LOG.debug("Creating splits at " + fs.makeQualified(submitJobDir));
int maps = writeSplits(context, submitJobDir);
jobCopy.setNumMapTasks(maps);
// write "queue admins of the queue to which job is being submitted"
// to job file.
String queue = jobCopy.getQueueName();
AccessControlList acl = jobSubmitClient.getQueueAdmins(queue);
jobCopy.set(QueueManager.toFullPropertyName(queue,
QueueACL.ADMINISTER_JOBS.getAclName()), acl.getACLString());
// Write job file to JobTracker's fs
FSDataOutputStream out =
FileSystem.create(fs, submitJobFile,
new FsPermission(JobSubmissionFiles.JOB_FILE_PERMISSION));
// removing jobtoken referrals before copying the jobconf to HDFS
// as the tasks don't need this setting, actually they may break
// because of it if present as the referral will point to a
// different job.
TokenCache.cleanUpTokenReferral(jobCopy);
try {
jobCopy.writeXml(out);
} finally {
out.close();
}
//
// Now, actually submit the job (using the submit name)
//
printTokens(jobId, jobCopy.getCredentials());
status = jobSubmitClient.submitJob(
jobId, submitJobDir.toString(), jobCopy.getCredentials());
JobProfile prof = jobSubmitClient.getJobProfile(jobId);
if (status != null && prof != null) {
return new NetworkedJob(status, prof, jobSubmitClient);
} else {
throw new IOException("Could not launch job");
}
} finally {
if (status == null) {
LOG.info("Cleaning up the staging area " + submitJobDir);
if (fs != null && submitJobDir != null)
fs.delete(submitJobDir, true);
}
}
}
});
}1、调用JobTracker 对象获取作业id
2、检查作业相关路径
3、计算Map文件输入分块
4、将运行的作业写到对应的hdfs
5、调用JobTracker 的submitJob()提交作业
2.2、作业初始化
JobTracker 会调用内部的TaskScheduler
// Create the scheduler
Class<? extends TaskScheduler> schedulerClass
= conf.getClass("mapred.jobtracker.taskScheduler",
JobQueueTaskScheduler.class, TaskScheduler.class);默认的方法为in a queue in priority order (FIFO by default).
public synchronized void initTasks()
throws IOException, KillInterruptedException, UnknownHostException {
// Only for tests
if (!jobtracker.getConf().getBoolean(JT_JOB_INIT_EXCEPTION_OVERRIDE, false)
&&
getJobConf().getBoolean(JOB_INIT_EXCEPTION, false)) {
waitForInitWaitLockForTests();
}
if (tasksInited || isComplete()) {
return;
}
synchronized(jobInitKillStatus){
if(jobInitKillStatus.killed || jobInitKillStatus.initStarted) {
return;
}
jobInitKillStatus.initStarted = true;
}2.3、分配任务
TaskTrack 和JobTracker 通信,TaskTracker 中transmitHerartBeat()方法
/**
* The periodic heartbeat mechanism between the {@link TaskTracker} and
* the {@link JobTracker}.
*
* The {@link JobTracker} processes the status information sent by the
* {@link TaskTracker} and responds with instructions to start/stop
* tasks or jobs, and also 'reset' instructions during contingencies.
*/
public synchronized HeartbeatResponse heartbeat(TaskTrackerStatus status,
boolean restarted,
boolean initialContact,
boolean acceptNewTasks,
short responseId)
throws IOException {
if (LOG.isDebugEnabled()) {
LOG.debug("Got heartbeat from: " + status.getTrackerName() +
" (restarted: " + restarted +
" initialContact: " + initialContact +
" acceptNewTasks: " + acceptNewTasks + ")" +
" with responseId: " + responseId);
}详细省略。。。
2.4、执行任务
TaskTracker 申请到任务,从hdfs复制数据,启动任务launchTaskForJob(TaskInProgress tip, JobConf jobConf, rjob)
/**
* Kick off the task execution
*/
public synchronized void launchTask(RunningJob rjob) throws IOException {
if (this.taskStatus.getRunState() == TaskStatus.State.UNASSIGNED ||
this.taskStatus.getRunState() == TaskStatus.State.FAILED_UNCLEAN ||
this.taskStatus.getRunState() == TaskStatus.State.KILLED_UNCLEAN) {
localizeTask(task);
if (this.taskStatus.getRunState() == TaskStatus.State.UNASSIGNED) {
this.taskStatus.setRunState(TaskStatus.State.RUNNING);
}
setTaskRunner(task.createRunner(TaskTracker.this, this, rjob));
this.runner.start();
long now = System.currentTimeMillis();
this.taskStatus.setStartTime(now);
this.lastProgressReport = now;
} else {
LOG.info("Not launching task: " + task.getTaskID() +
" since it's state is " + this.taskStatus.getRunState());
}
}
2.5、更新任务进度与状态
MapTask里的run方法
TaskReporter 向TaskTracker报告任务状态与进度
@Override
public void run(final JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, ClassNotFoundException, InterruptedException {
this.umbilical = umbilical;
// start thread that will handle communication with parent
TaskReporter reporter = new TaskReporter(getProgress(), umbilical,
jvmContext);
reporter.startCommunicationThread();
boolean useNewApi = job.getUseNewMapper();
initialize(job, getJobID(), reporter, useNewApi);三、作业的调度机制
公平调度器(Fair Scheduler)
容量调度器(Capacity Scheduler Guide)
四、MapReduce 配置与调优
4.1、Map端
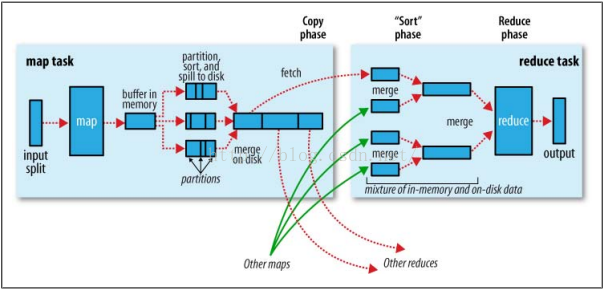
每个map有一个环形的缓冲区用于存储任务输出
try {
boolean kvfull;
do {
if (sortSpillException != null) {
throw (IOException)new IOException("Spill failed"
).initCause(sortSpillException);
}
// sufficient acct space
kvfull = kvnext == kvstart;
final boolean kvsoftlimit = ((kvnext > kvend)
? kvnext - kvend > softRecordLimit
: kvend - kvnext <= kvoffsets.length - softRecordLimit);
if (kvstart == kvend && kvsoftlimit) {
LOG.info("Spilling map output: record full = " + kvsoftlimit);
startSpill();
}
if (kvfull) {
try {
while (kvstart != kvend) {
reporter.progress();
spillDone.await();
}
} catch (InterruptedException e) {
throw (IOException)new IOException(
"Collector interrupted while waiting for the writer"
).initCause(e);
}
}
} while (kvfull);
} finally {
spillLock.unlock();
}
一旦内存缓冲区达到溢出写的阈值,就会新建一个写文件,在任务完成之前,溢出的写文件被合并成一个已分区且已排序的输出文件。
tip:
配置:io.sort.facotor 控制一次合并多少流,默认为10
指定combiner 就会在输出文件到写到磁盘之前运行,使map输出更紧凑
压缩输出能减少传给reduce的数据量,(将mapred.compress.map.output设置为true,并且使用压缩库mapred.map.output.compression.codec
4.2、Reduce
boolean isLocal = "local".equals(job.get("mapred.job.tracker", "local"));
if (!isLocal) {
reduceCopier = new ReduceCopier(umbilical, job, reporter);
if (!reduceCopier.fetchOutputs()) {
if(reduceCopier.mergeThrowable instanceof FSError) {
throw (FSError)reduceCopier.mergeThrowable;
}
throw new IOException("Task: " + getTaskID() +
" - The reduce copier failed", reduceCopier.mergeThrowable);
}
}
copyPhase.complete(); // copy is already complete
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
final FileSystem rfs = FileSystem.getLocal(job).getRaw();
RawKeyValueIterator rIter = isLocal
? Merger.merge(job, rfs, job.getMapOutputKeyClass(),
job.getMapOutputValueClass(), codec, getMapFiles(rfs, true),
!conf.getKeepFailedTaskFiles(), job.getInt("io.sort.factor", 100),
new Path(getTaskID().toString()), job.getOutputKeyComparator(),
reporter, spilledRecordsCounter, null)
: reduceCopier.createKVIterator(job, rfs, reporter);
// free up the data structures
mapOutputFilesOnDisk.clear();
sortPhase.complete(); // sort is complete
setPhase(TaskStatus.Phase.REDUCE);
statusUpdate(umbilical);
Class keyClass = job.getMapOutputKeyClass();
Class valueClass = job.getMapOutputValueClass();
RawComparator comparator = job.getOutputValueGroupingComparator();
if (useNewApi) {
runNewReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
} else {
runOldReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
}
done(umbilical, reporter);每个Map的时间完成的时间 不同,因些只要有一个任务完成,reduce任务就开始复制任务
tip:
设置mapred.reduce.parallel.copies (默认为5)改为reduce 并行复制线程
五、配置的调优
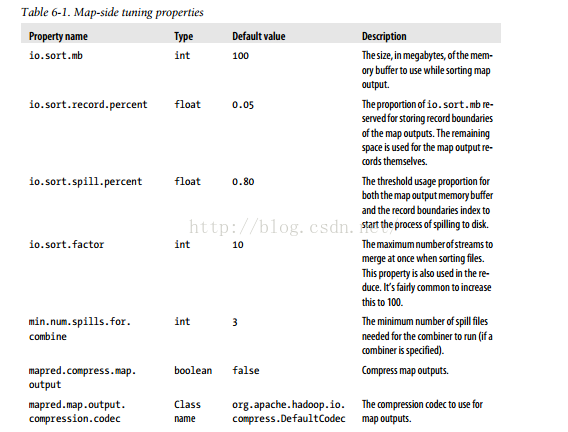
合理设置参数:
mapred.child.java.opts 运行map任务与reduce任务jvm
io.sort.* map端的参数属性,尽可能减少溢出写的次数
io.sort.mb 增加io.sort.mb 的值
mapred.inmem.merge.threashold 设置为0
mapred.job.reduce.input.buffer.percent 1.0或者更低
io.file.buffer.size 增加这个值
关闭推测执行
启用jvm重用
开启skipping mode














 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









