







 本文是关于Apache Mahout的自学指南,主要介绍了Mahout的API,包括协同过滤、SlopeOne、KNN等推荐算法的实现和测试,以及在不同场景下的适用性分析。
本文是关于Apache Mahout的自学指南,主要介绍了Mahout的API,包括协同过滤、SlopeOne、KNN等推荐算法的实现和测试,以及在不同场景下的适用性分析。
一、前言
mahout 是基于一个Hadoop的机器学习和数据挖掘的分布式计算框架。
目前Apache Mahout项目主要包括下面5个部分
频繁模式挖掘:挖掘数据中频繁出现的项集
聚类:将诸如文本、文档之类的数据分局相关的组
分类:利用已经存在的分类训练器,对未分类的文档进行分类
推荐引擎(协同过滤):获得用户的行为并从中发现用户可能喜欢的事物
频繁子项挖掘:利用一个项集(查询记录或购物目录)去识认经常一起出现的项目
二、Mahout API
协同过滤的Tasete相关的api,包名以org.apache.mahout.cf.taste
聚类算法,org.apache.mahout.clustering
分类算法,org.apache.mahout.classifier
频繁模式算法,org.apache.mahout.fpm
数学计算相关算法,org.apache.mahout.math
向量计算相关算法,org.apache.mahout.vectorizer
2.1单机下的基于物品的协同过滤算法
新建数据文件: item.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.5
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0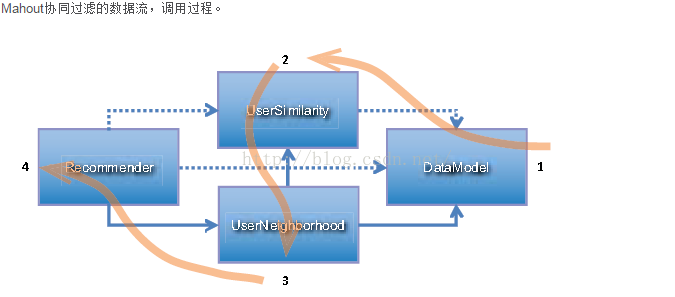
public class UserCF {
final static int NEIGHBORHOOD_NUM = 2;
final static int RECOMMENDER_NUM = 3;
public static void main(String[] args) throws IOException, TasteException {
String file = "datafile/item.csv";
DataModel model = new FileDataModel(new File(file));
UserSimilarity user = new EuclideanDistanceSimilarity(model);
NearestNUserNeighborhood neighbor = new NearestNUserNeighborhood(NEIGHBORHOOD_NUM, user, model);
Recommender r = new GenericUserBasedRecommender(model, neighbor, user);
LongPrimitiveIterator iter = model.getUserIDs();
while (iter.hasNext()) {
long uid = iter.nextLong();
List list = r.recommend(uid, RECOMMENDER_NUM);
System.out.printf("uid:%s", uid);
for (RecommendedItem ritem : list) {
System.out.printf("(%s,%f)", ritem.getItemID(), ritem.getValue());
}
System.out.println();
}
}
1). 系统环境:
- Win7 64bit
- Java 1.6.0_45
- Maven 3
- Eclipse Juno Service Release 2
- Mahout 0.8
- Hadoop 1.1.2
2). Recommender接口文件:
org.apache.mahout.cf.taste.recommender.Recommender.java

接口中方法的解释:
- recommend(long userID, int howMany): 获得推荐结果,给userID推荐howMany个Item
- recommend(long userID, int howMany, IDRescorer rescorer): 获得推荐结果,给userID推荐howMany个Item,可以根据rescorer对结构重新排序。
- estimatePreference(long userID, long itemID): 当打分为空,估计用户对物品的打分
- setPreference(long userID, long itemID, float value): 赋值用户,物品,打分
- removePreference(long userID, long itemID): 删除用户对物品的打分
- getDataModel(): 提取推荐数据
通过Recommender接口,我可以猜出核心算法,应该会在子类的estimatePreference()方法中进行实现。
3). 通过继承关系到Recommender接口的子类:

推荐算法实现类:
- GenericUserBasedRecommender: 基于用户的推荐算法
- GenericItemBasedRecommender: 基于物品的推荐算法
- KnnItemBasedRecommender: 基于物品的KNN推荐算法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









