






二分类逻辑回归
首先,我先展示下我逻辑回归的总体代码,如果有基础的同志需要的话,可以直接修改数据和参数拿去用呀:
library(lattice)
library(ggplot2)
library(caret)
library(e1071)
library(foreign)
library(survival)
library(MASS)
library(nnet)
library(epiDisplay)
library(pROC)
# 数据导入
data<-read.csv('E:/TestData/Number10.2.csv',header = T)
# 共线性诊断
XX<-cor(data[-1])
kappa(XX,exact = TRUE) # 也可以计算条件数kappa(X),k<100,说明共线性程度小;如果100<k<1000,则存在较多的多重共线性;若k>1000,存在严重的多重共线性。
# 划分训练集与测试集
train_sub = sample(nrow(data),7.5/10*nrow(data))
train_data = data[train_sub,]
test_data =data[-train_sub,]
# 模型构建
model6<-glm(mort~.,data=train_data,family = binomial)
summary(model6) #展示模型的
# 模型预测
pre_logistic<-as.numeric(predict(model6,newdata = test_data,type = "response")>0.5)
# 模型检验
conMat4<-confusionMatrix(factor(pre_logistic),factor(test_data$mort),positive="1")
logistic.display(model6) #输出OR值
# 绘制ORC曲线
roc1<-roc(test_data$mort,pre_logistic,plot=TRUE, print.thres=TRUE, print.auc=TRUE,levels = c(0,1),direction = "<")
# 检验线性假设是否成立
pre<-predict(model6,newdata = test_data,type = "response")
par(mfrow=c(2,2))
scatter.smooth(test_data[,2],log(pre/(1-pre)),cex=0.5)
scatter.smooth(test_data[,3],log(pre/(1-pre)),cex=0.5)
scatter.smooth(test_data[,4],log(pre/(1-pre)),cex=0.5)
scatter.smooth(test_data[,5],log(pre/(1-pre)),cex=0.5)
数据准备
在将数据导入R之前,根据自己的需求对数据进行清理。本例中,因变量为二分类,代表患者的出院和死亡,实验目的为预测患者死亡相关因素。因此,我们将死亡设置为1,住院设置为0。
R语言数据的导入支持很多格式,本例中导入的是csv格式,可以使用read.csv()函数,也可以使用read.table()函数;如果想要导入.xlsx文件,可以调用library(openxlsx)包,使用read.xlsx()函数,需要的同志可以自己去查。
本例中,首先我们导入数据
data<-read.csv('E:/TestData/Number10.2.csv',header = T)
#header = T 表明直接把文件中的标题行导入
数据导入效果展示如下(因为可能涉及到敏感信息,这里我将标题行抹去啦,实际导入进来是有标题行的)
在进行数据分析之前,我们需要检验一下自变量之间是否存在多重共线性:
data<-read.csv('E:/TestData/Number10.2.csv',header = T)
XX<-cor(data[-1])
kappa(XX,exact = TRUE) # 也可以计算条件数kappa(X),k<100,说明共线性程度小;如果100<k<1000,则存在较多的多重共线性;若k>1000,存在严重的多重共线性。
本例中,计算得出的k=2.857281,说明自变量间的共线程度较小,可以不予考虑。
然后我们按 7.5 : 2.5 的比例将数据划分为测试集和训练集
train_sub = sample(nrow(data),7.5/10*nrow(data))
train_data = data[train_sub,] # 训练集
test_data =data[-train_sub,] # 测试集
模型构建
R语言中二分类逻辑回归,可以调用glm()函数,具体实现如下:
model6<-glm(mort~.,data=train_data,family = binomial)
#实际模型建立的时候,可以采用mort~colname1+colname2+colname3的形式,mort ~代表将剩余所有的列作为自变量放入模型
summary(model6) #模型展示
结果如下:
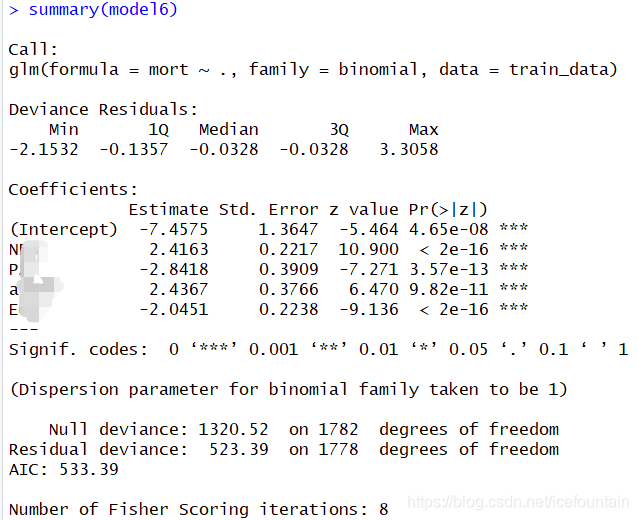
上图中,我们可以看到模型中,所有的变量P值均显著(若此步骤中有不显著的自变量,可以考虑将其剔除,然后重新构建模型)
模型构建成功以后,我们根据模型对测试集进行预测,将概率>0.5的归为死亡分类,概率<0.5的归为出院分类:
pre_logistic<-as.numeric(predict(model6,newdata = test_data,type = "response")>0.5)
模型检验
为了检验模型的预测效果,我们利用library(caret)包下的confusionMatrix()函数输出预测值和真实值的混淆矩阵,以及模型的准确率,敏感性和特异性:
conMat4<-confusionMatrix(factor(pre_logistic),factor(test_data$mort),positive="1")
logistic.display(model6) #输出OR值
#需要注意的是,confusionMatrix()函数要求输入变量是factor类型,在此,我们可以利用library(e1071)包下的factor()函数,或者as.factor()函数将数据强制转换为factor类型,如上述代码所示。
混淆矩阵输出结果展示如下:
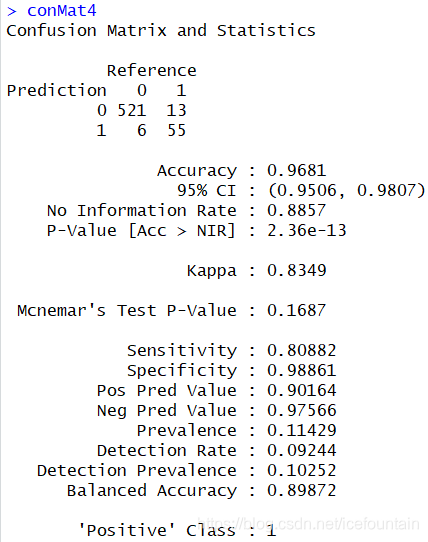
由上图可知,模型的准确率Accuracy为0.9681,敏感性Sensitivity为0.80882,特异性Specificity为0.98861。总体上来看,模型的敏感性较低,特异性高,可能存在的原因是数据不平衡,导致模型对数据量偏少的那个分类不够敏感。建议可以采用过采样,SMOTE平衡等方法对数据进行处理,具体实现方法,需要的同志可以自行百度。
除了输出混淆矩阵,也可以通过绘制ROC曲线,得到模型敏感性Sensitivity和特异性Specificity:
roc1<-roc(test_data$mort,pre_logistic,plot=TRUE, print.thres=TRUE, print.auc=TRUE,levels = c(0,1),direction = "<")
ROC曲线展示如下:
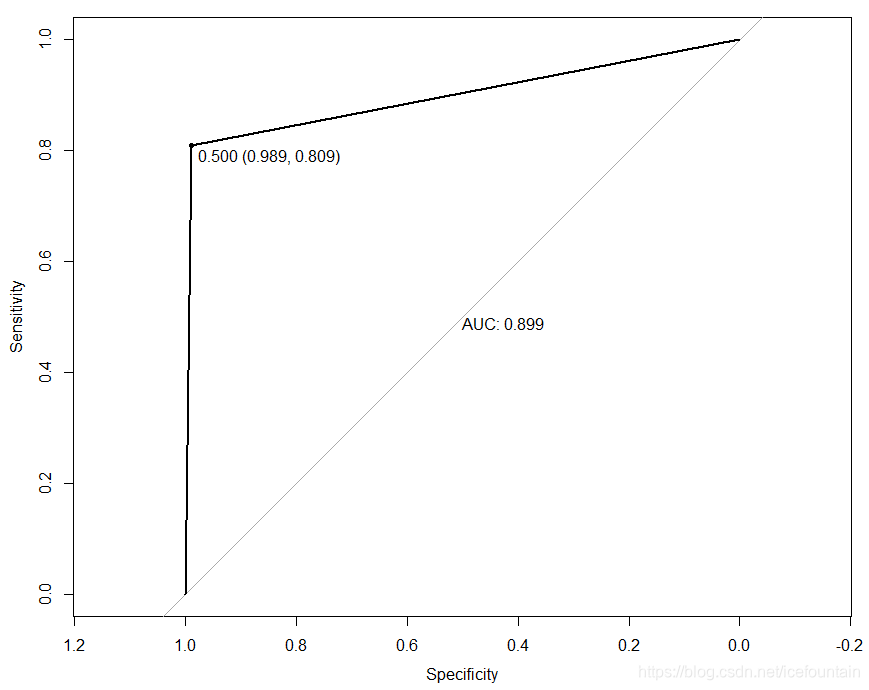
其实从上图我们可以看到,我这里ROC曲线中的AUC值和通过混淆矩阵输出的AUC是有偏差的(经评论大神指点,AUC和准确率不是一回事,我开始没搞明白,这样AUC和混淆矩阵中的Accuracy不一致就可以理解了~~)。
到此为止,二分类的逻辑回归模型就建立好啦。模型建立过程中做了很多工作,经常会出现模型拟合不好的情况,本来想记录的详细点,但文笔逻辑有限,发现过程中有些感想不是很容易写出来,最终还是只写了大概的过程。其实模型构建过程中,经常会因为数据问题或者操作不当出现各种各样的,难以言喻的错误,比如超过2个level的无序多分类自变量最好设置为哑变量(R语言逻辑回归中,将原始数据设置为A B C等用字母表示的数据,代入glm()模型中就会自动以第一个分类为参考将其设置为哑变量,有需求的同志可以自行百度);再有,如果有非线性关系,而且关系不明,可能需要generalized additive models,对应着gam()函数。如果非线性关系明确,就转化成线性的,用glm()函数:比如通过线性诊断发现某自变量的函数关系呈现二次型的,可以将该自变量转化为平方,再将新的变量代入模型重新构建(线性假设的检验我的总体代码中又给,有兴趣的同志可以自己尝试一下)。
线性检验出来的结果大概如下:
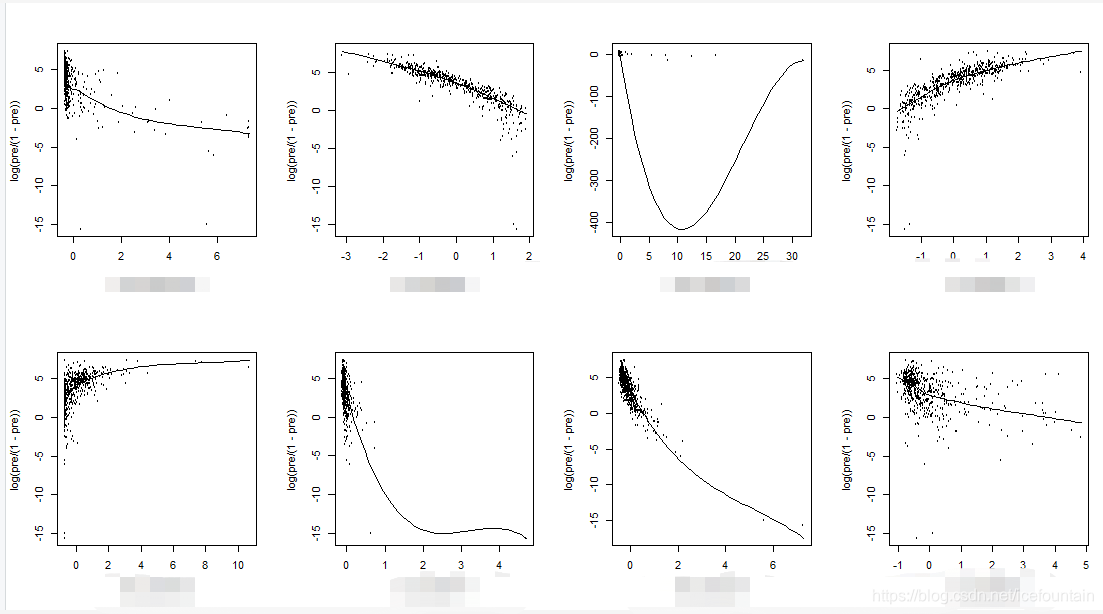
如上图中,图3很明显的大概是二次型的关系,因此可以将图3中的自变量化为其自身的二次型,然后再构建新的模型。
多分类逻辑回归
介绍完二分类回归,我们来看一下多分类的逻辑回归,其R语言实现过程与二分类回归大同小异。同样,我先展示下总体代码:
library(lattice)
library(ggplot2)
library(caret)
library(e1071)
library(nnet)
library(pROC)
# 数据准备
data<-read.csv('D:/多分类逻辑回归/iris.csv',header = T)
train_sub = sample(nrow(data),7.5/10*nrow(data))
train_data = data[train_sub,]
test_data =data[-train_sub,]
# 多元分类模型构建
train_data$class2<-relevel(as.factor(train_data$class),ref = "Iris-setosa") # 选择参考分类
mult.model<-multinom(class~A+B+C+D,data=train_data)
summary(mult.model)
# 系数显著性检验
z <- summary(mult.model)$coefficients/summary(mult.model)$standard.errors
p <- (1 - pnorm(abs(z), 0, 1))*2
p
# 相对危险度(相对危险风险比,或者也叫odds),与OR等价
exp(coef(mult.model))
# 利用head()函数得到模型的拟合值
# head(pp<-fitted(mult.model))
# 测试集结果预测
pre_logistic<-predict(mult.model,newdata = test_data)
# 预测正确百分比
# table(test_data$class,pre_logistic)
# 多分类混淆矩阵
conMat4<-confusionMatrix(factor(pre_logistic),factor(test_data$class))
本例中,多分类的逻辑回归利用的是library(nnet)包中的multinom()函数。该函数有两个特点:一是需要选择参考分类;二是不能计算系数的显著性(需要自己计算)。多元逻辑回归中,假设有3个分类,会以参考分类作为参考,构建两个分类模型。模型计算的是该条数据属于3个分类的概率,取概率最大的分类为最终分类。(详细的教程可以参考:多元分类详细教程)
在此不再对多元回归的代码做详细的解释。示例代码采用的数据是经典鸢尾花案例数据,需要的可以自行下载:鸢尾花数据集
总结:感觉就是,像算法啊,数据分析啊这种东西还是要自己动手写,只看或者只听,到自己动手的时候还是一团糟。所以,如果有机会,就多加练习吧!

















 2428
2428

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









